




 该博客介绍了Facebook AI的研究论文——DETR,它使用Transformer架构实现端到端的目标检测。DETR摒弃了传统检测器中的锚框和NMS步骤,直接从输入图像到检测框进行预测。内容包括论文链接、PPT、B站视频教程,以及实例代码,用于实例化分割和检测。代码展示了如何处理图像、转换坐标、绘制边界框,并提供了基于DETR的推断流程。
该博客介绍了Facebook AI的研究论文——DETR,它使用Transformer架构实现端到端的目标检测。DETR摒弃了传统检测器中的锚框和NMS步骤,直接从输入图像到检测框进行预测。内容包括论文链接、PPT、B站视频教程,以及实例代码,用于实例化分割和检测。代码展示了如何处理图像、转换坐标、绘制边界框,并提供了基于DETR的推断流程。
论文标题:End-to-End Object Detection with Transformers
论文官方地址:https://ai.facebook.com/research/publications/end-to-end-object-detection-with-transformers
个人整理的PPT(可编辑),下载地址:DETR学习分享.pptx
B站视频学习(推荐):DETR论文精读
实例化分割的检测代码,进行了汇总,希望对你的实验有帮助。
# coding=utf-8
'''
DE⫶TR: End-to-End Object Detection with Transformers
instance segmentation inference
'''
import cv2
from PIL import Image
import numpy as np
import os
import time
from tqdm import tqdm
from PIL import Image, ImageFont, ImageDraw
import torch
from torch import nn
import torch.nn.functional as F
# from torchvision.models import resnet50
import torchvision.transforms as T
from hubconf import detr_resnet50, detr_resnet50_panoptic
import json
from imantics import Mask
torch.set_grad_enabled(False)
import base64
from PIL import Image
import io
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
print("[INFO] 当前使用{}做推断".format(device))
# 图像数据处理
normalize = T.Compose([
T.ToTensor(),
T.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])
])
transform = T.Compose([
T.Resize(800),
normalize,
])
# 将xywh转xyxy
def box_cxcywh_to_xyxy(x):
x_c, y_c, w, h = x.unbind(1)
b = [(x_c - 0.5 * w), (y_c - 0.5 * h),
(x_c + 0.5 * w), (y_c + 0.5 * h)]
return torch.stack(b, dim=1)
# 将0-1映射到图像
def rescale_bboxes(out_bbox, size):
img_w, img_h = size
b = box_cxcywh_to_xyxy(out_bbox)
b = b.cpu().numpy()
b = b * np.array([img_w, img_h, img_w, img_h], dtype=np.float32)
return b
def contour_label(json_path, image):
with open(json_path, 'r', encoding='utf-8') as fp:
data = json.load(fp) # 加载json文件
for shapes in data['shapes']:
points = shapes['points']
label = shapes['label']
contour = np.array([points])
contour = np.trunc(contour).astype(int)
#print(contour, type(contour))
#print("***")
cv2.drawContours(image, [contour], 0, (0, 0, 255), 3) # cv2.FILLED填充
cv2.putText(image, label, (int(contour[0][0][0]) - 15, int(contour[0][0][1]) - 15),
cv2.FONT_HERSHEY_SIMPLEX, 3, (255, 0, 0), 5, cv2.LINE_AA)
return image
# 中文和序号的对照(不用关心)
label_dict = {'肺气肿': '10', '纤维增值灶': '11'}
label_dictCode_Lesion = {value: key for key, value in label_dict.items()}
LABEL = ['NA', '6', '503']
# plot box by opencv
def plot_result(pil_img, prob, boxes, name, save_name=None, save_mask=False, imshow=False, imwrite=False):
opencvImage = cv2.cvtColor(np.array(pil_img), cv2.COLOR_RGB2BGR)
# print(prob)
# print("-------------------------------")
# print(boxes)
if len(prob) == 0:
print("[INFO] NO box detect !!! ")
if imwrite:
if not os.path.exists("./result/pred_no"):
os.makedirs("./result/pred_no")
# cv2.imwrite(os.path.join("./result/pred_no",save_name),opencvImage)
return
print('Find {} box'.format(len(prob)))
for p, (xmin, ymin, xmax, ymax) in zip(prob, boxes):
cl = p.argmax()
label_text = '{}: {}%'.format(label_dictCode_Lesion[LABEL[cl]], round(p[cl] * 100, 2))
cv2.rectangle(opencvImage, (int(xmin), int(ymin)), (int(xmax), int(ymax)), (255, 255, 0), 2)
# cv2.putText(opencvImage, label_text, (int(xmin)+10, int(ymin)+30), cv2.FONT_HERSHEY_SIMPLEX, 1, (0, 0, 255), 2)
# cv2.putText 不支持中文所以这里换一种方法
fontpath = "simsun.ttc" # 宋体字体文件
font_1 = ImageFont.truetype(fontpath, 15) # 加载字体, 字体大小
img_pil = Image.fromarray(opencvImage)
draw = ImageDraw.Draw(img_pil)
draw.text((int(xmin) + 10, int(ymin) - 30), label_text, font=font_1, fill=(0, 0, 255))
opencvImage = np.array(img_pil)
if save_mask:
opencvImage = contour_label(r'./result/json/'+name, opencvImage)
if imshow:
cv2.imshow('detect', opencvImage)
cv2.waitKey(0)
if imwrite:
if not os.path.exists("./result/pred"):
os.makedirs('./result/pred')
cv2.imwrite('./result/pred/{}'.format(save_name), opencvImage)
def contour_label(json_path, image):
with open(json_path, 'r', encoding='utf-8') as fp:
data = json.load(fp) # 加载json文件
for shapes in data['shapes']:
points = shapes['points']
label = shapes['label']
contour = np.array([points])
contour = np.trunc(contour).astype(int)
#print(contour, type(contour))
#print("***")
cv2.drawContours(image, [contour], 0, (0, 255, 255), 1) # cv2.FILLED填充
return image
def base64encode_img(image_path):
src_image = Image.open(image_path)
output_buffer = io.BytesIO()
src_image.save(output_buffer, format='JPEG')
byte_data = output_buffer.getvalue()
base64_str = base64.b64encode(byte_data).decode('utf-8')
return base64_str
def save_json(img_fullName, class_list, polygons_list, height, width, save_json_path):
coor_list=[]
label_list=[]
A = dict()
listbigoption = []
print('0:',len(class_list))
print('1:',len(polygons_list))
for i in range(len(polygons_list)):
listobject={}
c1 = class_list[i]
#print("len=",len(polygons_list[i]))
#print(polygons_list[i])
if polygons_list[i]!=[]:
if len(polygons_list[i])>1:
max_area=0
for j in range(len(polygons_list[i])):
#print(i,j)
polygon = polygons_list[i][j]
area = cv2.contourArea(polygon)
if area>max_area:
max_area=area
points_polygon = polygon.tolist()
else:
points_polygon = polygons_list[i][0].tolist()
new_contour=[]
if len(points_polygon) > 300:
merge = 25
elif len(points_polygon) > 200:
merge = 20
elif len(points_polygon) > 100:
merge = 15
elif len(points_polygon) > 50:
merge = 10
elif len(points_polygon) > 20:
merge = 6
else:
merge = 4
points_polygon = [points_polygon[k] for k in range(0,len(points_polygon),merge)]
#print(polygon)
listobject['points'] = points_polygon
listobject['label'] = label_dictCode_Lesion[LABEL[c1]]
listobject['group_id'] = None
listobject['shape_type'] = 'polygon'
listobject['flags'] = {}
listbigoption.append(listobject)
A['version'] = "4.5.5"
A['imageData'] = base64encode_img(img_fullName)
A['imagePath'] = os.path.basename(img_fullName)
A['shapes'] = listbigoption
A['flags'] = {}
A['imageHeight'] = height
A['imageWidth'] = width
with open(save_json_path + "json/" + os.path.basename(img_fullName).replace(".png", ".json"), 'w') as f:
json.dump(A, f, indent=2, ensure_ascii=False)
# 单张图像的推断
def detect(im, model, transform, img_fullName, prob_threshold=0.5):
# mean-std normalize the input image (batch-size: 1)
img = transform(im).unsqueeze(0)
# demo model only support by default images with aspect ratio between 0.5 and 2
# if you want to use images with an aspect ratio outside this range
# rescale your image so that the maximum size is at most 1333 for best results
assert img.shape[-2] <= 1600 and img.shape[
-1] <= 1600, 'demo model only supports images up to 1600 pixels on each side'
# propagate through the model
img = img.to(device)
start = time.time()
outputs = model(img)
# box_cls = outputs["pred_logits"]
# box_pred = outputs["pred_boxes"]
# mask_pred = outputs["pred_masks"]
# results = inference(box_cls, box_pred, mask_pred, im.size)
# print('results:', results)
# keep only predictions with 0.7+ confidence
# print(outputs['pred_logits'].softmax(-1)[0, :, :-1])
probas = outputs['pred_logits'].softmax(-1)[0, :, :-1]
keep = probas.max(-1).values > prob_threshold
end = time.time()
probas = probas.cpu().detach().numpy()
keep = keep.cpu().detach().numpy()
# convert boxes from [0; 1] to image scales
bboxes_scaled = rescale_bboxes(outputs['pred_boxes'][0, keep], im.size)
print('pred-box0:',outputs['pred_boxes'].shape)
print('pred-box:',outputs['pred_boxes'][0, keep].shape)
print('im.size:', im.size)
# masks=outputs['pred_masks'][0, keep]
# print('class:',probas[keep])
# print('masks:', masks)
mask_pred = outputs['pred_masks']
mask = F.interpolate(mask_pred, size=im.size, mode='bilinear', align_corners=False)
print('pred-mask0:',mask.shape)
mask = mask[0, keep].sigmoid() > 0.5
print('pred-mask:',mask.shape)
draw_masks = np.array(mask.cpu())
polygons =[Mask(mask).polygons().points for mask in draw_masks]
class_list =[p.argmax() for p in probas[keep]]
print(len(polygons))
if len(class_list)>0:
save_json(img_fullName, class_list, polygons, im.size[0], im.size[1], save_json_path='./result/')
return probas[keep], bboxes_scaled, end - start
if __name__ == "__main__":
# detr = DETRdemo(num_classes=3+1)
detr = detr_resnet50(pretrained=False, num_classes=81 + 1, mask=True).eval() # <------这里类别需要+1
state_dict = torch.load('./outputs/segm_model/checkpoint.pth') # <-----------修改加载模型的路径
detr.load_state_dict(state_dict["model"])
detr.to(device)
png_path = "./database/data/fold_47/raw"
files = os.listdir(png_path)
for file in tqdm(files):
im = Image.open(os.path.join(png_path, file)).convert('RGB')
scores, boxes, waste_time = detect(im, detr, transform, os.path.join(png_path, file), prob_threshold=0.5)
# scores, boxes, waste_time = detect(im, detr, transform)
# print('scores:',scores)
plot_result(im, scores, boxes, file.replace('png', 'json'), save_name=file, save_mask=True, imshow=False, imwrite=True)
print("[INFO] {} time: {} done!!!".format(file, waste_time))
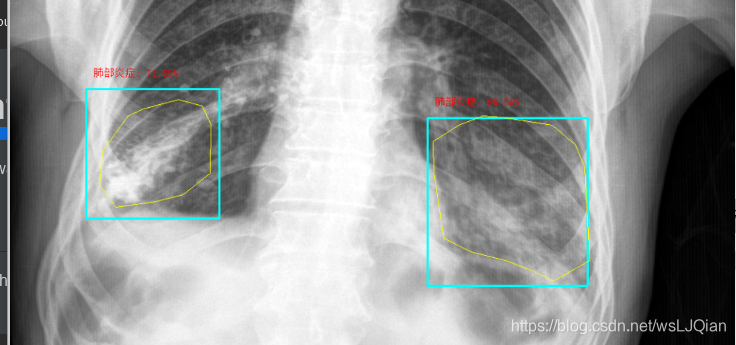
预测结果打印如下:


















 588
588

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











