




目录
补充10:将文件夹内的数据,依据文件名的一致性,分别保存到对应的文件夹
1.检查该元素,是否在目标list中:
list_samename=['ChenZhangWei', 'HuangXiaoDon', 'YuYunYuan', 'ZhangWei', 'WangXiao']
int_path = 'F:\\3人TB\\dcmraw'
for root, dirs, files in os.walk(int_path):
for filename in files: # 遍历所有文件
if filename in list_samename:
file_path = os.path.join(root, filename)
print(file_path)结果:list_samename中存在与filename一模一样的元素,就把filename的完整路径打印出来
2. try···except跳出错误的操作
在日常的处理中,经常遇见不满足操作条件,而出现错误的现象。出现错误,就会主动中断程序,跳出错误提示;
有时候我们并不需要系统那么的热心,自动的帮我们终止执行程序,此时,我们选择,当遇见错误的时候,执行另一段操作,使得程序继续执行
try:
ds = pydicom.dcmread(os.path.join(root, filename), force=True) # 读取dcm
patient_name = str(ds.PatientName)
patient_slicenum = str(ds.InstanceNumber)
slice_thickness = str(round(ds.SliceThickness,3))
print(slice_thickness)
new_filename = filename.split(".dcm")[0]+"_"+slice_thickness+".dcm"
#print("{}***{}***{}".format(patient_name, patient_slicenum, slice_thickness))
os.rename(os.path.join(root, filename), os.path.join(root, new_filename))
print(new_filename)
except:
print("######################################################" + filename)
continue上面这段是干这么一件事情:读取dcm文件(一种医学图像存储格式),取得内部参数,对它重命名
- 读取dcm文件
- 获取dcm文件内的PatientName、InstanceNumber、SliceThickness三个参数
- 组合新的文件名
- os.rename重命名
上面执行的这个过程,很可能会出现一些问题,比如
- 读取dcm文件不存在
- dcm文件被破坏,不存在PatientName参数,或者缺失
- 组合新文件名时候出现越界等等人为错误
- os.rename重命名失败
只要上面可能出现的错误发生,就会自动的跳出try部分,进入except操作,并continue进入下一轮的循环
3.统计list(列表)中相同元素的个数
任务:这里的字符串名为list_name,打印列表中相同元素数量大于1的名称和数量
def re_add_name():
a_dict = {}
list_name=["annan","annan","hh","mam","mam"]
for i in list_name:
if list_name.count(i)>1:
a_dict[i]=list_name.count(i)
print(a_dict)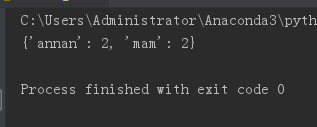
4.对文件进行复制、移动、删除、重命名操作
import shutil
# 复制操作
# shutil.copy(原文件完整path,保存到的文件夹完整path)
shutil.copy(os.path.join(root, filename), os.path.join(save_path, '85测试出错原图'))
# 移动操作
shutil.move(os.path.join(root, filename), os.path.join(save_path, '85测试出错原图'))
# 实现对文件的删除
os.unlink(mark_pne_path)
# 对文件进行重命名
os.rename(os.path.join(root, filename), os.path.join(root, new_filename))更多详情可参照这里:https://blog.youkuaiyun.com/wsLJQian/article/details/92832695
5.读取txt文件,并一行一行的显示出来
这里如题,不做过多的解释,就是把txt文件内容一行一行的读取显示出来,再干点啥自己决定吧
def readTXT():
list_name=[]
for line in open("./list_not_predOK.txt"):
print(line.strip())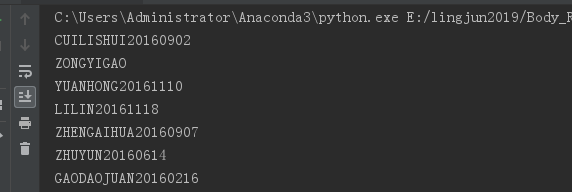
有人该问啦,为什么不直接采用print(line)形式,这是由于每一行都是存在一个换行符的。
这里用到了strip()方法,如下描述
Python strip() 方法用于移除字符串头尾指定的字符(默认为空格或换行符)或字符序列。
注意:该方法只能删除开头或是结尾的字符,不能删除中间部分的字符。
6.把字符串string中带有指定字符的删除
一堆字符串如下所示,此时不想让下面的字符串中包含IM,也就是把IM这个字符给剔除了,该怎么做呢?这里用到find查询的操作。
xiaobai_CVIMggoo1.png,xiaobai_CVIMggoo2.png,xiaobai_CVIMggoo2.png,xiaobai_CVIMggoo2.png···
def Findname():
list_name=["xiaobai_CVIMggoo1.png","小白_CVIMggoo2.png","xiaobai_CVIMggoo2.png","小白_CVIMggoo2.png"]
for name in list_name: # 遍历所有文件
print(name)
pos = name.find("IM") # 把文件带有_label的字符删除
print("pos_num:", pos)
if (pos == -1):
continue
newname = name[0:pos] + name[pos+2:-1]+"png"
print(newname)
print("***********")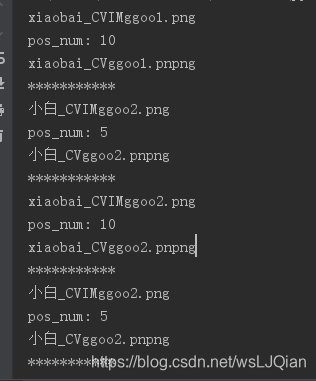
注释:这里的pos返回的是第一次发现目标字符的首位置
7.将字符串,拆分成字母和数字形式
话不多说了,看图,具体的详情可参考这里:https://blog.youkuaiyun.com/wsLJQian/article/details/100987574
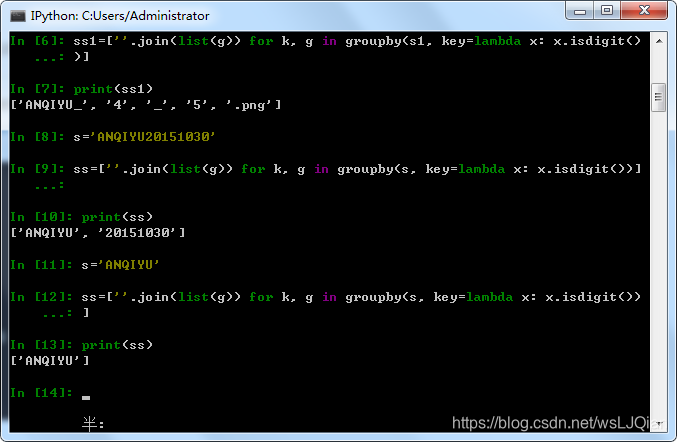
其中一个点值得注意,也是个陌生的词---groupby:
pandas提供了一个灵活高效的groupby(Group By: split-apply-combine)功能,它使你能以一种自然的方式对数据集进行切片、切块、摘要等操作。根据一个或多个键(可以是函数、数组或DataFrame列名)拆分pandas对象。计算分组摘要统计,如计数、平均值、标准差,或用户自定义函数。
举例1.列表根据gb这个函数的条件,把list进行了重新的分类
from itertools import groupby
lst=[2,8,6,9,15,16,20,30,65,123,95,12]
def gb(num):
if num<10:
return 'less'
elif num>50:
return 'great'
else:
return 'middle'
print([(k,list(g)) for k,g in groupby(sorted(lst),key=gb)])
举例2.把list拆分成相互连续的几个list
from itertools import groupby
sorted_list_k=[1,2,3,4,5,12,11,10,9,65,66,64,63,67]
sorted_list_k = sorted(sorted_list_k) # 冒泡排序
fun = lambda x: x[1]-x[0]
for k, g in groupby(enumerate(sorted_list_k), fun):
list_continuous_slice = [j for i, j in g] # 连续slice数字的列表
print(list_continuous_slice)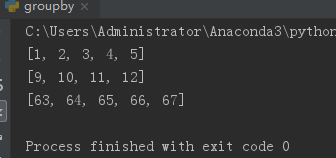
8.python中xpinyin汉字转拼音
from xpinyin import Pinyin
def readTXT():
p=Pinyin()
print(p.get_pinyin(u"小白CV",""))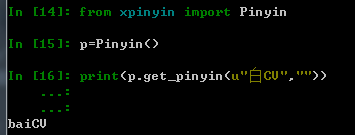
小字没了,多多见谅啊。
9.python统计xml文件中特定字符出现的次数
如题,在深度学习领域中经过会用到label标签一个名词,标记的信息类别将以字符的形式保存在xml文件中。
此时若是想要统计,究竟各个类别的数量是多少的时候,仅仅是依靠看看有多少张图片是不够的(因为同一图图像可能会同时包含多种类别,别入car/tree/people等等)
此时,最有效的方式就是对xml文件直接操作,获取一手信息,对各个类别都有一个反应
#!/usr/bin/env python
# -*- coding:utf-8 -*-
import os
import xml.etree.ElementTree as ET
inflection_list=[]
for xml_file in os.listdir("D:/image/voc_inflection4/Annotations/"):
a, b = os.path.splitext(xml_file)
tree = ET.parse("D:/image/voc_inflection4/Annotations/" + a + ".xml")
root = tree.getroot()
for inflection_name in root.iter('object'):
target = inflection_name.find('name').text
inflection_list.append(target)
inflection_set=set(inflection_list)
inflection_dict={}
for i in inflection_set:
inflection_dict[i]=inflection_list.count(i)
#print(inflection_list)
print(inflection_dict)
今天就到这里,后续将持续更新中,欢迎关注
补充10:将文件夹内的数据,依据文件名的一致性,分别保存到对应的文件夹
def file2document():
int_path = 'F:\\TB肺结核\\database\\train\\pneumonia_raw'
flag="(0)"
for root, dirs, files in os.walk(int_path):
for filename in files: # 遍历所有文件
#print(filename)
name=filename.split("_")[1]
if name == flag:
shutil.copy(os.path.join(root, filename), os.path.join("F:\\TB肺结核\\database\\train\\pne\\", name))
else:
#os.mkdir(r"F:\\TB肺结核\\database\\train\\pne\\" + name)
flag=name
print(name)小白CV:公众号旨在专注CV(计算机视觉)、AI(人工智能)领域相关技术,文章内容主要围绕C++、Python编程技术,机器学习(ML)、深度学习(DL)、OpenCV等图像处理技术,深度发掘技术要点,记录学习工作中常用的操作,做你学习工作的问题小助手。只关注技术,做CV领域专业的知识分享平台。
————————————————



















 434
434

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











