




 本文详细综述了深度学习在3D点云处理中的应用,涵盖3D形状分类、对象检测、点云分割等领域,介绍了多种方法,如投影基、点基、图基和数据索引基。尽管在每章节的结论上稍显薄弱,但文章对于读者构建点云处理的知识框架十分有帮助,特别推荐给从事点云研究的人员阅读。
本文详细综述了深度学习在3D点云处理中的应用,涵盖3D形状分类、对象检测、点云分割等领域,介绍了多种方法,如投影基、点基、图基和数据索引基。尽管在每章节的结论上稍显薄弱,但文章对于读者构建点云处理的知识框架十分有帮助,特别推荐给从事点云研究的人员阅读。
文章目录
本文是最新的使用深度学习处理点云的综述文章,本文所提及的方法非常全,可以作为一个文章索引来看,而且本论文对方法的分类也很有意义。但是作为综述性文章,本文每章节的结论有点弱,并没有通过对文章的综述产生太多指导性的结论。但总体来说,这篇文章对于读者,起到了查缺补漏和搭建知识框架的作用。
对于做点云的同学,我还是非常建议阅读以下本文的。
本博客与其他有关该survey的博客的区别在于,本博客不翻译该survey,而是细节讲述一些其中提到的方法,和总结一些我的理解。
Survey
1、数据集有:
- ModelNet [6]
- ShapeNet [7]
- ScanNet [8]
- Semantic3D [9]
- KITTI Vision Benchmark Suite [10]
还有一些自动驾驶的数据集也包含了3D object detection & tracking的问题。
2、3D问题的分类与图像中的基本是一样的:
- 3D shape classification
- 3D object detection and tracking
- 3D point cloud segmentation
3、所有的方法按照解决的问题,使用的方法按照如下分类:
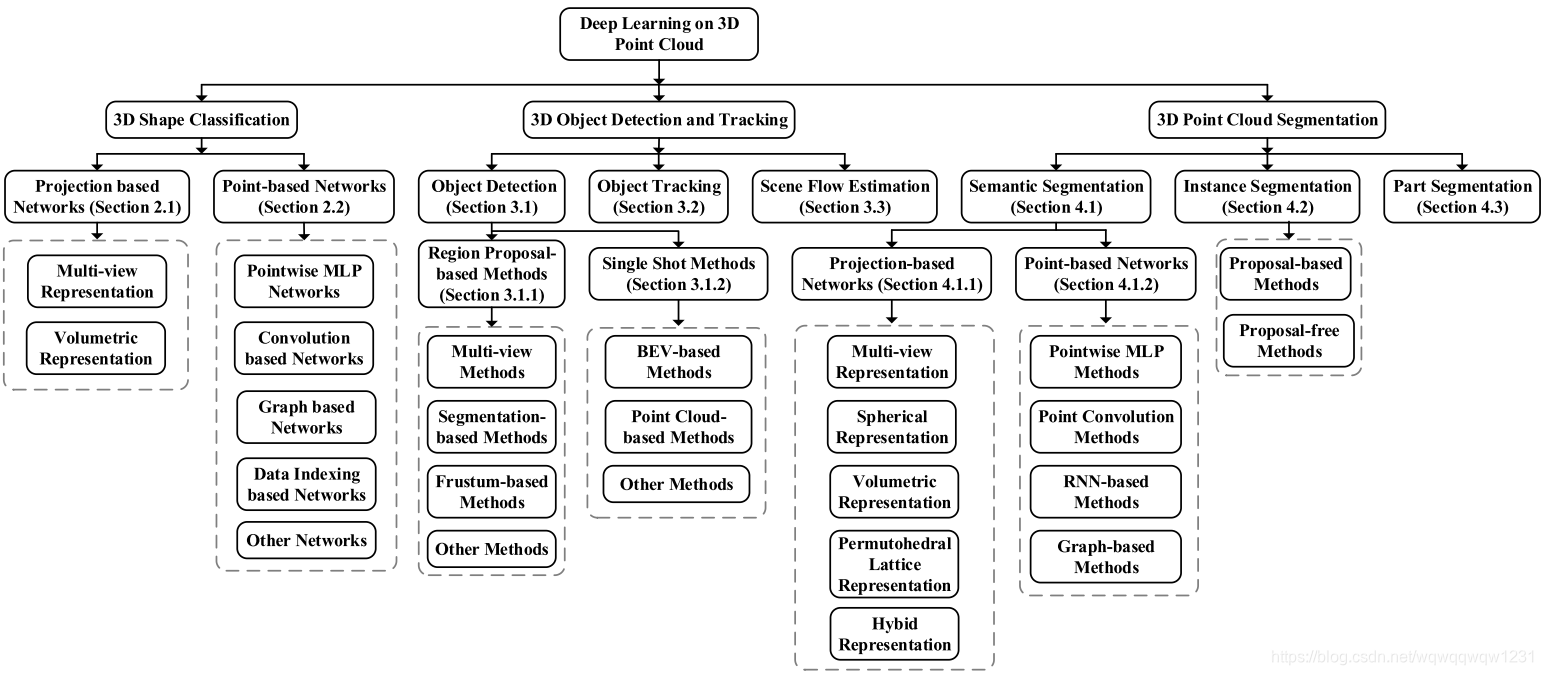
3D Shape Classification
该问题对应图像中的图像分类问题,是最简单的问题。按照图像处理的发展过程,可以认为,这部分提出来的网络将是Object Detection,Tracking和Segmentation方法的主干网络。
ModelNet40是一个普遍使用的数据集,排名可以在官网找到
Projection based
作者把Voxel的方法解归入到了Projection based的方法中,认为体素的构建过程是点云向3D栅格的投影过程。
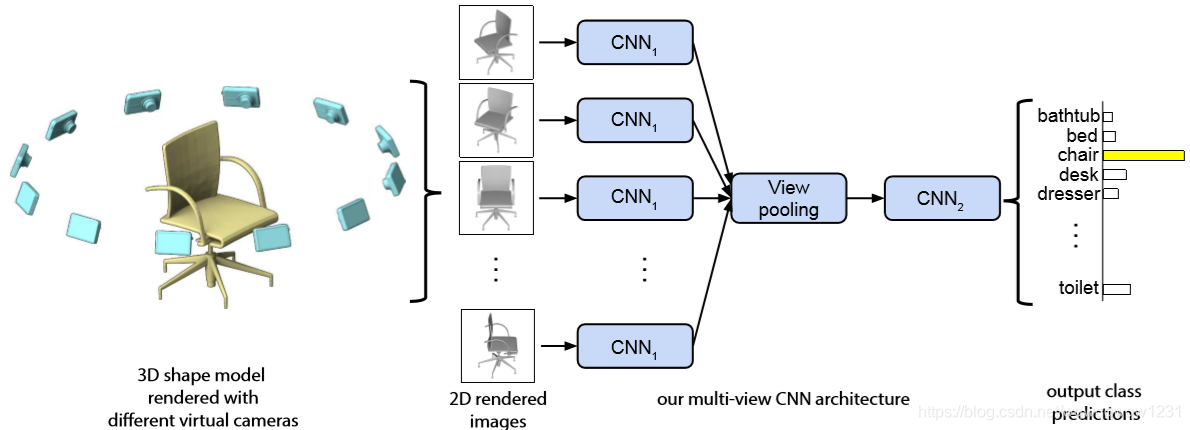
Multi-view
典型的方法就是MVCNN[15],将pointcloud投影到不同的视角下,其网络框架如下:
本文漏掉了目前ModelNet40精度最高的方法RotationNet,也是Multi-view类型的。相比于MVCNN,RotationNet使用了更多的视角,并在处理了每个视角的关系。其网络结构如下:
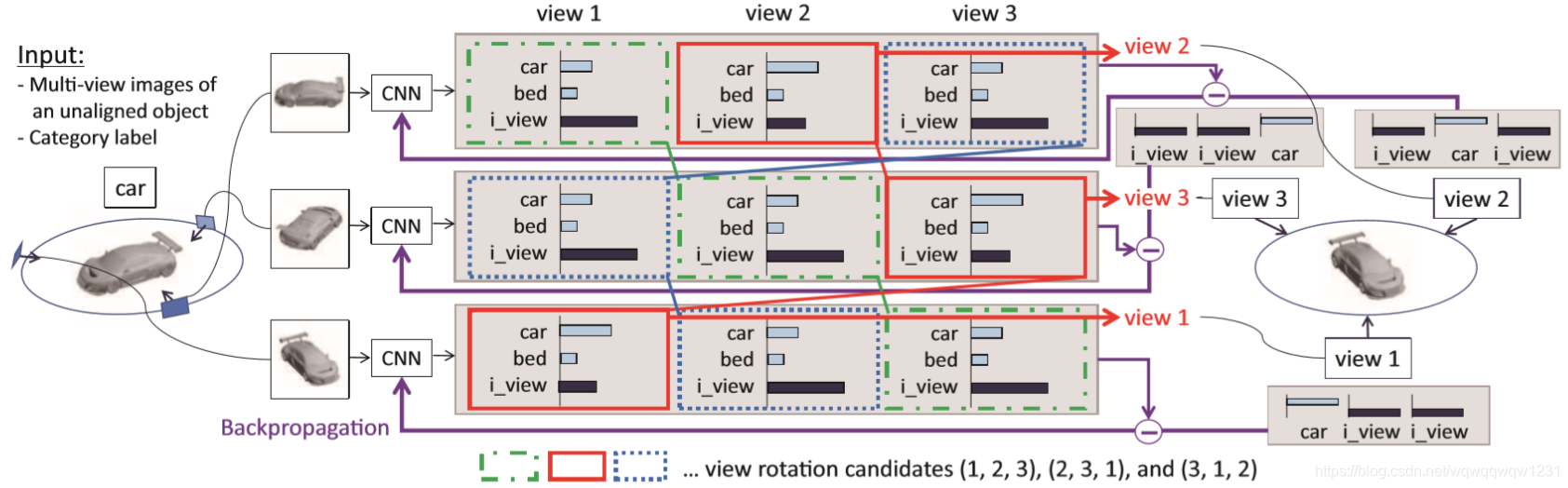
Multi-View的方法有以下几个特点:
- 理解简单,就是将点云投影到不同的view
- 网络结构已有,投影到2D平面之后,就可以用处理图像的CNN处理
- 精度高:RotationNet已有体现
- 处理速度慢:要处理多幅图像
- 对于一般场景不适用:因为要获取multi-view,例如智能车场景,就不可能获取多个view的投影
Voxel
典型方法以VoxNet[22]为例,就是把点云投影为占据栅格,然后使用3D convolution进行计算,具体结构如下图:

Voxel的方法在Object Detection的网络中也广泛使用,而其主干网络拿出来就可以作为Classification的网络使用,不同的代表有使用3D卷积的VoxelNet,使用2D卷积的PIXOR,使用Pointwise的feature构建Voxel的PointPillar等
Voxel的有以下特点:
- 理解容易,就是栅格化然后使用3D或者2D卷积
- 速度慢,占用内存大:内存占用和计算量都是与分辨率的立方有关
- 在体素化的过程中容易丢失信息,分辨率(精度)与计算效率的trade-off明显
Point based
Pointwise MLP network
这类方法以PointNet和PointNet++为主要代表,也是目前影响力最大的方法,Object Detection中Point based的主干网络大多用此网络搭建。典型结构如下:

在Pointnet++的基础上,又出现了一些改进方法。
Pointwise MLP network类方法的特点如下:
在计算过程中,每个点都对应一个feature,计算每个点的feature都是使用MLP计算,MLP的输入时某个点的feature,输出是这个点的新的feature。对应图像处理中的理解就是,都使用1x1的卷积核,每个像素的feature的计算过程只与自身的feature有关。
Convolution-based Networks
相比于Pointwise MLP的方法来说,Convolution-based方法在于一个点的feature在计算的时候使用了其他点的feature,类比于图像处理中,使用的卷积核不再是1x1,而是出现了3x3这种的卷积核。
而这类方法又分为两种,一种是3D Continuous Convolution Networks(3D连续卷积网络),一种是3D Discrete Convolution Networks(3D离散卷积网络)。理解这两者的区别可以先参考一下图像处理中的RoI Pooling与RoI Align,Conv和Deformable Conv。RoI Pooling和Conv都是对bin处理的,也就是说,认为feature map是与像素一样,分成栅格的。而后者RoI Align和Deformable Conv则认为特征在空间内是连续的,而feature map只不过是离散的采样,通过差值可以较好的恢复特征空间内任意一点的特征。由于认为特征空间是连续的,那么相对于权重空间也是连续的。用KPconv文中的话说:
“we believe that that having a consistent domain for g helps the network to learn meaningful representations.”
其中g是指卷积核。
理解了上述区别,就可以看懂下面一张图:
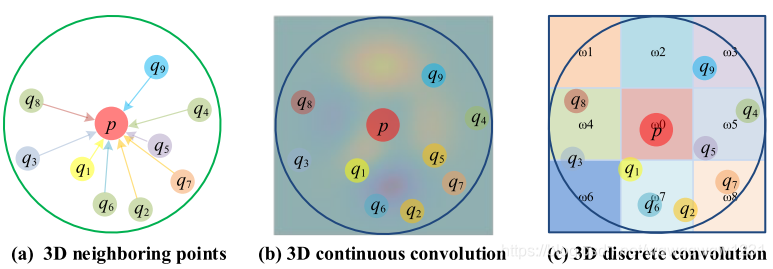
b)认为特征空间是连续的,c)认为特征空间是离散的。具体的细节需要看具体的论文。
Continuous Convolution Network
这里详细介绍RS-CNN和KP-CNN,来理解Continuous Convolution Networks的内容。
Discrete Convolution Network
这里详细介绍Pointwise Convolutional Neural Network[49]和PointCNN[52],来理解Discrete Convolution Networks的内容。
Graph based
这块内容我看的不多,也只看了Graph-based Methods in Spatial Domain,这里只介绍一下典型的DGCNN[60]
DGCNN的关键公式为如下:

x i x_i xi的新feature是由邻域内的点 x j x_j xj与 x i x_i xi的关系,通过 h θ ( ⋅ ) h_\theta(·)
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 5947
5947






 到【灌水乐园】发言
到【灌水乐园】发言







