




 本文详细介绍了条件生成对抗网络(Conditional GANs)的工作原理,包括其在图像到图像转换、语音增强和视频生成等领域的应用。StackGAN用于逐步生成高分辨率图像,而PatchGAN则解决了大图像生成时的过拟合问题。此外,文章还讨论了传统监督学习在图像生成中的局限性,并展示了GAN如何解决这些问题,特别是在处理多角度图像和连续序列生成时的优势。
本文详细介绍了条件生成对抗网络(Conditional GANs)的工作原理,包括其在图像到图像转换、语音增强和视频生成等领域的应用。StackGAN用于逐步生成高分辨率图像,而PatchGAN则解决了大图像生成时的过拟合问题。此外,文章还讨论了传统监督学习在图像生成中的局限性,并展示了GAN如何解决这些问题,特别是在处理多角度图像和连续序列生成时的优势。
文章目录
输入一个文字,然后产生对应那个文字的图片。
可以被单纯当成supervised learning
但是如果用传统的supervised learning,不同角度的图片会被直接取平均(产生正面的火车是好的结果,产生侧面的火车是好的结果,但是同时产生正面的火车跟侧面火车合起来,这是错误的结果)
Conditional GAN 介绍
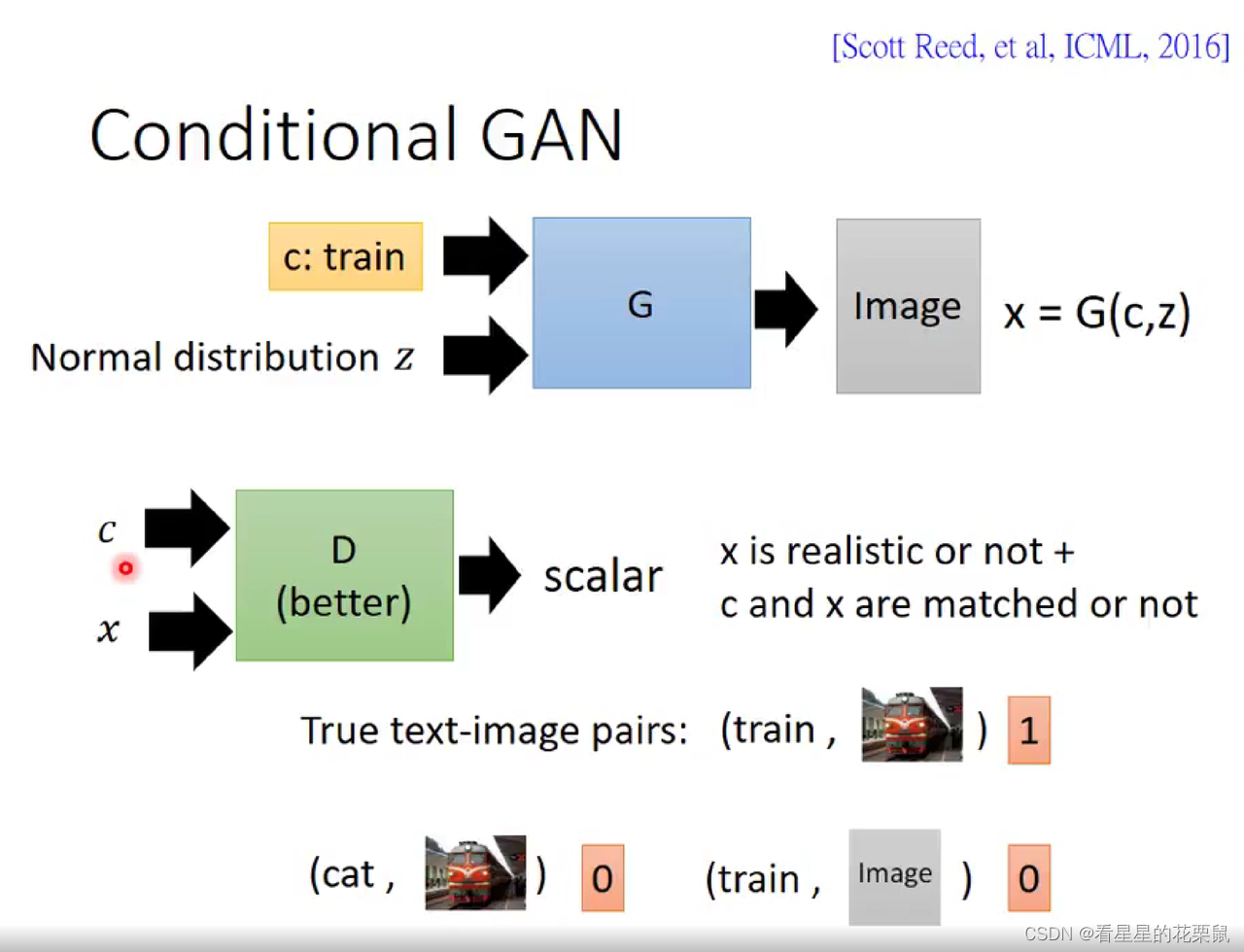
在原来的GAN里面,向generator输入一个从某种分布中抽取出来的z,根据z产生一张image x。但Conditional Generation里面不仅输入z ,同时输入另外一个 conditional的text c,根据这段文字还有z输出结果。
接下来要训练一个discriminator。 之前输入image输出scalar的方式不再适用,因为之前只识别图像是不是高质量的,不管和输入的文字有什么关系。
所以discriminator要同时看generator的输入和输出。输入一个condition(c),再输入一个object,然后产生一个scalar,对应到两个判断:
1、x是不是真实的;2、x和condition是不是一对。
有两种negative的情况,不匹配/图像不真实
具体算法
首先随机初始化,然后进行下面迭代:
训练判别器:(固定生成器)
- 首先从database中抽取m个样本,由于是condition GAN,所以每个样本都是文字 vector c 和image的pair。(得到真实图片对)
- 然后再从一个分布中抽取m个vector z;然后m个vector,每一个都加上一个condition vector,表示为(c,z)
- 然后将(c,z)输入生成器,生成m张image x~。(得到生成图片对)
- 然后进入database中随机选取m个真实图片x^(用于训练非对应的情况)(得到没有标签的真实图片,然后和之前真实图片标签进行配对;变成真实图片假标签对)
- 然后计算损失:对于sample的正确的一对就给高分,文字和随机生成图片给低分,文字和不匹配的真实图片也给低分。我们去最大这个损失,然后计算梯度,梯度上升。
然后训练生成器:(固定判别器) - 随机产生m个噪声,随机从database中抽取m个文字。通过生成器得到G(C,Z),然后经过判别器得到D(G(C,Z)),更改G中的参数,使得它的得分最高,骗过判别器。

图片中learningG的应该是梯度上升过程,+号
x ~ i \tilde{x}^i x~i是生成图片, x ^ i \hat{x}^i x^i是好的real图片,但是是随机筛选出来的,和c不匹配
文字+原始的positive example:高分
文字+生成的图片:低分
文字+随机抽取的不匹配real图片:低分
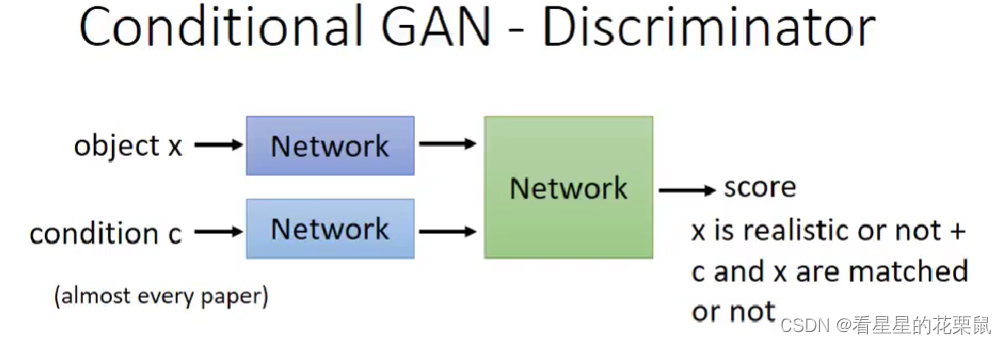
设计Discriminator
- Object x(图片)通过一个network变成embedding
- Condition c(文字)通过一个network变成embedding
- 两种embedding组合起来丢进network,输出score,代表了两件事,一件是图片有多好,另一件是 X 跟 C 有多合适
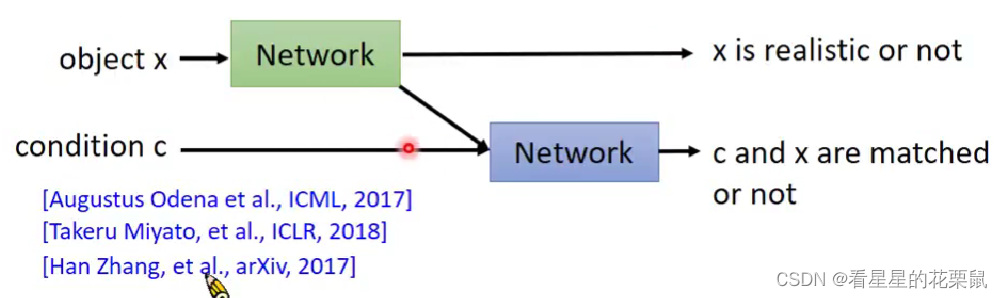
另一种:output两个分数(好像更合理)可以知道为什么低分,是不match还是quality不高
Stack GAN
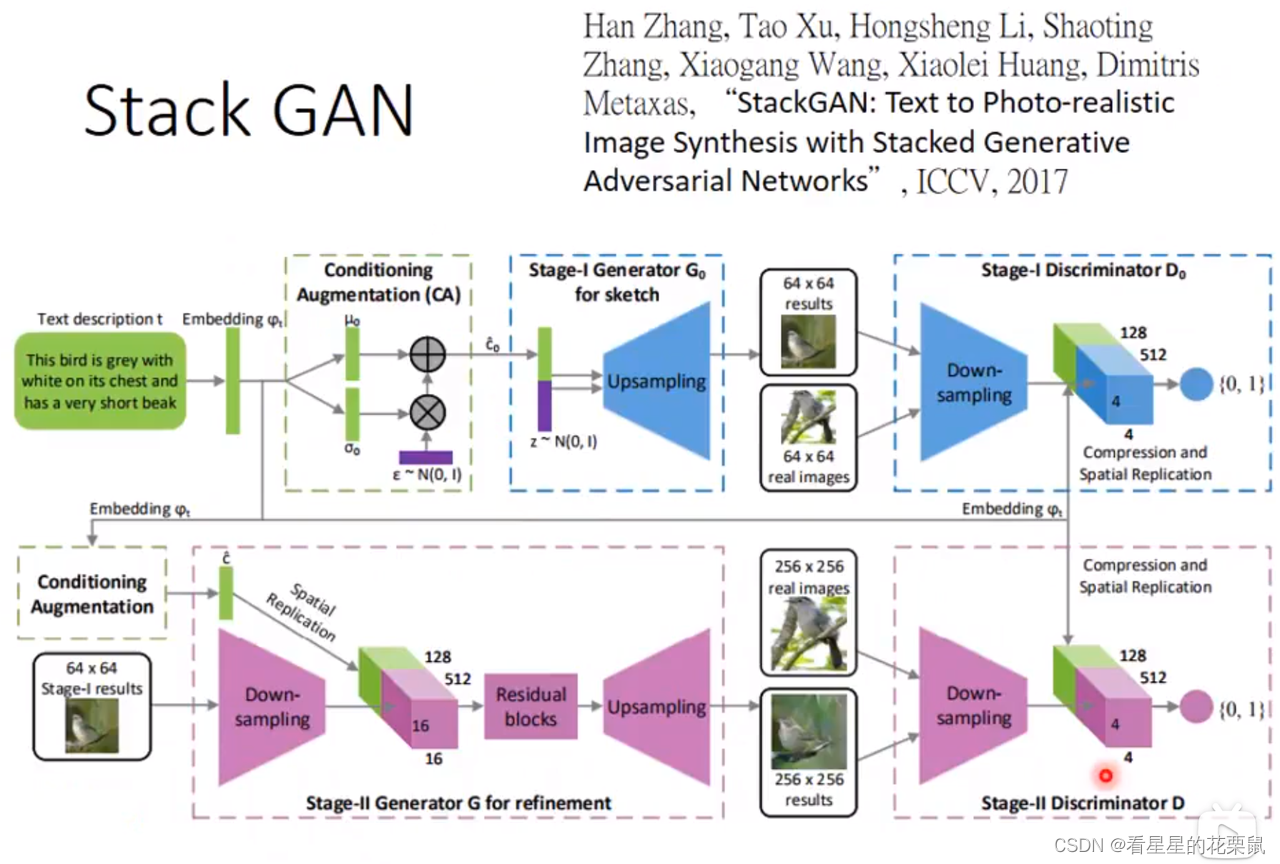
先产生小张的图,根据小张的图再产生大张的图。直接生成256*256的图会坏掉,所以:
- 首先文字输入,与noise结合,生成6464小图片,输入6464真实图片训练discriminator判断分数
- 第二个generator输入一个6464图和文字叙述,生成256256图片,再用256*256的真实图片训练另一个discriminator打分
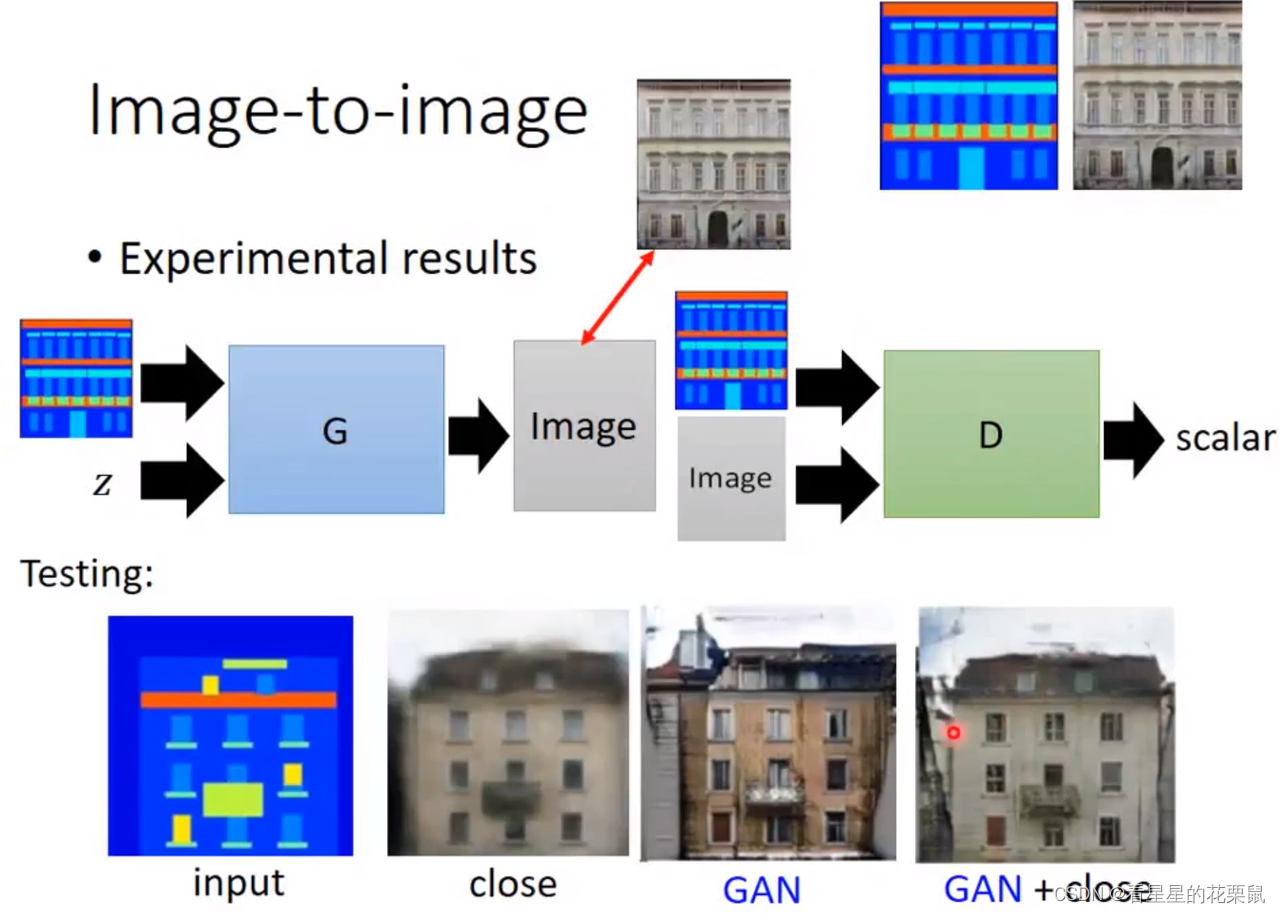
图片到图片
要有很多组data,如彩色&黑白,卡通&真实的
Supervised:用L1/L2 loss等,可产生比较模糊的图片(还是会有平均结果的问题)

引入GAN:
Patch GAN
Image-to-imager中discriminator的设计:
如果要产生的 image 非常大张,如果整张图片作为输入的话,结果很容易坏掉。因为image很大,discriminator参数也要很多,很容易overfitting或花很长时间
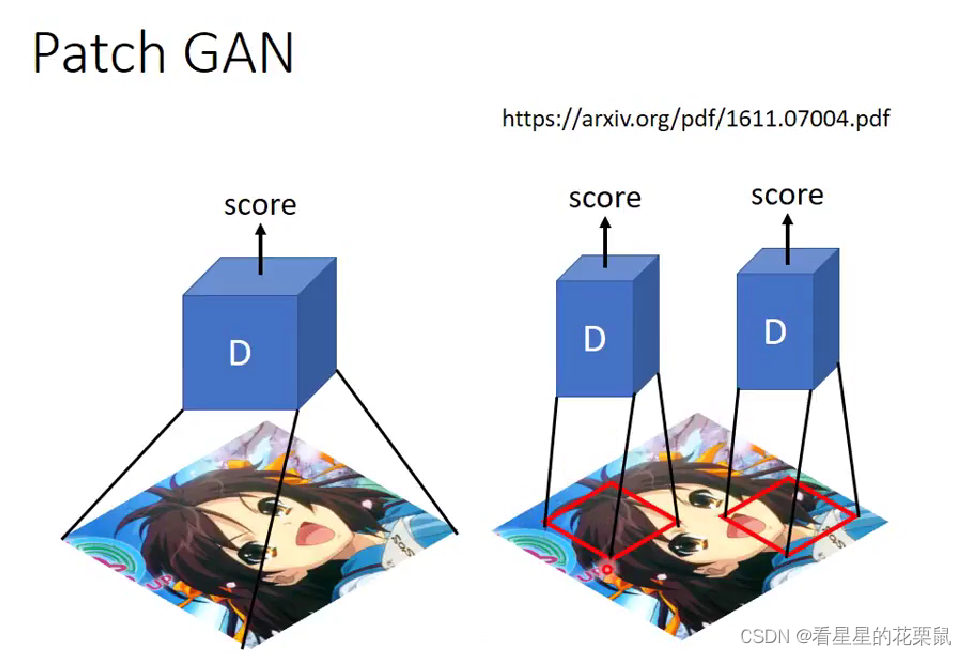
Patch GAN每次只检查一小块图片,size要自己调整
(只看一个pixl就叫pixl GAN,没用)
应用在speech enhancement
训练Generator:找很多声音,然后把这些声音也都加上一些杂音,之后和原声音对比
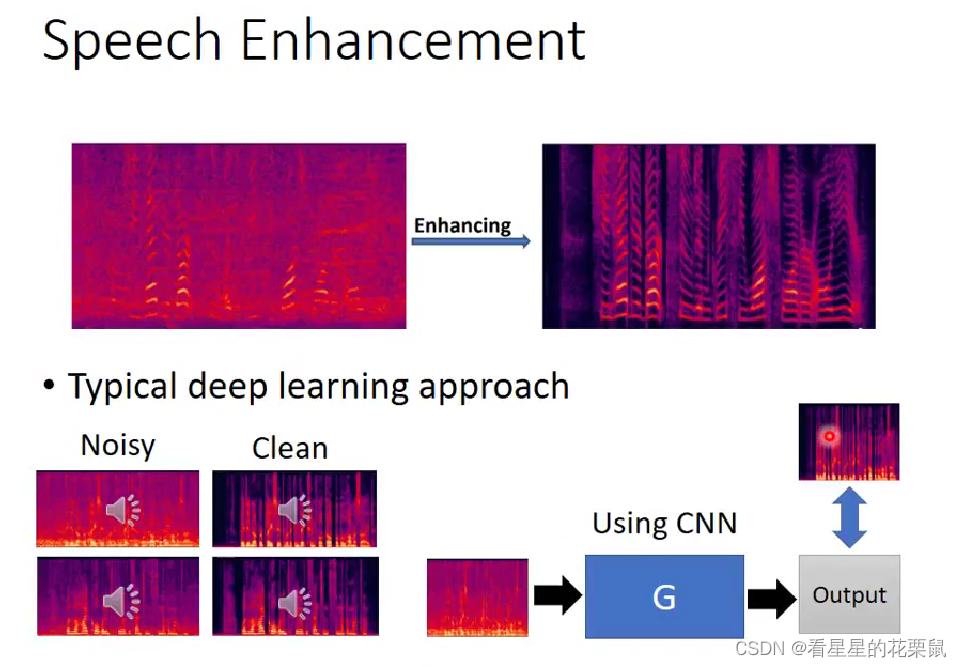
加上GAN:
generator的input和output同时输入discriminator
Video Generation
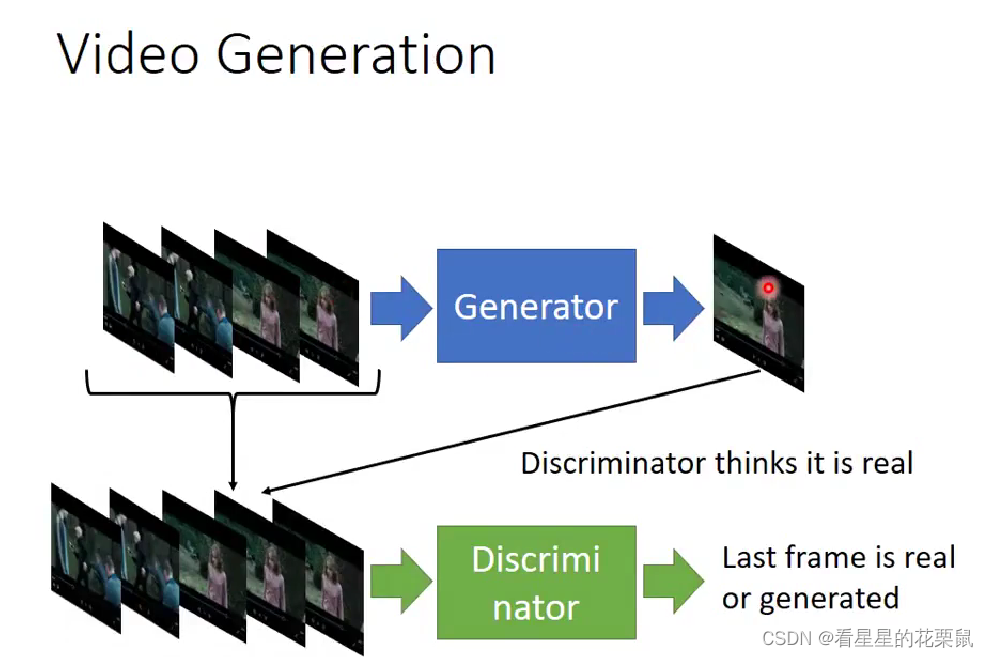
预测影片接下来发生的事情
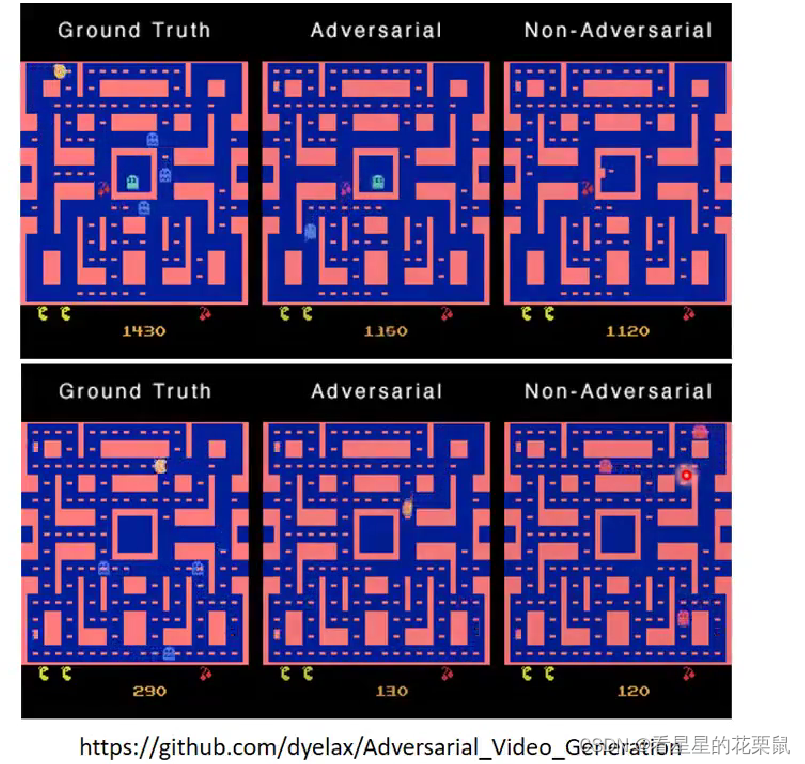
网络上找到的有人用 GAN 的技术产生小精灵游戏画面的结果。右边是没有用 GAN 的结果。没有用 GAN 发生的问题:小精灵走到转角就分裂了,为什么会分裂呢?因为在training data 里面同一个转角,有时候小心你会往左走,有时候会往右走,往左走是对的,往右走也是对的。但是对一个没有GAN的generator来说,它会把往左走往右走全部平均起来,结果就坏掉。往左走是对的,往右走也是对的,同时往左走跟往右走结果就会坏掉。中间是用GAN做的,不太会有分裂的情形。但结果也不是特别完美,会发现有些小精灵走着走着就不见了。还有个有趣的现象是数字会随机跳动。


















 1169
1169

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









