 自动化文件处理技巧
自动化文件处理技巧





 本文详细介绍自动化处理文件的各种方法,包括根据TXT文件搜索并复制指定文件、批量操作文件夹内文件、创建并命名新图片、按名称分类保存文件及统计文件数量,旨在提高工作效率。
本文详细介绍自动化处理文件的各种方法,包括根据TXT文件搜索并复制指定文件、批量操作文件夹内文件、创建并命名新图片、按名称分类保存文件及统计文件数量,旨在提高工作效率。
本文内容简介
在日常的工作中,尤其是在企业的文件处理过程中,经过会出现同质文件数量多、文件内容隐藏在七八层的文件夹内,亦或是同一文件夹内的文件进行分类处理,等等任务。少则几百,多则几千。文件的自动化批处理提出了更高的要求,解放双手,提升效率,缩短时间。
目录
二、复制指定文件夹内的文件,批操作(文件夹内文件名结构层次一致)
三、读取某一文件夹内的文件名,并创建新的图片,把名字复制给它
四、将一个文件夹内的文件,按照名字的不同,分批的保存到各自的文件夹内(归类)
总结
一、根据txt文件,搜索和复制指定文件
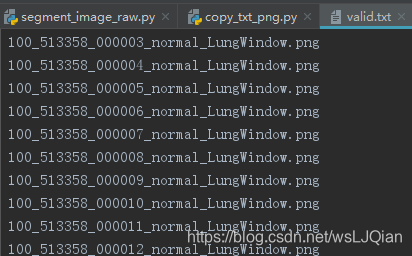
目的:是将如下txt文件内的png的文件名,找到所在别处文件的.xml文件,对应的将他复制保存到valid_xml文件夹内。如果txt内文件名存在,但是xml文件找不到,则跳过,继续找到,进行复制和保存。
说明:
valid.txt 内文件名,反应了该文件所包含位置的信息;
待复制的图片在TB_ct文件夹内,保存到输入文件夹的valid_xml文件夹内
__author__ = "lingjun"
# -*- coding:utf8 -*-
import os
import shutil
def main(input_path):
with open("valid.txt", "r") as f:
for line in f.readlines():
line = line.strip('\n') # 去掉列表中每一个元素的换行符
xml_file_path=input_path+"\\"+line.split("_")[0]+"\label\\"+line.split(".")[0]+".xml"
print('%s' % line.split(".")[0])
print(xml_file_path)
if os.path.exists(xml_file_path):
shutil.copy(xml_file_path, os.path.join(input_path, 'valid_xml'))
if __name__=='__main__':
input_path = "F:\TB_ct"
main(input_path)
这里就不做具体的展示了,步骤就是:
- 逐行读取valid.txt文件,提取每一行的内容
- 然后转化为xml文件的名称(因为两者对应文件只有文件类型后缀的不同)
- 最后,前一个文件名copy到制定文件夹呢。
二、复制指定文件夹内的文件,批操作(文件夹内文件名结构层次一致)
适合文件夹结构相似的文件批操作
__author__ = "lingjun"
# -*- coding:utf8 -*-
import os
import shutil
############################################################
# _pneumonia 肺炎原始图,复制指定文件夹
############################################################
def main_pneumonia(input_path,save_path):
for f_1 in os.listdir(input_path):
one_path=os.path.join(input_path, f_1)
#print(f_1)
for f_2 in os.listdir(one_path):
num_path = os.path.join(one_path, f_2)
#print(f_2)
for f_3 in os.listdir(num_path):
name_path = os.path.join(num_path, f_3)
#print(f_3)
if f_3 == "DCM":
for (path, dirs, files) in os.walk(name_path):
for filename in files:
all_target_file_path = os.path.join(name_path, filename)
print(all_target_file_path)
shutil.copy(all_target_file_path, os.path.join(save_path, "pneumonia_image"))
if __name__=='__main__':
input_path = "F:\image"
save_path = "F:/temp"
main_pneumonia(input_path, save_path)这里的内容和上节的内容存在相似之处,只是在获取待处理文件名上面有所区别。该处的步骤是:
- 逐层寻找制定名为“DCM”文件夹
- 遍历文件夹内的文件,获取每一个文件的完整文件path
- 最后,前一个文件名copy到文件夹pneumonia_image内。
PS:上面进入文件的方式有点蠢,在你需要对文件夹名进行判断的时候,就可以采用前面的方法。大多数情况下不需要逐层进入,可以直接采用如下的方式,直接拿到raw_path文件夹下所有枝叶的文件
for (path, dirs, files) in os.walk(raw_path):
for filename in files:
n+=1
print(filename)三、读取某一文件夹内的文件名,并创建新的图片,把名字复制给它
- create_lable_image(),得到矩形框的左上角和右下角坐标,绘制在新的空白图片上;
- create_label_zero_image(),创建空白图片。
__author__ = "lingjun"
# -*- coding:utf8 -*-
import os
import xml.etree.ElementTree as ET
import cv2
import numpy as np
############################################################
# 1 Create Segment Label Image,rectangle(x,y,x+w,y+h)
############################################################
def creat_label_image(xmin_list,ymin_list,xmax_list,ymax_list,width,height, filename):
img = np.zeros([width, height, 1], np.uint8)
for i in range(len(xmin_list)):
img[ymin_list[i]:ymax_list[i], xmin_list[i]:xmax_list[i],:] = 255
cv2.imwrite("./label_raw/" + filename.split('.')[0, 1]+'_label.png',img)
cv2.destroyAllWindows()
############################################################
# 2 Create Segment Label Image,空白图
############################################################
def creat_label_zero_image(width, height, filename):
img = np.zeros([width, height, 1], np.uint8)
name1, name2, _=filename.split('.')
new_path = "F:/image_gen/label_raw/" + name1 + "_" + name2 + '.png'
print(new_path)
cv2.imwrite(new_path, img)
cv2.destroyAllWindows()
############################################################
# 3 Create Image on origin_image,rectangle(x,y,x+w,y+h)
############################################################
def draw_rectangle_test(xmin_list, ymin_list, xmax_list, ymax_list, filename, xml_file_path):
png_file_path_0=xml_file_path.split(".")[0]
png_file=png_file_path_0.split('\\')[-1]+".png"
png_path="F:/TB_ct/"+png_file_path_0.split('\\')[2]+"/LungWindow/"+png_file
print(png_path)
img = cv2.imread(png_path,cv2.IMREAD_UNCHANGED)
for i in range(len(xmin_list)):
cv2.rectangle(img, (xmin_list[i], ymin_list[i]), (xmax_list[i], ymax_list[i]), (0, 255, 0), 1)
#cv2.rectangle(img, (30, 160), (360, 260), (0, 0, 255), 4)
# cv2.namedWindow("AlanWang")
# cv2.imshow('AlanWang', img)
# cv2.waitKey(1000)
cv2.imwrite("./label_raw/" + filename.split('.')[0] + '_label.png', img)
cv2.destroyAllWindows()
def main_negative(input_path):
for (path, dirs, files) in os.walk(input_path):
for filename in files:
all_image_file_path = os.path.join(input_path, filename)
print(all_image_file_path)
# shutil.copy(all_image_file_path, os.path.join(input_path, 'all_class_image'))
creat_label_zero_image(512, 512, filename)
if __name__=='__main__':
input_path = r"F:\image_gen"
main_negative(input_path)这里的内容和前两节的内容较为不同,但都是对文件进行的操作。此处是获取xml文件的名字和读取到文件内矩形框坐标(此处内容在第四节介绍)--->然后分别创建空白图像--->在该空白图像上绘制矩形框/空白图/原图上绘制矩形框--->把源文件名赋予新的图片,形成一一对应关系。
四、将一个文件夹内的文件,按照名字的不同,分批的保存到各自的文件夹内(归类)
整理前的文件排布,如下所示:
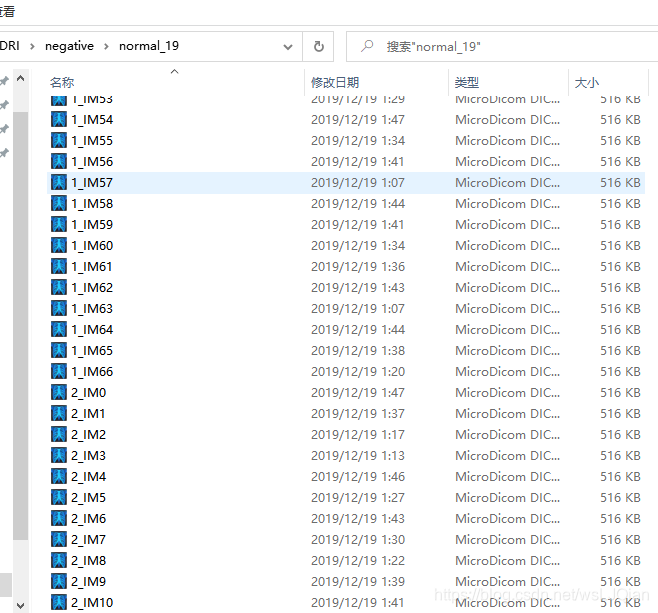
def name_num():
raw_path = r"E:\\normal_19"
list_name = []
for (path, dirs, files) in os.walk(raw_path):
for filename in files:
new_Documentname = "normal" +filename.split("_")[0]
newpath=os.path.join(r"E:\nodule_lung\LIDC-IDRI\negative\normal", new_Documentname)
if os.path.exists(newpath) == False:
os.makedirs(newpath)
print(os.path.join(path, filename))
print(os.path.join(newpath, filename))
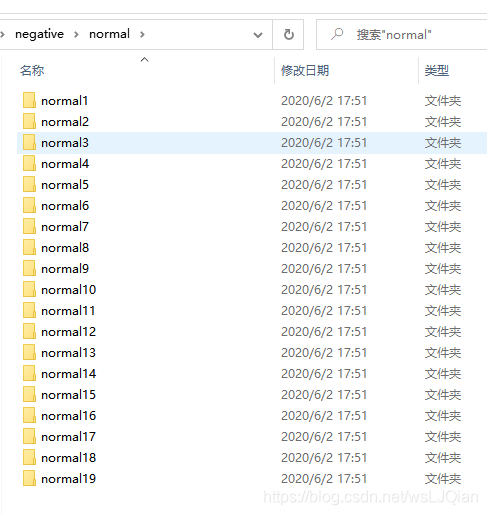
shutil.copy(os.path.join(path, filename), os.path.join(newpath, filename))整理后的文件排布形式:
对文件的操作,还有很多的,例如删除操作:
附录
os.unlink(mark_pne_path) 实现对文件的删除
文件夹内的文件名,组成的list
ls=os.listdir(target_path)复制文件、移动文件操作:
实现将文件依次移动到TB_fp的文件夹内
shutil.move(file_path, os.path.join(save_path, 'TB_fp'))
实现将文件依次复制到TB_fp的文件夹内
shutil.copy(png_path, os.path.join(save_path, 'positive_raw')获取文件名后缀操作:
a='./doc/15/doc_15_1.2.jpg'
In [10]: suffix = os.path.splitext(a)
In [11]: suffix
Out[11]: ('./doc/15/doc_15_1.2', '.jpg')后面类似的很有很多,这个需要时候,自己百度查查即可。
五、统计文件夹内的数量
for f_1 in os.listdir(mask_path):
one_path = os.path.join(mask_path, f_1)
dcm_list = os.listdir(one_path)
if len(dcm_list) > 16:
pass
else:
print(one_path)总结
本文也不能尽善尽美的把所有对文件的操作给整理出来,主要是给新入门的小伙伴一个指引,知道原来还有这样一些第三方库,可以用于对文件,或者文件夹进行增删改查的操作。
我就记得我最早期学习时候,都不知道这些库,甚至自己手动改文件名,也是骚操作到家了。抛砖引入,如有错误地方,欢迎指出。



















 256
256

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











