



 本文探讨了stride卷积对比池化的优劣,relu激活函数的特点,MobileNet为何适用于移动端,以及不同存储区的区别。深入解析了深度学习中关键概念,如卷积神经网络的参数优化与计算效率提升。
本文探讨了stride卷积对比池化的优劣,relu激活函数的特点,MobileNet为何适用于移动端,以及不同存储区的区别。深入解析了深度学习中关键概念,如卷积神经网络的参数优化与计算效率提升。
1.采用stride卷积去替代池化层,与原本的池化操作,有什么利弊吗?
答:池化只是简单的在空间信息上降维,有比较明显的信息损失,用stride卷积同时在空间和特征维上进行非线性映射,效果更好 。
2.relu优缺点
优点:relu不需要想sigmoid函数一样进行复杂的指数运算,是的其收敛速度非常快。并且,relu函数的导数为1,不会导致梯度变小,因此一定程度上解决了梯度消失的问题。
缺点:在训练过程中relu神经元比较脆弱,容易出现神经元“死亡”。如果神经元接收到一个非常大的梯度流之后,这个神经元的参数极有可能变成一个很大的负值,在之后的正向传播时,所有的输出都是0,也就意味着这个神经元对之后的任何数据都不再有激活现象。因此,在使用relu作为激活函数时,最后不要使用太大的学习率。
3.MobileNet为什么能应用在手机上,运行速度那么快?
MobileNet 网络主要的设计目标是——在保证一定的识别精度情况下,尽可能减少网络规模(参数量、计算量);
原因:单通道卷积以及1*1卷积,这样做的好处是把参数大大降低,计算量也大大降低;
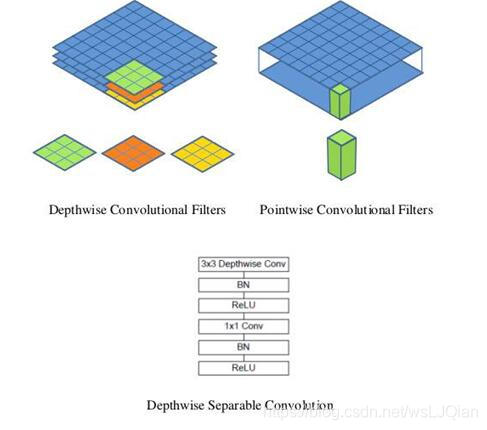
这种操作是相当有效的,在imagenet 1000类分类任务中已经超过了InceptionV3的表现,而且也同时减少了大量的参数,我们来算一算,假设输入通道数为3,要求输出通道数为256,两种做法:
1.直接接一个3×3×256的卷积核,参数量为:3×3×3×256 = 6,912
2.DW操作,分两步完成,参数量为:3×3×3 + 3×1×1×256 = 795,又把参数量降低到九分之一!
因此,一个depthwise操作比标准的卷积操作降低不少的参数量,同时得到更好的效果,因为它对每一个通道都进行了学习(每个通道对应一个不同的过滤器),而不是所有通道对应同一个过滤器,得到的特征质量更佳!
简单复述一下思想:Depthwise Conv是指只有Spatial Weight的卷积,而没有Channel关系,因此每一个filter只对一个channel计算Conv,大大减少了计算量和参数量;而Channel之间的feature融合通过后面的1*1常规卷积来完成;在Relu之前都带上BN层。
4.存储问题
全局变量存储在静态存储区,位置是固定的。局部变量是在栈空间,栈地址是不固定的;
栈:就是那些由编译器在需要的时候分配,在不需要的时候自动清楚的变量的存储区。里面的变量通常是局部变量、函数参数等
堆:就是那些由new分配的内存块,他们的释放编译器不去管,由我们的应用程序去控制,一般一个new就要对应一个delete。如果程序员没有释放掉,那么在程序结束后,操作系统会自动回收。
自由存储区:就是那些由malloc等分配的内存块,他和堆是十分相似的,不过它是用free来结束自己的生命的。
全局存储区(静态存储区):全局变量和静态变量的存储是放在一块的,初始化的全局变量和静态变量在一块区域, 未初始化的全局变量和未初始化的静态变量在相邻的另一块区域。程序结束后有系统释放。
常量存储区:这是一块比较特殊的存储区,他们里面存放的是常量,不允许修改。
5.题目
6.题目
-
int fun(int a){ a^=(1<<5)-1; return a; } fun(21)运行结果是()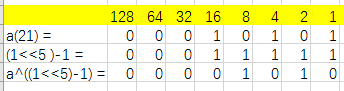
-
list=[[]]*3 list[0].append(2) print(list) 打印: [[2], [2], [2]] -
list=[[]]*3 print(list) list[0].append(2) print(list) 打印: [[], [], []] [[2], [2], [2]]list=[[],[]]*3 print(list) list[0].append(2) print(list) 打印: [[], [], [], [], [], []] [[2], [], [2], [], [2], []]


















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











