




 本文介绍了如何在PyTorch中结合GradualWarmupScheduler实现学习率的预热策略,分别展示了StepLR和CosineAnnealing两种模式,并详细解释了关键参数如gamma、step_size和total_epoch的作用。通过代码实例演示了如何使用这些方法调整模型训练过程中的学习率变化。
本文介绍了如何在PyTorch中结合GradualWarmupScheduler实现学习率的预热策略,分别展示了StepLR和CosineAnnealing两种模式,并详细解释了关键参数如gamma、step_size和total_epoch的作用。通过代码实例演示了如何使用这些方法调整模型训练过程中的学习率变化。
在pytorch中,torch.optim.lr_scheduler是引用变化学习率最常用的方法。但是pytorch官方暂未提供关于预热warm式的学习率优化方式。
于是,借鉴GitHub牛人的内容:https://github.com/ildoonet/pytorch-gradual-warmup-lr,在这里进行记录。
1.StepLR_Warm
import torch
from torch.optim.lr_scheduler import StepLR, ExponentialLR
from torch.optim.sgd import SGD
from warmup_scheduler import GradualWarmupScheduler
import matplotlib.pyplot as plt
def draw_plot(x_list, y_list, title_name):
plt.plot(x_list, y_list, label='lr')
plt.xlabel('x', fontsize=15)
plt.ylabel('y', fontsize=15)
plt.title(title_name, fontsize=15)
plt.legend()
plt.grid(linestyle='-.')
plt.savefig(title_name+".png")
if __name__ == '__main__':
model = [torch.nn.Parameter(torch.randn(2, 2, requires_grad=True))]
optim = SGD(model, 0.02)
# scheduler_warmup is chained with schduler_steplr
scheduler_steplr = StepLR(optim, step_size=30, gamma=0.1)
scheduler_warmup = GradualWarmupScheduler(optim, multiplier=1, total_epoch=30, after_scheduler=scheduler_steplr)
# this zero gradient update is needed to avoid a warning message, issue #8.
optim.zero_grad()
optim.step()
lr_list=[]
for epoch in range(1, 100):
scheduler_warmup.step()
print(epoch, scheduler_warmup.get_last_lr())
optim.step() # backward pass (update network)
lr_list.append(optim.param_groups[0]['lr'])
draw_plot([i for i in range(len(lr_list))], lr_list, 'lr')
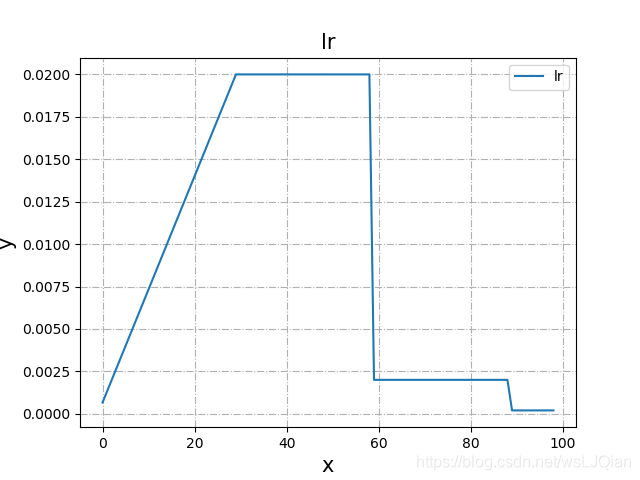
学习率变化入下,参数稍微记录一下:
- gama:衰减系数
- step_size:total_epoch后,每step_size就学习率*gama
- total_epoch:预热的最大epoch,之前我误把它和T_max弄混淆了,这里记录下
2.Cosine_Warm
import torch
from torch.optim.lr_scheduler import StepLR, ExponentialLR, CosineAnnealingLR
from torch.optim.sgd import SGD
from warmup_scheduler import GradualWarmupScheduler
import matplotlib.pyplot as plt
def draw_plot(x_list, y_list, title_name):
plt.plot(x_list, y_list, label='lr')
plt.xlabel('x', fontsize=15)
plt.ylabel('y', fontsize=15)
plt.title(title_name, fontsize=15)
plt.legend()
plt.grid(linestyle='-.')
plt.savefig(title_name+".png")
lr_list=[]
if __name__ == '__main__':
model = [torch.nn.Parameter(torch.randn(2, 2, requires_grad=True))]
optim = SGD(model, 0.1)
# scheduler_warmup is chained with schduler_steplr
# scheduler_steplr = StepLR(optim, step_size=20, gamma=0.1)
scheduler_steplr = CosineAnnealingLR(optim, T_max=70)
scheduler_warmup = GradualWarmupScheduler(optim, multiplier=1, total_epoch=10, after_scheduler=scheduler_steplr)
# this zero gradient update is needed to avoid a warning message, issue #8.
optim.zero_grad()
optim.step()
for epoch in range(1, 70):
scheduler_warmup.step()
print(epoch, scheduler_warmup.get_last_lr())
optim.step() # backward pass (update network)
lr_list.append(optim.param_groups[0]['lr'])
draw_plot([i for i in range(len(lr_list))], lr_list, 'lr')
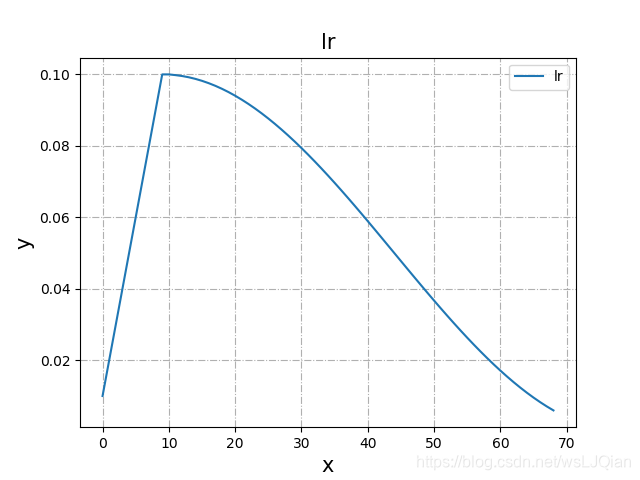
学习率变化入下,参数稍微记录一下:
- T_max:最大epoch数
- total_epoch:预热的最大epoch,之前我误把它和T_max弄混淆了,这里记录下




















 339
339

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











