



 本文提出了一种名为ComponentDivide-and-Conquer (CDC) 的模型,用于解决真实世界图像超分辨率(Real-World Image Super-Resolution)的挑战。CDC模型通过三个组件注意块学习注意力掩码,采用中间监督学习策略预测超分结果。同时,引入了梯度加权(GW)损失,以平衡不同图像区域的重建。此外,作者创建了一个大规模真实世界的超分辨率图像数据集DRealSR,弥补了现有数据集的不足。实验表明,CDC模型和GW损失在处理复杂纹理细节和不同图像区域的恢复上表现出色。
本文提出了一种名为ComponentDivide-and-Conquer (CDC) 的模型,用于解决真实世界图像超分辨率(Real-World Image Super-Resolution)的挑战。CDC模型通过三个组件注意块学习注意力掩码,采用中间监督学习策略预测超分结果。同时,引入了梯度加权(GW)损失,以平衡不同图像区域的重建。此外,作者创建了一个大规模真实世界的超分辨率图像数据集DRealSR,弥补了现有数据集的不足。实验表明,CDC模型和GW损失在处理复杂纹理细节和不同图像区域的恢复上表现出色。
超分:Component Divide-and-Conquer for Real-World Image Super-Resolution(ECCV2020)
摘要
超分处理的目标会随着图像不同区域变化,例如平坦区域保持平滑、边缘区域的锐化和纹理细节部分的增强。传统的像素损失超分模型通常会被平坦区域和边缘控制,无法推断复杂的纹理细节。本文提出了组件分治方法(CDC)模型和梯度加权(GW)损失。
CDC模型从三个组件解析图像:使用三个成分注意块(CABs)学习注意力掩码,通过中间监督学习策略进行超分预测,以及根据分治学习原则训练出了一个超分模型。同时,GW损失为平衡各组件提供了可行方法。
此外,本工作还创建了一个大规模真实世界的超分辨率图像数据集DRealSR。
工作简介
难点
一、SR模型必须在模拟的退化图像数据集上进行训练,一般LR图像是通过简化的下采样方法(例如双三次采样)获得的。这种模拟的退化通常会偏离真实退化情况,使得学习到的模型不适用于真实世界超分处理;
二、平均的像素级损失(如MSE)会导致模型过拟合或着重关注易重建的区域。SR的目标随着LR区域的不同而变化,平坦区域和边缘是图像中最常见的。通过均匀像素丢失学习的模型更倾向于寻找平坦区域和边缘,但难以推断复杂纹理细节。
启发
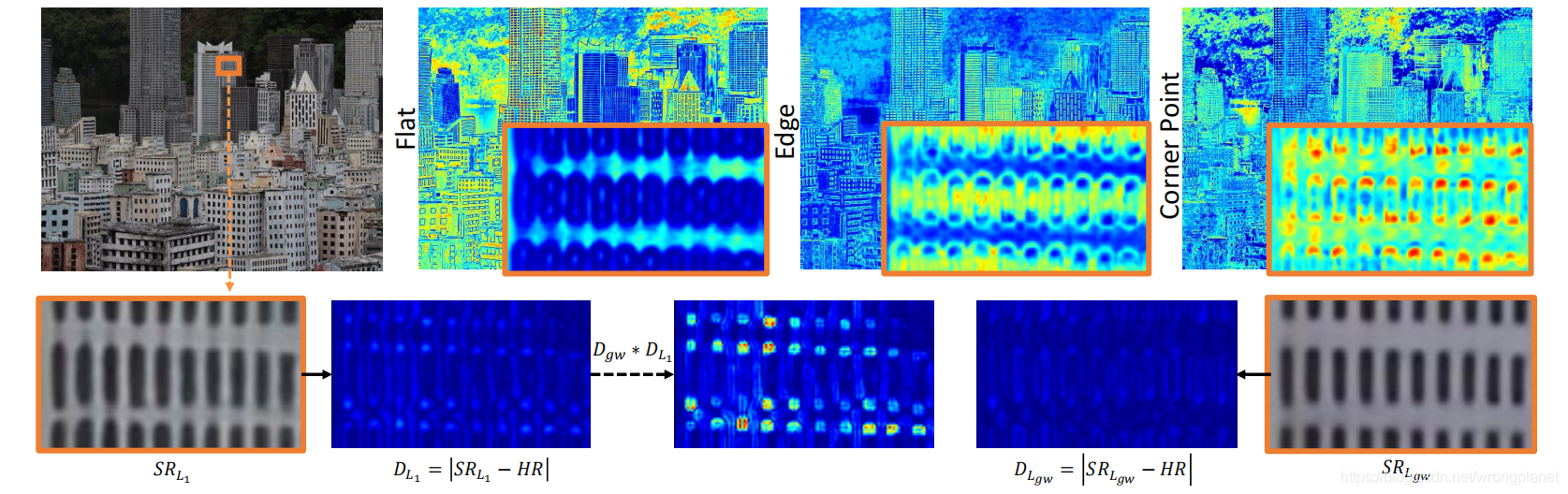
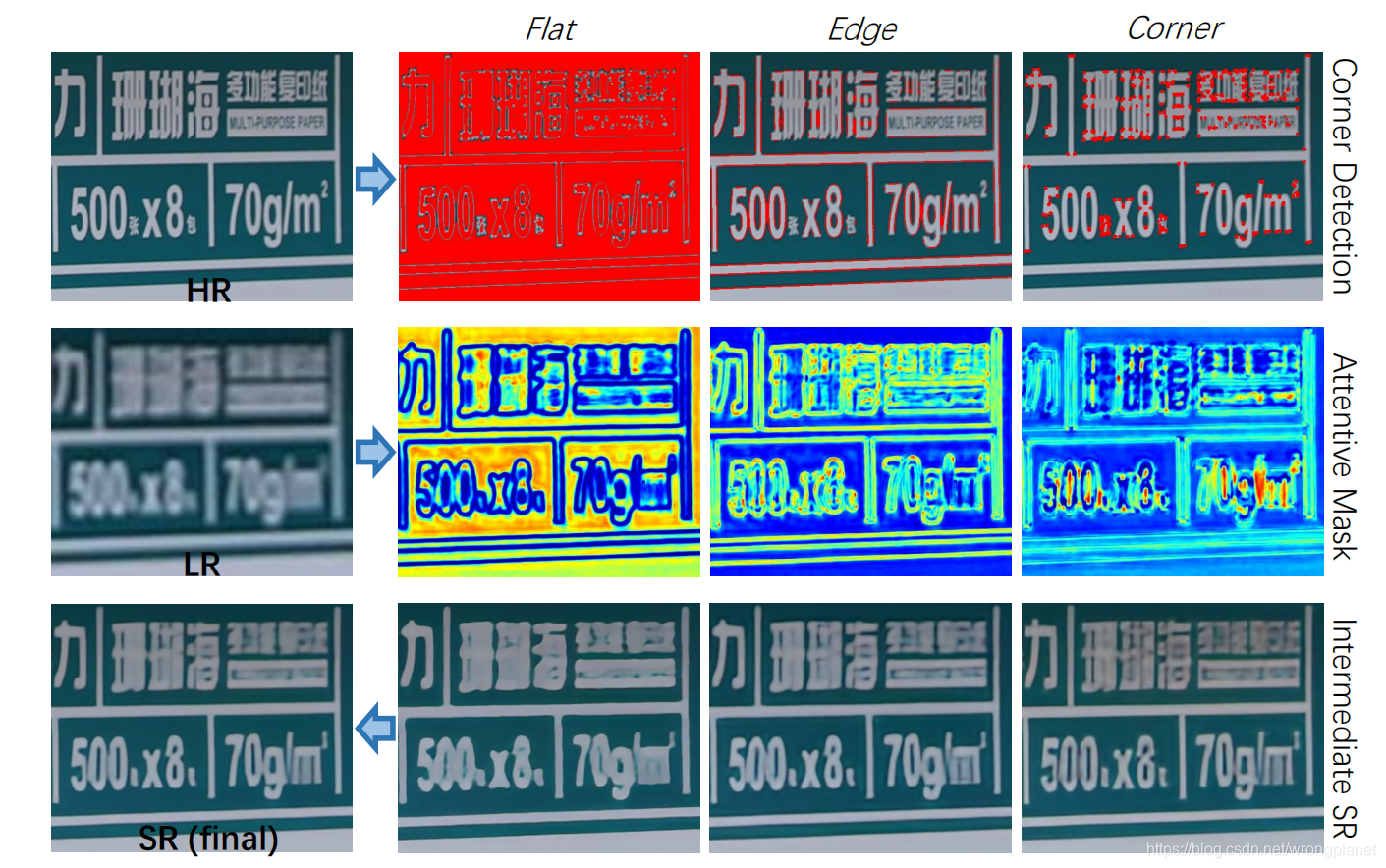
上图1展示了不同区域的不同重建难度,特别是平坦、边缘和角点区域。
S
R
L
1
SR_{L1}
SRL1 和
S
R
L
g
w
SR_{Lgw}
SRLgw 分别是L1损失和GW损失的SR结果。
D
L
1
D_{L1}
DL1呈现出不同区域的重建难度,反映了图像退化的复杂性。可以观察到
D
L
1
D_{L1}
DL1中:值从小到大的区域,与平坦、边缘和角点区域相对一致,这启发我们引入加权策略,驱使模型关注难度较大区域。第一行是CDC模型学习到的三个注意力掩码,它们分别能很好地预测平面、边缘和角落区域的置信度。
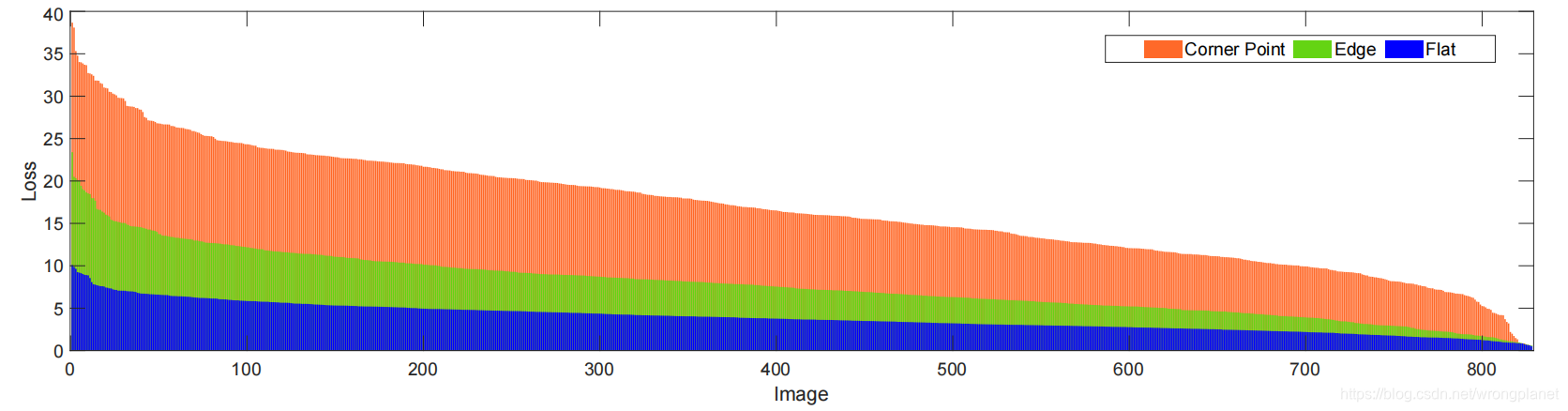
上图2中,作者分析了L1损失在三个分量(平面、边缘和角落)的比例,评估它们对平均像素级损失的SR重构的影响。可以观察到三种成分有不同的恢复难度:光滑区域和边缘的损失较低,而角点的损失较高。因此,这启发我们研究这三种成分在SR任务中的效用。
受Harris角点检测的启发,链接: Harris角点检测
亮点
- 使用五种数码单反相机建立了一个大规模的真实世界SR数据集(DRealSR)。它缓解了传统卷积模拟图像退化的局限,建立了新的基准。
- 提出了组件分治模型(CDC),采用三个成分注意块学习不同成分的注意掩码,并以中间监督学习策略预测中间级SR结果。
- 使用了梯度加权损失(GW),充分利用图像结构信息以获得较好细节。同时梯度加权损失探索了像素级SR任务中不同图像区域的不平衡学习问题,提供了一种有前景的解决方案,可扩展到其他低级视觉任务。
数据集的创建
收集过程
这些图像5种单反相机在自然场景中拍摄。对于每个比例因子,采用SIFT方法对图像进行配准,裁剪出相匹配的LR图像与HR图像。为了细化配准结果,将图像分割成小块,采用迭代配准算法和亮度匹配。为了便于模型训练以及考虑到它们的图像大小分别为4000x6000或3888×5184,将这些训练图像分别裁剪成380x380、272x272、192x192的patches,分别用作x2~x4的训练。为防止HR和LR不匹配,我们还会对patches进行仔细的手动选择。
真实数据集的挑战
与模拟的图像退化相比,真实世界的SR有以下新的挑战。
- 与双三次下采样相比更复杂的退化过程。双三次下采样简单地将双三次下采样器应用于HR图像以获得LR图像。然而,在真实场景中,通常在各向异性模糊之后进行下采样,同时也可能添加信号相关的噪声。因此,LR图像的采集存在模糊、下采样和噪声的问题。同时还受到摄像头内信号处理(ISP)管道的影响。通过(上图2)对不同图像区域的重建难度分析,可以验证真实图像退化的非均匀性。
- 不同设备的退化过程不同。在实际场景中,相机的镜头和传感器之间的差异决定了不同的成像模式,因此具有不同的退化过程,训练出的模型也有相应的局限性。
网络架构
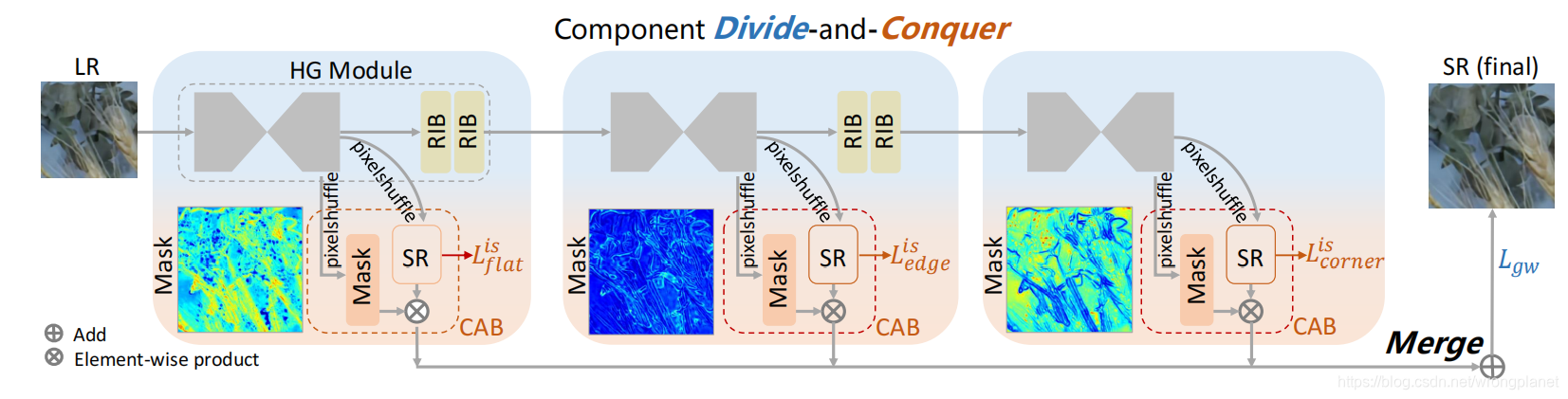
本文构建了具有层叠结构的HGSR网络,提出了具有梯度加权损失的组件分治模型CDC。
Divide:考虑到平面、边缘和角点区域图像内容的复杂性,设计三个HG模块,利用HR图像的组件解析指导分别学习LR图像的各组件注意掩码。需要注意的是,我们并不直接从LR图像中检测三个成分,而是预测与HR图像相一致的映射。主要原因是LR图像质量较差,阻碍了更准确的角点检测,导致检测结果不理想。另一个原因是该策略避免了在测试阶段对每幅图像进行角点检测。
Conquer:三个成分-注意块(Component-Attentive Blocks)产生不同的成分-注意掩码和中间SR预测。所生成的注意图具有三个组成部分的显著特征。与此同时,中间SR结果与三个区域的特征基本一致。
Merge:最终的SR结果聚合了三个中间SR输出,它们由相应的成分注意映射图(component-attentive maps)加权。特别地,我们利用了GW损失驱动模型自适应学习。
1.CDC模型
HGSR网络:基于2016年提出的HG方法(a)设计HGSR网络(b),并用其设计了CDC模型(c):

Component-Attentive Block:CAB由两个像素变换层组成。一个用来生成粗略的中间SR结果,另一个用于生成表示成分概率图的掩码。同时,CAB为每一个中间SR结果加权,以便最终合并。在训练阶段,CDC利用HR图像产生一个IS loss(
£
i
s
\pounds_{is}
£is)。
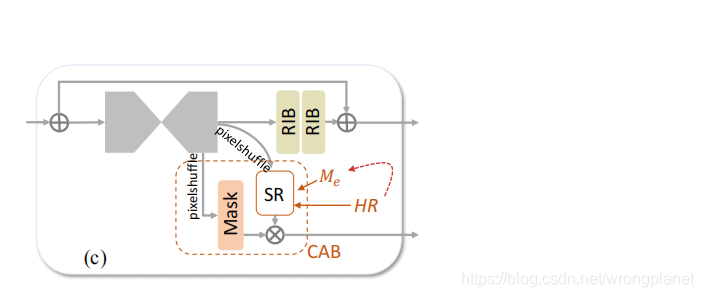
CDC模型如图
下图三行分别展示了Harris角点检测,成分注意掩码和三个CAB产生的中间SR图像的结果。每一行又包含为Flat、Edge、Corner三个区域。
2.损失函数
总的损失函数: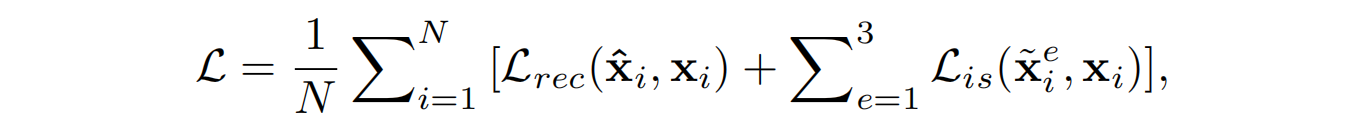
其中, £ r e c \pounds_{rec} £rec是最后的重建损失, £ i s \pounds_{is} £is是中间SR结果相对GT的损失,下标e表示一个CAB块, e = 1 , 2 , 3 e=1,2,3 e=1,2,3分别对应与平坦区、边缘和角点; X i e X_{i}^{e} Xie是中间SR预测结果。
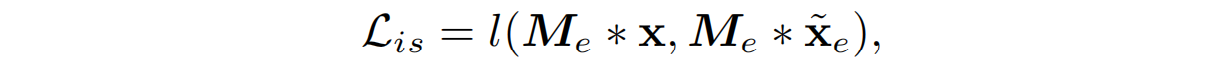
M
e
M_e
Me是从HR图像中提取的component guidance mask,
l
l
l在此处采用的是L1损失函数。
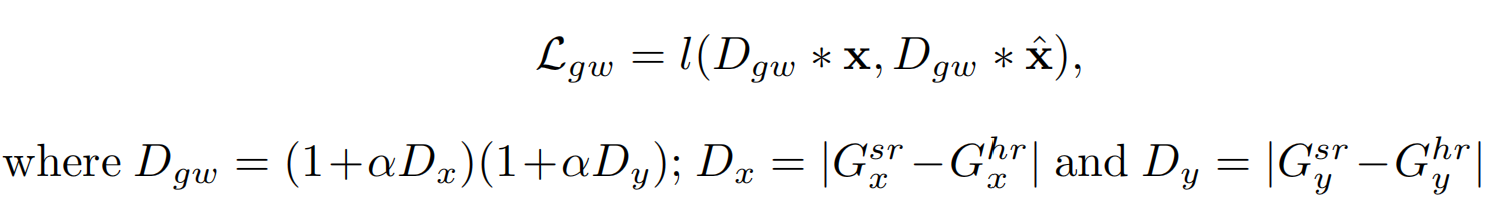
重建损失
£
r
e
c
\pounds_{rec}
£rec采用了梯度加权损失即
£
g
w
\pounds_{gw}
£gw;
比例因子
α
\alpha
α决定了损失函数中的权重数量,本方法中
α
\alpha
α取4。
D
x
D_x
Dx和
D
y
D_y
Dy分别表示LR和HR间在水平和1垂直方向上的梯度差异,
l
l
l同样采用了L1损失。
实验阶段
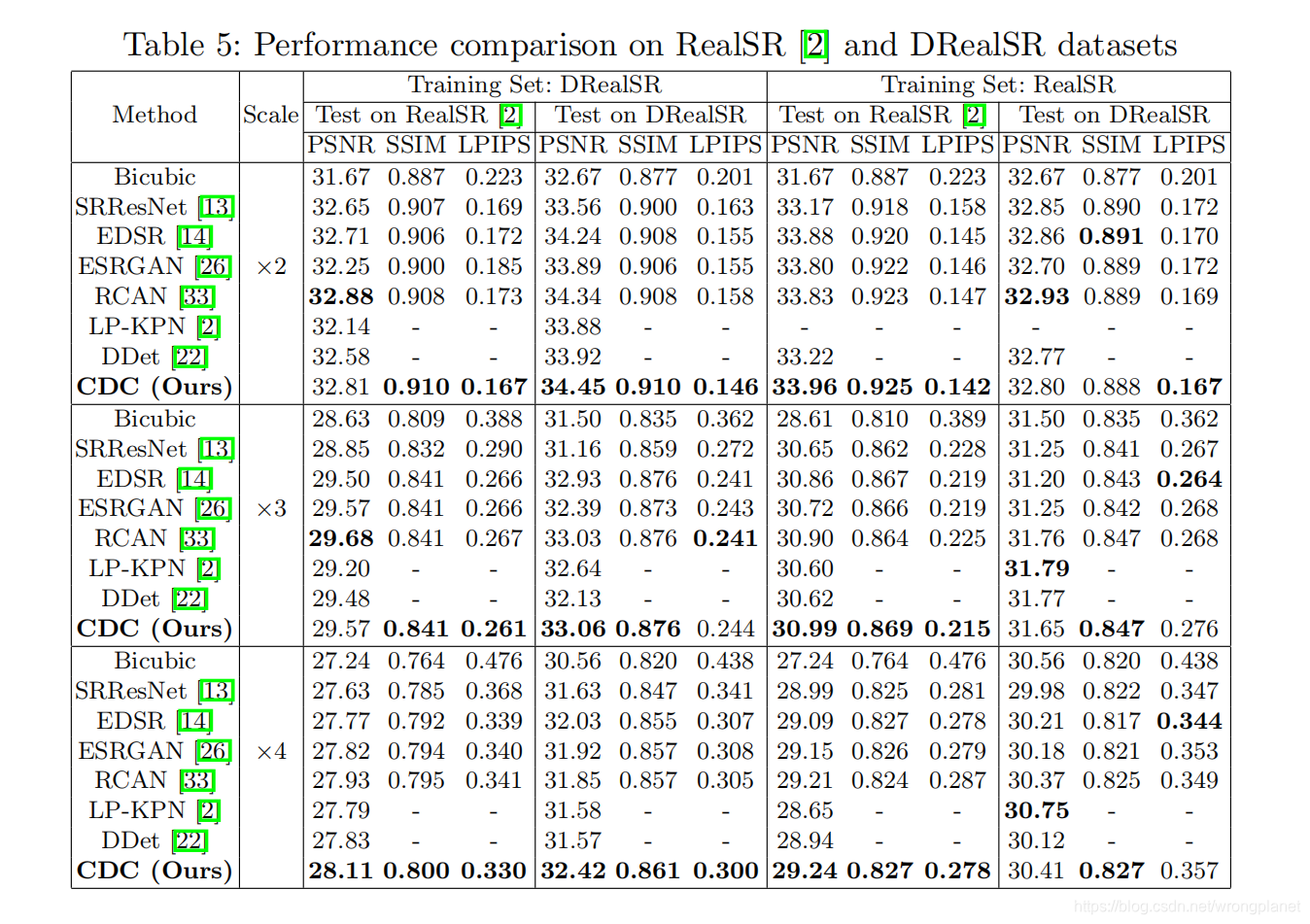
数据集:在现有的真实世界SR数据集RealSR和我们创建的DRealSR上进行实验。
RealSR有595个HR-LR图像对,由两个单反相机拍摄。随机选取每个相机每个比例因子下的15对图像对构建测试集,其余作为训练集。它们的图像大小在[700,3100]和[600,3500]之间,每幅训练图像被裁剪为192x192个patch。
对于x2~x4,我们的DRealSR分别有884、783和840个图像对,其中分别随机选取83、84和93个图像对进行测试,其余的分别在对应缩放因子进行训练。
实现细节:优化器:Adam,0.9和0.999的指数衰减率;
初始学习率
2
×
1
0
−
4
2×10^{-4}
2×10−4,每一百个epoch减半;
每个training batch随机提取16个LR patch,大小48×48;
消融实验:作者分别对HG blocks、CAB、GW loss做了评估,此处不再赘述。
与先进方法在真实数据集的效果比对:


















 1054
1054

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









