



 本文提出了一种名为HAN的整体注意网络,用于单图像超分辨率任务。HAN包含层次注意模块(LAM)和通道-空间注意模块(CSAM),能捕获不同层、通道和位置之间的全局依赖关系,从而提高超分辨率的性能。LAM考虑了层次特征间的相关性,而CSAM则强化了通道和空间信息。实验表明,HAN在精度和视觉质量上优于现有的超分辨率算法。
本文提出了一种名为HAN的整体注意网络,用于单图像超分辨率任务。HAN包含层次注意模块(LAM)和通道-空间注意模块(CSAM),能捕获不同层、通道和位置之间的全局依赖关系,从而提高超分辨率的性能。LAM考虑了层次特征间的相关性,而CSAM则强化了通道和空间信息。实验表明,HAN在精度和视觉质量上优于现有的超分辨率算法。
超分:Single Image Super-Resolution via a Holistic Attention Network
摘要
- from ECCV2020
- 在单图像超分辨率任务中,已有的通道注意方法可以有效保存每一层具有丰富信息的特征。然而,通道注意将每个卷积层独立处理,却忽略了不同层之间的相关性。为了解决这一问题,作者提出了一种整体注意网络——HAN,该模型由层次注意模块(LAM)和通道-空间注意模块(CSAM)组成,以模拟不同层、通道和位置之间的整体关系,获得更好的超分效果。
主要亮点
- 提出了一种新的超分算法——整体注意网络HAN,提高了超分辨率的特征表示能力;
- 引入了层次注意模块(LAM),考虑多尺度层次之间的相关性来学习得到层次特征的权值,同时提出了通道-空间注意模块(CSAM)来学习每一层特征的通道和空间相关性;
- 本文提出的两个注意模块通过对分层层次、通道和位置之间的信息特征进行建模,共同提高了处理结果。
HAN网络架构
1.网络组成
HAN网络主要可分为四部分:特征提取、LAM模块、CSAM模块和最终的重建块。

特征提取
首先对输入的LR图像进行卷积提取浅层特征:

然后使用RCAN网络的框架,设置N个residual group(RG)得到中间特征:
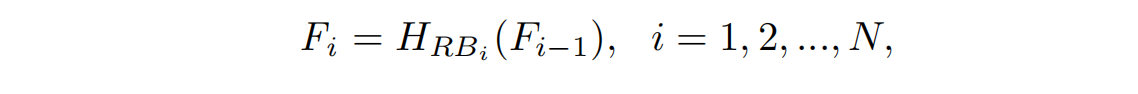](https://i-blog.csdnimg.cn/blog_migrate/be783c18ab30e571e08589320a00c6c0.png)
整体注意
对提取到的特征进行整体特征加权,包括:i)对层级特征即各
F
i
F_i
Fi的层次注意 ii)对RCAN最后一层即
F
N
F_N
FN的通道-空间注意:

1.其中
H
L
A
H_{LA}
HLA表示LAM模块, L从RGs的输出特征中学习特征相关矩阵,然后为各
F
i
F_i
Fi加权。结果表明,该方法能够增强高贡献的特征层,抑制冗余特征层。

2.
H
C
S
A
H_{CSA}
HCSA表示CSAM模块。通道-空间注意的目的是通过调节特征,自适应地捕捉通道间和通道内更重要的信息,以便最终的重建处理。基于准确性与效率的权衡考量,此步只以
F
N
F_N
FN作为输入。
图像重建
在LAM和CSAM分别提取特征后,对两者结果联合处理,采用亚像素卷积的上采样方法

U
↑
U_↑
U↑代表亚像素卷积操作,
F
0
F_0
F0、
F
L
F_L
FL、
F
C
S
F_{CS}
FCS分别代表初始输入,LAM层处理结果和CSAM层处理结果。
损失函数

本方法采用了简单的
L
1
d
i
s
t
a
n
c
e
L_1 distance
L1distance 作为损失函数。上式m表示参与训练的数据对数。后续的验证实验可以证明,L1损失已能够取得较好效果。
2.LAM模块

本模块的输入是从
N
N
N个residual group提取到的各层次特征图,维度为
N
×
H
×
W
×
C
N×H×W×C
N×H×W×C,并将其reshape至
N
×
H
W
C
N×HWC
N×HWC维度,和对应的转置矩阵进行矩阵相乘,计算得到各层之间的相关系数
W
l
a
=
w
i
,
j
=
1
N
W_{la}={w_{i,j=1}}^N
Wla=wi,j=1N,

δ
δ
δ表示softmax,
ψ
ψ
ψ表示reshape操作,
w
i
,
j
w_{i,j}
wi,j代表第i个和第j个特征图间的相关系数。将变形各矩阵加权相乘再加上原矩阵,得到
F
L
j
F_{L_j}
FLj.

α
α
α为比例因子,初始化为0,在后续各epoch自动调整更新。最终的带权和能够着重关注信息丰富的特征部分。
3.CSAM模块

将最后一层的特征图
F
N
F_N
FN作为输入,通过三维卷积层获得通道和空间特征
W
c
s
a
W_{csa}
Wcsa,这样可以得到更有效地通道内和通道间信息。

此外,将注意力映射图
W
c
s
a
W_{csa}
Wcsa和输入特征
F
v
F_v
Fv进行元素乘法运算。最后,将加权后的结果乘以一个比例因子
β
β
β,再加入输入特征
F
N
F_N
FN得到加权特征
F
c
s
F_{cs}
Fcs.其中
σ
σ
σ为sigmoid函数,
β
β
β为比例因子,初始化为0。
实验过程
1.相关设置
数据集:DIV2K做训练集;Set5 ,Set14,B100,Urban100和Manga109做测试集。
通过双线性插值和模糊降尺度退化模型得到退化数据集。经过HAN重构的RGB结果转换到
Y
C
b
C
r
YC_bC_r
YCbCr空间,在实验中只考虑亮度通道来计算PSNR和SSIM。
实现细节:使用PyTorch平台和预先训练的RCAN (x2), (x3), (x4), (x8)模型来分别初始化相应的HAN网络。
patch size: 64 × 64。
batch size: 16
优化器:ADAM
学习率:
1
0
−
5
10^{-5}
10−5
数据增强方法:随机旋转和平移
Residual Group数量:10
epoch:250个
在Nvidia GTX 1080Ti GPU训练,时长约两天。
2.LAM和CSAM的消融实验

3.Residual Group个数的消融实验

4.CSAM个数的消融实验
可以观察到不同CSAM个数对最终结果影响甚微。

5.BI退化模型下实验结果
- 定量

- 视觉效果

总结
本文中提出了一种用于单图像超分辨率的整体注意网络,该网络利用自我注意机制自适应地学习不同深度、通道和位置之间的全局依赖关系。具体来说,是学习层注意模块捕获层次层之间的远程依赖关系。同时,通道-空间注意模块整合了每一层的通道信息和语境信息。这两个注意模块协同应用于提取多层次的特征,可以获取更多信息。在基准数据集上的大量实验结果表明,该模型在精度和视觉质量方面优于最先进的SR算法。
【论文链接】:http://www.ecva.net/papers/eccv_2020/papers_ECCV/papers/123570188.pdf.

















 1794
1794




 到【灌水乐园】发言
到【灌水乐园】发言







