







前言
v9还没整明白,v10又来了。而且还是打败天下无敌手的存在,连最近很火的RT-DETR都被打败了。那么,笑傲目标检测之林的v10又能持续多久呢?
一、YOLO10检测模型
近年来,YOLO在实时目标检测领域中因其在计算成本和检测性能之间的有效平衡而成为主要范式。
研究人员在YOLO的架构设计、优化目标、数据增强策略等方面进行了探索,并取得了显著进展。然而,依赖非极大值抑制(NMS)进行后处理限制了YOLO的端到端部署,并对推理延迟产生了不利影响。此外,YOLO中各种组件的设计缺乏全面深入的检验,导致明显的计算冗余,限制了模型的能力。这导致了次优的效率,以及相当大的性能提升潜力。
在这项工作中,原作者旨在从后处理和模型架构两个方面进一步推进YOLO的性能-效率边界。为此,首先提出了YOLO的无NMS训练的一致双重分配策略,同时带来了竞争力的性能和低推理延迟。此外,引入了面向效率-准确性驱动的YOLO模型设计策略,从效率和准确性角度全面优化YOLO的各个组件,大大减少了计算开销并增强了能力。
作者的努力成果是一代新的YOLO系列用于实时端到端目标检测,被称为YOLOv10。广泛的实验表明,YOLOv10在各种模型规模上实现了最先进的性能和效率。
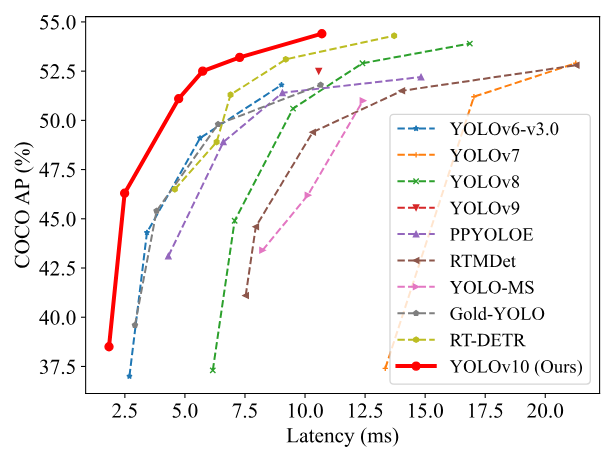
在延迟性和精度上的性能对比
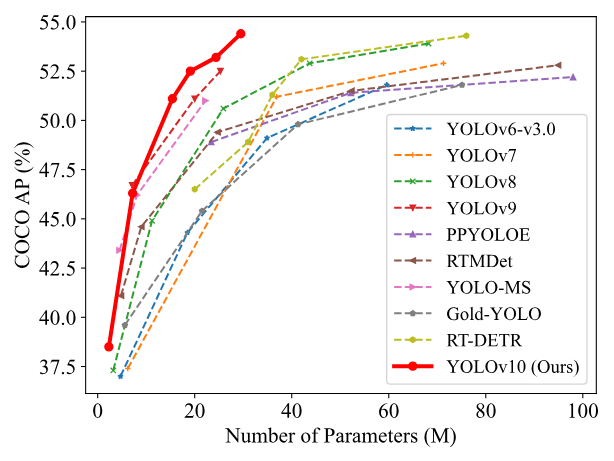
模型尺寸和精度上的对比
二、YOLO安装过程
硬件环境:显卡NVIDIA GeForce RTX 4090;
软件环境:Linux 20.04,Conda
2.1 新建conda的环境 yolo10
在conda创建一个名为yolov10的新环境,并在其中安装python3.9,这个环境是独立的不会影响系统中的其他环境:
conda create -n yolov10 python=3.9
然后再激活yolov10的Conda环境:
conda activate yolov10
通过pip命令安装requirements.txt中的python包及其版本号:
pip install -r requirements.txt
然后设置开发者模式:
pip install -e .
2.2 安装依赖包
然后安装预训练的模型文件:
wget https://github.com/THU-MIG/yolov10/releases/download/v1.1/yolov10s.pt
最后在执行运行代码:
python app.py
最后就进入了操作界面:
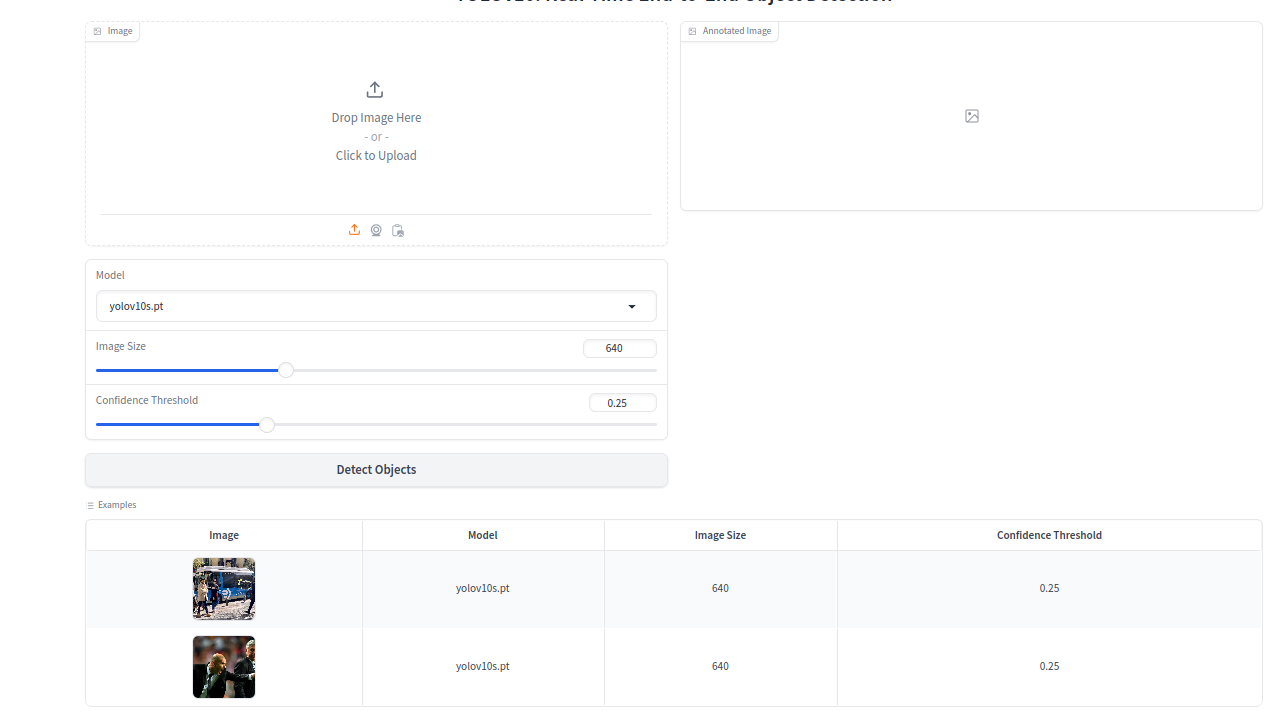
2.3 测试
先输入要处理图片,
模型:使用上面下载的预训练模型yolov10s.pt
处理完的图片:


从上面图片可以精确看到识别的效果,因此可以判断出来模型可以正常使用。
三、训练定制的数据集
3.1 装载数据:
数据入口的切换,前提是需要准备好yolo格式的数据集:

3.2 训练过程记录:
engine/trainer: task=detect, mode=train, model=yolov10n.pt, data=NEU.yaml, epochs=120, time=None, patience=100, batch=64, imgsz=640, save=True, save_period=-1, val_period=1, cache=False, device=None, workers=8, project=None, name=train, exist_ok=False, pretrained=True, optimizer=auto, verbose=True, seed=0, deterministic=True, single_cls=False, rect=False, cos_lr=False, close_mosaic=10, resume=False, amp=True, fraction=1.0, profile=False, freeze=None, multi_scale=False, overlap_mask=True, mask_ratio=4, dropout=0.0, val=True, split=val, save_json=False, save_hybrid=False, conf=None, iou=0.7, max_det=300, half=False, dnn=False, plots=True, source=None, vid_stride=1, stream_buffer=False, visualize=False, augment=False, agnostic_nms=False, classes=None, retina_masks=False, embed=None, show=False, save_frames=False, save_txt=False, save_conf=False, save_crop=False, show_labels=True, show_conf=True, show_boxes=True, line_width=None, format=torchscript, keras=False, optimize=False, int8=False, dynamic=False, simplify=False, opset=None, workspace=4, nms=False, lr0=0.01, lrf=0.01, momentum=0.937, weight_decay=0.0005, warmup_epochs=3.0, warmup_momentum=0.8, warmup_bias_lr=0.1, box=7.5, cls=0.5, dfl=1.5, pose=12.0, kobj=1.0, label_smoothing=0.0, nbs=64, hsv_h=0.015, hsv_s=0.7, hsv_v=0.4, degrees=0.0, translate=0.1, scale=0.5, shear=0.0, perspective=0.0, flipud=0.0, fliplr=0.5, bgr=0.0, mosaic=1.0, mixup=0.0, copy_paste=0.0, auto_augment=randaugment, erasing=0.4, crop_fraction=1.0, cfg=None, tracker=botsort.yaml, save_dir=/home/wqt/Projects/yolov10NEU/runs/detect/train
Overriding model.yaml nc=80 with nc=6
from n params module arguments
0 -1 1 464 ultralytics.nn.modules.conv.Conv [3, 16, 3, 2]
1 -1 1 4672 ultralytics.nn.modules.conv.Conv [16, 32, 3, 2]
2 -1 1 7360 ultralytics.nn.modules.block.C2f [32, 32, 1, True]
3 -1 1 18560 ultralytics.nn.modules.conv.Conv [32, 64, 3, 2]
4 -1 2 49664 ultralytics.nn.modules.block.C2f [64, 64, 2, True]
5 -1 1 9856 ultralytics.nn.modules.block.SCDown [64, 128, 3, 2]
6 -1 2 197632 ultralytics.nn.modules.block.C2f [128, 128, 2, True]
7 -1 1 36096 ultralytics.nn.modules.block.SCDown [128, 256, 3, 2]
8 -1 1 460288 ultralytics.nn.modules.block.C2f [256, 256, 1, True]
9 -1 1 164608 ultralytics.nn.modules.block.SPPF [256, 256, 5]
10 -1 1 249728 ultralytics.nn.modules.block.PSA [256, 256]
11 -1 1 0 torch.nn.modules.upsampling.Upsample [None, 2, 'nearest']
12 [-1, 6] 1 0 ultralytics.nn.modules.conv.Concat [1]
13 -1 1 148224 ultralytics.nn.modules.block.C2f [384, 128, 1]
14 -1 1 0 torch.nn.modules.upsampling.Upsample [None, 2, 'nearest']
15 [-1, 4] 1 0 ultralytics.nn.modules.conv.Concat [1]
16 -1 1 37248 ultralytics.nn.modules.block.C2f [192, 64, 1]
17 -1 1 36992 ultralytics.nn.modules.conv.Conv [64, 64, 3, 2]
18 [-1, 13] 1 0 ultralytics.nn.modules.conv.Concat [1]
19 -1 1 123648 ultralytics.nn.modules.block.C2f [192, 128, 1]
20 -1 1 18048 ultralytics.nn.modules.block.SCDown [128, 128, 3, 2]
21 [-1, 10] 1 0 ultralytics.nn.modules.conv.Concat [1]
22 -1 1 282624 ultralytics.nn.modules.block.C2fCIB [384, 256, 1, True, True]
23 [16, 19, 22] 1 863668 ultralytics.nn.modules.head.v10Detect [6, [64, 128, 256]]
YOLOv10n summary: 385 layers, 2709380 parameters, 2709364 gradients, 8.4 GFLOPs
Transferred 493/595 items from pretrained weights
Freezing layer 'model.23.dfl.conv.weight'
AMP: running Automatic Mixed Precision (AMP) checks with YOLOv8n...
Downloading https://github.com/ultralytics/assets/releases/download/v8.1.0/yolov8n.pt to 'yolov8n.pt'...
需要下载yolov8的模型,v10是基于v8来重构造的
四、YOLO10检测SIXRay数据集
直接将SIXRay.yaml文件放入cfg/dataset中,加载预训练好的v10模型,即可训练:
from ultralytics import YOLOv10
model = YOLOv10(model='yolov10n.pt')
model.train(data='SIXRay.yaml', epochs=120, batch=64, imgsz=640)
/usr/bin/env /home/wqt/anaconda3/envs/yolov10/bin/python /home/wqt/.vscode/extensions/ms-python.debugpy-2024.8.0-linux-x64/bundled/libs/debugpy/adapter/../../debugpy/launcher 53853 -- /home/wqt/Projects/yolov10NEU/trainXRay.py
New https://pypi.org/project/ultralytics/8.2.78 available 😃 Update with 'pip install -U ultralytics'
Ultralytics YOLOv8.1.34 🚀 Python-3.9.19 torch-2.0.1+cu117 CUDA:0 (NVIDIA GeForce RTX 4090, 24209MiB)
engine/trainer: task=detect, mode=train, model=yolov10n.pt, data=SIXRay.yaml, epochs=120, time=None, patience=100, batch=64, imgsz=640, save=True, save_period=-1, val_period=1, cache=False, device=None, workers=8, project=None, name=train26, exist_ok=False, pretrained=True, optimizer=auto, verbose=True, seed=0, deterministic=True, single_cls=False, rect=False, cos_lr=False, close_mosaic=10, resume=False, amp=True, fraction=1.0, profile=False, freeze=None, multi_scale=False, overlap_mask=True, mask_ratio=4, dropout=0.0, val=True, split=val, save_json=False, save_hybrid=False, conf=None, iou=0.7, max_det=300, half=False, dnn=False, plots=True, source=None, vid_stride=1, stream_buffer=False, visualize=False, augment=False, agnostic_nms=False, classes=None, retina_masks=False, embed=None, show=False, save_frames=False, save_txt=False, save_conf=False, save_crop=False, show_labels=True, show_conf=True, show_boxes=True, line_width=None, format=torchscript, keras=False, optimize=False, int8=False, dynamic=False, simplify=False, opset=None, workspace=4, nms=False, lr0=0.01, lrf=0.01, momentum=0.937, weight_decay=0.0005, warmup_epochs=3.0, warmup_momentum=0.8, warmup_bias_lr=0.1, box=7.5, cls=0.5, dfl=1.5, pose=12.0, kobj=1.0, label_smoothing=0.0, nbs=64, hsv_h=0.015, hsv_s=0.7, hsv_v=0.4, degrees=0.0, translate=0.1, scale=0.5, shear=0.0, perspective=0.0, flipud=0.0, fliplr=0.5, bgr=0.0, mosaic=1.0, mixup=0.0, copy_paste=0.0, auto_augment=randaugment, erasing=0.4, crop_fraction=1.0, cfg=None, tracker=botsort.yaml, save_dir=/home/wqt/Projects/NEU-DET-with-yolov8/runs/detect/train26
Overriding model.yaml nc=80 with nc=6
from n params module arguments
0 -1 1 464 ultralytics.nn.modules.conv.Conv [3, 16, 3, 2]
1 -1 1 4672 ultralytics.nn.modules.conv.Conv [16, 32, 3, 2]
2 -1 1 7360 ultralytics.nn.modules.block.C2f [32, 32, 1, True]
3 -1 1 18560 ultralytics.nn.modules.conv.Conv [32, 64, 3, 2]
4 -1 2 49664 ultralytics.nn.modules.block.C2f [64, 64, 2, True]
5 -1 1 9856 ultralytics.nn.modules.block.SCDown [64, 128, 3, 2]
6 -1 2 197632 ultralytics.nn.modules.block.C2f [128, 128, 2, True]
7 -1 1 36096 ultralytics.nn.modules.block.SCDown [128, 256, 3, 2]
8 -1 1 460288 ultralytics.nn.modules.block.C2f [256, 256, 1, True]
9 -1 1 164608 ultralytics.nn.modules.block.SPPF [256, 256, 5]
10 -1 1 249728 ultralytics.nn.modules.block.PSA [256, 256]
11 -1 1 0 torch.nn.modules.upsampling.Upsample [None, 2, 'nearest']
12 [-1, 6] 1 0 ultralytics.nn.modules.conv.Concat [1]
13 -1 1 148224 ultralytics.nn.modules.block.C2f [384, 128, 1]
14 -1 1 0 torch.nn.modules.upsampling.Upsample [None, 2, 'nearest']
15 [-1, 4] 1 0 ultralytics.nn.modules.conv.Concat [1]
16 -1 1 37248 ultralytics.nn.modules.block.C2f [192, 64, 1]
17 -1 1 36992 ultralytics.nn.modules.conv.Conv [64, 64, 3, 2]
18 [-1, 13] 1 0 ultralytics.nn.modules.conv.Concat [1]
19 -1 1 123648 ultralytics.nn.modules.block.C2f [192, 128, 1]
20 -1 1 18048 ultralytics.nn.modules.block.SCDown [128, 128, 3, 2]
21 [-1, 10] 1 0 ultralytics.nn.modules.conv.Concat [1]
22 -1 1 282624 ultralytics.nn.modules.block.C2fCIB [384, 256, 1, True, True]
23 [16, 19, 22] 1 863668 ultralytics.nn.modules.head.v10Detect [6, [64, 128, 256]]
YOLOv10n summary: 385 layers, 2709380 parameters, 2709364 gradients, 8.4 GFLOPs
Transferred 493/595 items from pretrained weights
Freezing layer 'model.23.dfl.conv.weight'
AMP: running Automatic Mixed Precision (AMP) checks with YOLOv8n...
Downloading https://github.com/ultralytics/assets/releases/download/v8.1.0/yolov8n.pt to 'yolov8n.pt'...
100%|████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 6.23M/6.23M [00:03<00:00, 1.87MB/s]
AMP: checks passed ✅
train: Scanning /home/wqt/Projects/data/SIXRay/train/labels.cache... 5819 images, 13 backgrounds, 0 corrupt: 100%|██████████| 5819/5819 [00:00<?, ?it/s]
val: Scanning /home/wqt/Projects/data/SIXRay/valid/labels.cache... 1662 images, 2 backgrounds, 0 corrupt: 100%|██████████| 1662/1662 [00:00<?, ?it/s]
Plotting labels to /home/wqt/Projects/NEU-DET-with-yolov8/runs/detect/train26/labels.jpg...
optimizer: 'optimizer=auto' found, ignoring 'lr0=0.01' and 'momentum=0.937' and determining best 'optimizer', 'lr0' and 'momentum' automatically...
optimizer: SGD(lr=0.01, momentum=0.9) with parameter groups 95 weight(decay=0.0), 108 weight(decay=0.0005), 107 bias(decay=0.0)
Image sizes 640 train, 640 val
Using 8 dataloader workers
Logging results to /home/wqt/Projects/NEU-DET-with-yolov8/runs/detect/train26
Starting training for 120 epochs...
Epoch GPU_mem box_om cls_om dfl_om box_oo cls_oo dfl_oo Instances Size
1/120 11.6G 1.924 3.81 1.747 1.661 6.082 1.533 183 640: 100%|██████████| 91/91 [00:22<00:00, 4.11it/s]
Class Images Instances Box(P R mAP50 mAP50-95): 100%|██████████| 13/13 [00:03<00:00, 3.61it/s]
all 1662 3176 0.5 0.0969 0.177 0.0877
Epoch GPU_mem box_om cls_om dfl_om box_oo cls_oo dfl_oo Instances Size
2/120 11.7G 1.803 2.576 1.635 1.597 4.472 1.456 191 640: 100%|██████████| 91/91 [00:21<00:00, 4.23it/s]
Class Images Instances Box(P R mAP50 mAP50-95): 100%|██████████| 13/13 [00:03<00:00, 3.78it/s]
all 1662 3176 0.271 0.259 0.194 0.0874
Epoch GPU_mem box_om cls_om dfl_om box_oo cls_oo dfl_oo Instances Size
3/120 11.6G 1.828 2.46 1.703 1.71 3.447 1.569 185 640: 100%|██████████| 91/91 [00:21<00:00, 4.23it/s]
Class Images Instances Box(P R mAP50 mAP50-95): 100%|██████████| 13/13 [00:03<00:00, 4.14it/s]
all 1662 3176 0.214 0.214 0.163 0.064
注意点:
1、yolo10是基于yolo8重构的,所以先加载yolo8并没有错;
yolo10 & yolo8 检测XRay性能对比
这是yolo8检测XRay的性能结果如下所示:
100 epochs completed in 0.488 hours.
Validating /home/wqt/Projects/NEU-DET-with-yolov8/runs/detect/train7/weights/best.pt...
Ultralytics YOLOv8.2.31 🚀 Python-3.8.19 torch-2.3.1+cu121 CUDA:0
(NVIDIA GeForce RTX 4090, 24209MiB)
Model summary (fused): 168 layers, 3006818 parameters, 0 gradients, 8.1 GFLOPs
Class Images Instances Box(P R mAP50 mAP50-95):
all 1662 3176 0.923 0.838 0.904 0.664
gun 551 888 0.953 0.95 0.975 0.759
knife 291 442 0.921 0.801 0.885 0.634
wrench 794 1110 0.93 0.823 0.916 0.664
pliers 178 206 0.935 0.835 0.886 0.632
scissors 392 530 0.875 0.782 0.858 0.633
Speed: 0.1ms preprocess, 0.2ms inference, 0.0ms loss, 0.3ms postprocess per image
Results saved to /home/wqt/Projects/NEU-DET-with-yolov8/runs/detect/train7
yolo10检测XRay的性能结果如下所示:
#这是训练120次之后的效果
Validating /home/wqt/Projects/NEU-DET-with-yolov8/runs/detect/train26/weights/best.pt...
Ultralytics YOLOv8.1.34 🚀 Python-3.9.19 torch-2.0.1+cu117 CUDA:0 (NVIDIA GeForce RTX 4090, 24209MiB)
YOLOv10n summary (fused): 285 layers, 2696756 parameters, 0 gradients, 8.2 GFLOPs
Class Images Instances Box(P R mAP50 mAP50-95): 100%|██████████| 13/13 [00:04<00:00, 2.70it/s]
all 1662 3176 0.913 0.824 0.894 0.65
gun 1662 888 0.975 0.952 0.981 0.746
knife 1662 442 0.886 0.771 0.855 0.615
wrench 1662 1110 0.921 0.829 0.914 0.654
pliers 1662 206 0.948 0.835 0.902 0.633
scissors 1662 530 0.835 0.734 0.82 0.601
Speed: 0.5ms preprocess, 0.8ms inference, 0.0ms loss, 0.0ms postprocess per image
Results saved to /home/wqt/Projects/NEU-DET-with-yolov8/runs/detect/train26
#这是训练200次之后的效果
200 epochs completed in 1.448 hours.
Optimizer stripped from /home/wqt/Projects/yolov10NEU/runs/SIXRay/train_yolo10n_e200_b32_i640_/weights/best.pt, 5.8MB
Validating /home/wqt/Projects/yolov10NEU/runs/SIXRay/train_yolo10n_e200_b32_i640_/weights/best.pt...
Ultralytics YOLOv8.1.34 🚀 Python-3.9.19 torch-2.0.1+cu117 CUDA:0 (NVIDIA GeForce RTX 4090, 24209MiB)
YOLOv10n summary (fused): 285 layers, 2696756 parameters, 0 gradients, 8.2 GFLOPs
Class Images Instances Box(P R mAP50 mAP50-95): 100%|██████████| 26/26 [00:04<00:00, 6.42it/s]
all 1662 3176 0.926 0.834 0.9 0.665
gun 1662 888 0.975 0.952 0.981 0.745
knife 1662 442 0.909 0.766 0.865 0.633
wrench 1662 1110 0.932 0.835 0.916 0.665
pliers 1662 206 0.92 0.859 0.896 0.64
scissors 1662 530 0.893 0.758 0.845 0.64
Speed: 0.3ms preprocess, 0.8ms inference, 0.0ms loss, 0.0ms postprocess per image
Results saved to /home/wqt/Projects/yolov10NEU/runs/SIXRay/train_yolo10n_e200_b32_i640_
观察:
- 如果yolo10的跌宕训练次数不够,它的效果并没有比yolo8用在XRay上的检测效果好;并且检测速度也没有快;
- epoch=200,yolo10在通用的目标检测性能是最好的;但是用在特定的场景下,也能体现出来它的优越性;
改进YOLO10
尝试一:将原始的检测头修改为RT-DETR 的检测头
参考:https://blog.youkuaiyun.com/java1314777/article/details/140164724
修改点入口:

为了加入这个模块,并且需要加载之前训练好的Pretrain模型,我们需要在源文件中更改,打开ultralytics/engine/model.py,找到train方法,找到如下图这一行,并替换:

这样的作用,既能加载预训练好的权重,又能加入新的模块,也称之为“冻结训练”;
原始的错误脚本,是从YOLO10进入,容易报错:
NotImplementedError: WARNING ⚠️ ‘YOLO’ model does not support ‘_new’ mode for ‘None’ task yet.
from ultralytics import YOLOv10
model = YOLOv10('ultralytics/cfg/models/v10/yolov10nRTDETRHead.yaml').load('yolov10n.pt')
model.train(data='SIXRay.yaml', epochs=120, batch=32, imgsz=640)
我们将YOLO10入口替换为RT-DETR入口,即正确的训练脚本为:
from ultralytics import RTDETR
model = RTDETR('ultralytics/cfg/models/v10/yolov10nRTDETRHead.yaml').load('yolov10n.pt')
model.train(data='SIXRay.yaml', epochs=120, batch=32, imgsz=640)
训练过程如下:
Overriding model.yaml nc=80 with nc=6
from n params module arguments
0 -1 1 464 ultralytics.nn.modules.conv.Conv [3, 16, 3, 2]
1 -1 1 4672 ultralytics.nn.modules.conv.Conv [16, 32, 3, 2]
2 -1 1 7360 ultralytics.nn.modules.block.C2f [32, 32, 1, True]
3 -1 1 18560 ultralytics.nn.modules.conv.Conv [32, 64, 3, 2]
4 -1 2 49664 ultralytics.nn.modules.block.C2f [64, 64, 2, True]
5 -1 1 9856 ultralytics.nn.modules.block.SCDown [64, 128, 3, 2]
6 -1 2 197632 ultralytics.nn.modules.block.C2f [128, 128, 2, True]
7 -1 1 36096 ultralytics.nn.modules.block.SCDown [128, 256, 3, 2]
8 -1 1 460288 ultralytics.nn.modules.block.C2f [256, 256, 1, True]
9 -1 1 164608 ultralytics.nn.modules.block.SPPF [256, 256, 5]
10 -1 1 249728 ultralytics.nn.modules.block.PSA [256, 256]
11 -1 1 0 torch.nn.modules.upsampling.Upsample [None, 2, 'nearest']
12 [-1, 6] 1 0 ultralytics.nn.modules.conv.Concat [1]
13 -1 1 148224 ultralytics.nn.modules.block.C2f [384, 128, 1]
14 -1 1 0 torch.nn.modules.upsampling.Upsample [None, 2, 'nearest']
15 [-1, 4] 1 0 ultralytics.nn.modules.conv.Concat [1]
16 -1 1 37248 ultralytics.nn.modules.block.C2f [192, 64, 1]
17 -1 1 36992 ultralytics.nn.modules.conv.Conv [64, 64, 3, 2]
18 [-1, 13] 1 0 ultralytics.nn.modules.conv.Concat [1]
19 -1 1 123648 ultralytics.nn.modules.block.C2f [192, 128, 1]
20 -1 1 18048 ultralytics.nn.modules.block.SCDown [128, 128, 3, 2]
21 [-1, 10] 1 0 ultralytics.nn.modules.conv.Concat [1]
22 -1 1 282624 ultralytics.nn.modules.block.C2fCIB [384, 256, 1, True, True]
23 [16, 19, 22] 1 7232262 ultralytics.nn.modules.head.RTDETRDecoder [6, [64, 128, 256]]
YOLOv10nRTDETRHead summary: 405 layers, 9077974 parameters, 9077974 gradients, 16.5 GFLOPs
Transferred 554/569 items from pretrained weights
AMP: running Automatic Mixed Precision (AMP) checks with YOLOv8n...
AMP: checks passed ✅
train: Scanning /home/wqt/Projects/data/SIXRay/train/labels.cache... 5819 images, 13 backgrounds, 0 corrupt: 100%|██████████| 5819/5819 [00:00<?, ?it/s]
val: Scanning /home/wqt/Projects/data/SIXRay/valid/labels.cache... 1662 images, 2 backgrounds, 0 corrupt: 100%|██████████| 1662/1662 [00:00<?, ?it/s]
Plotting labels to /home/wqt/Projects/NEU-DET-with-yolov8/runs/detect/train29/labels.jpg...
optimizer: 'optimizer=auto' found, ignoring 'lr0=0.01' and 'momentum=0.937' and determining best 'optimizer', 'lr0' and 'momentum' automatically...
optimizer: SGD(lr=0.01, momentum=0.9) with parameter groups 81 weight(decay=0.0), 142 weight(decay=0.0005), 160 bias(decay=0.0)
Image sizes 640 train, 640 val
Using 8 dataloader workers
Logging results to /home/wqt/Projects/NEU-DET-with-yolov8/runs/detect/train29
Starting training for 120 epochs...
Epoch GPU_mem giou_loss cls_loss l1_loss Instances Size
0%| | 0/182 [00:00<?, ?it/s]/home/wqt/anaconda3/envs/yolov10/lib/python3.9/site-packages/torch/autograd/__init__.py:200: UserWarning: grid_sampler_2d_backward_cuda does not have a deterministic implementation, but you set 'torch.use_deterministic_algorithms(True, warn_only=True)'. You can file an issue at https://github.com/pytorch/pytorch/issues to help us prioritize adding deterministic support for this operation. (Triggered internally at ../aten/src/ATen/Context.cpp:71.)
Variable._execution_engine.run_backward( # Calls into the C++ engine to run the backward pass
1/120 14.5G 1.403 8.177 0.991 68 640: 100%|██████████| 182/182 [00:50<00:00, 3.63it/s]
Class Images Instances Box(P R mAP50 mAP50-95): 100%|██████████| 26/26 [00:05<00:00, 5.08it/s]
all 1662 3176 0.625 0.086 0.0244 0.00797
训练结果为:
120 epochs completed in 1.790 hours.
Optimizer stripped from /home/wqt/Projects/NEU-DET-with-yolov8/runs/detect/train29/weights/best.pt, 18.4MB
Validating /home/wqt/Projects/NEU-DET-with-yolov8/runs/detect/train29/weights/best.pt...
Ultralytics YOLOv8.1.34 🚀 Python-3.9.19 torch-2.0.1+cu117 CUDA:0 (NVIDIA GeForce RTX 4090, 24209MiB)
YOLOv10nRTDETRHead summary: 345 layers, 9068166 parameters, 0 gradients, 16.4 GFLOPs
Class Images Instances Box(P R mAP50 mAP50-95): 100%|██████████| 26/26 [00:06<00:00, 3.80it/s]
all 1662 3176 0.902 0.81 0.888 0.649
gun 1662 888 0.96 0.943 0.977 0.752
knife 1662 442 0.879 0.776 0.856 0.642
wrench 1662 1110 0.908 0.816 0.911 0.652
pliers 1662 206 0.901 0.811 0.872 0.583
scissors 1662 530 0.862 0.706 0.824 0.614
Speed: 0.4ms preprocess, 1.8ms inference, 0.0ms loss, 0.2ms postprocess per image
Results saved to /home/wqt/Projects/NEU-DET-with-yolov8/runs/detect/train29
修改epoch=200重新训练
200 epochs completed in 2.948 hours.
Optimizer stripped from /home/wqt/Projects/yolov10NEU/runs/SIXRay/train_yolo10nRTHead_e200_b32_i640_/weights/best.pt, 18.4MB
Validating /home/wqt/Projects/yolov10NEU/runs/SIXRay/train_yolo10nRTHead_e200_b32_i640_/weights/best.pt...
Ultralytics YOLOv8.1.34 🚀 Python-3.9.19 torch-2.0.1+cu117 CUDA:0 (NVIDIA GeForce RTX 4090, 24209MiB)
YOLOv10nRTDETRHead summary: 345 layers, 9068166 parameters, 0 gradients, 16.4 GFLOPs
Class Images Instances Box(P R mAP50 mAP50-95): 100%|██████████| 26/26 [00:06<00:00, 4.01it/s]
all 1662 3176 0.921 0.835 0.906 0.675
gun 1662 888 0.975 0.962 0.98 0.766
knife 1662 442 0.907 0.792 0.87 0.654
wrench 1662 1110 0.936 0.831 0.919 0.675
pliers 1662 206 0.913 0.819 0.886 0.619
scissors 1662 530 0.874 0.774 0.873 0.661
Speed: 0.4ms preprocess, 1.7ms inference, 0.0ms loss, 0.2ms postprocess per image
Results saved to /home/wqt/Projects/yolov10NEU/runs/SIXRay/train_yolo10nRTHead_e200_b32_i640_
结论:1、YOLO10+RT-Head的改进使得mAP提升到67.5%;
修改epoch=200重新训练,预训练模型为:train_yolo10nRTHead_e200_b32_i640_/weights/best.pt
200 epochs completed in 2.937 hours.
Optimizer stripped from /home/wqt/Projects/yolov10NEU/runs/SIXRay/train_yolo10nRTHead_e200_b32_i640_2/weights/best.pt, 18.4MB
Validating /home/wqt/Projects/yolov10NEU/runs/SIXRay/train_yolo10nRTHead_e200_b32_i640_2/weights/best.pt...
Ultralytics YOLOv8.1.34 🚀 Python-3.9.19 torch-2.0.1+cu117 CUDA:0 (NVIDIA GeForce RTX 4090, 24209MiB)
YOLOv10nRTDETRHead summary: 345 layers, 9068166 parameters, 0 gradients, 16.4 GFLOPs
Class Images Instances Box(P R mAP50 mAP50-95): 100%|██████████| 26/26 [00:06<00:00, 4.02it/s]
all 1662 3176 0.931 0.866 0.916 0.689
gun 1662 888 0.976 0.967 0.985 0.769
knife 1662 442 0.915 0.827 0.875 0.669
wrench 1662 1110 0.935 0.858 0.928 0.687
pliers 1662 206 0.923 0.869 0.901 0.645
scissors 1662 530 0.906 0.808 0.892 0.675
Speed: 0.4ms preprocess, 1.7ms inference, 0.0ms loss, 0.2ms postprocess per image
Results saved to /home/wqt/Projects/yolov10NEU/runs/SIXRay/train_yolo10nRTHead_e200_b32_i640_2
尝试二: 魔改注意力进行二次创新,使用EMA高效替换PSA
EMA的讲解参考:https://cloud.tencent.com/developer/article/2426593
EMA的使用参考:https://blog.youkuaiyun.com/ShawN1022/article/details/132854884
训练过程如下:
from n params module arguments
0 -1 1 464 ultralytics.nn.modules.conv.Conv [3, 16, 3, 2]
1 -1 1 4672 ultralytics.nn.modules.conv.Conv [16, 32, 3, 2]
2 -1 1 7360 ultralytics.nn.modules.block.C2f [32, 32, 1, True]
3 -1 1 18560 ultralytics.nn.modules.conv.Conv [32, 64, 3, 2]
4 -1 2 49664 ultralytics.nn.modules.block.C2f [64, 64, 2, True]
5 -1 1 9856 ultralytics.nn.modules.block.SCDown [64, 128, 3, 2]
6 -1 2 197632 ultralytics.nn.modules.block.C2f [128, 128, 2, True]
7 -1 1 36096 ultralytics.nn.modules.block.SCDown [128, 256, 3, 2]
8 -1 1 460288 ultralytics.nn.modules.block.C2f [256, 256, 1, True]
9 -1 1 164608 ultralytics.nn.modules.block.SPPF [256, 256, 5]
10 -1 1 672 ultralytics.nn.modules.block.EMA [256, 256]
备注:此处EMA替代了原来的PSA。
11 -1 1 0 torch.nn.modules.upsampling.Upsample [None, 2, 'nearest']
12 [-1, 6] 1 0 ultralytics.nn.modules.conv.Concat [1]
13 -1 1 148224 ultralytics.nn.modules.block.C2f [384, 128, 1]
14 -1 1 0 torch.nn.modules.upsampling.Upsample [None, 2, 'nearest']
15 [-1, 4] 1 0 ultralytics.nn.modules.conv.Concat [1]
16 -1 1 37248 ultralytics.nn.modules.block.C2f [192, 64, 1]
17 -1 1 36992 ultralytics.nn.modules.conv.Conv [64, 64, 3, 2]
18 [-1, 13] 1 0 ultralytics.nn.modules.conv.Concat [1]
19 -1 1 123648 ultralytics.nn.modules.block.C2f [192, 128, 1]
20 -1 1 18048 ultralytics.nn.modules.block.SCDown [128, 128, 3, 2]
21 [-1, 10] 1 0 ultralytics.nn.modules.conv.Concat [1]
22 -1 1 282624 ultralytics.nn.modules.block.C2fCIB [384, 256, 1, True, True]
23 [16, 19, 22] 1 7232262 ultralytics.nn.modules.head.RTDETRDecoder [6, [64, 128, 256]]
YOLOv10nRTDETRHead_EMA summary: 385 layers, 8828918 parameters, 8828918 gradients, 16.3 GFLOPs
Transferred 518/533 items from pretrained weights
AMP: running Automatic Mixed Precision (AMP) checks with YOLOv8n...
AMP: checks passed ✅
train: Scanning /home/wqt/Projects/data/SIXRay/train/labels.cache... 5819 images, 13 backgrounds, 0 corrupt: 100%|██████████| 5819/5819 [00:00<?, ?it/s]
val: Scanning /home/wqt/Projects/data/SIXRay/valid/labels.cache... 1662 images, 2 backgrounds, 0 corrupt: 100%|██████████| 1662/1662 [00:00<?, ?it/s]
Plotting labels to /home/wqt/Projects/NEU-DET-with-yolov8/runs/detect/train30/labels.jpg...
optimizer: 'optimizer=auto' found, ignoring 'lr0=0.01' and 'momentum=0.937' and determining best 'optimizer', 'lr0' and 'momentum' automatically...
optimizer: SGD(lr=0.01, momentum=0.9) with parameter groups 75 weight(decay=0.0), 137 weight(decay=0.0005), 156 bias(decay=0.0)
Image sizes 640 train, 640 val
Using 8 dataloader workers
Logging results to /home/wqt/Projects/NEU-DET-with-yolov8/runs/detect/train30
Starting training for 120 epochs...
Epoch GPU_mem giou_loss cls_loss l1_loss Instances Size
0%| | 0/182 [00:00<?, ?it/s]/home/wqt/anaconda3/envs/yolov10/lib/python3.9/site-packages/torch/autograd/__init__.py:200: UserWarning: grid_sampler_2d_backward_cuda does not have a deterministic implementation, but you set 'torch.use_deterministic_algorithms(True, warn_only=True)'. You can file an issue at https://github.com/pytorch/pytorch/issues to help us prioritize adding deterministic support for this operation. (Triggered internally at ../aten/src/ATen/Context.cpp:71.)
Variable._execution_engine.run_backward( # Calls into the C++ engine to run the backward pass
/home/wqt/anaconda3/envs/yolov10/lib/python3.9/site-packages/torch/autograd/__init__.py:200: UserWarning: adaptive_avg_pool2d_backward_cuda does not have a deterministic implementation, but you set 'torch.use_deterministic_algorithms(True, warn_only=True)'. You can file an issue at https://github.com/pytorch/pytorch/issues to help us prioritize adding deterministic support for this operation. (Triggered internally at ../aten/src/ATen/Context.cpp:71.)
Variable._execution_engine.run_backward( # Calls into the C++ engine to run the backward pass
1/120 14.4G 1.375 8.785 0.9605 68 640: 100%|██████████| 182/182 [00:49<00:00, 3.71it/s]
Class Images Instances Box(P R mAP50 mAP50-95): 100%|██████████| 26/26 [00:04<00:00, 5.21it/s]
all 1662 3176 0.23 0.125 0.0278 0.00899
训练结果如下:
epoch=120:
Validating /home/wqt/Projects/NEU-DET-with-yolov8/runs/detect/train30/weights/best.pt...
Ultralytics YOLOv8.1.34 🚀 Python-3.9.19 torch-2.0.1+cu117 CUDA:0 (NVIDIA GeForce RTX 4090, 24209MiB)
YOLOv10nRTDETRHead_EMA summary: 332 layers, 8820518 parameters, 0 gradients, 16.2 GFLOPs
Class Images Instances Box(P R mAP50 mAP50-95): 100%|██████████| 26/26 [00:06<00:00, 3.96it/s]
all 1662 3176 0.904 0.791 0.888 0.65
gun 1662 888 0.963 0.937 0.978 0.748
knife 1662 442 0.892 0.735 0.852 0.633
wrench 1662 1110 0.91 0.795 0.897 0.642
pliers 1662 206 0.889 0.781 0.882 0.6
scissors 1662 530 0.864 0.705 0.833 0.626
Speed: 0.4ms preprocess, 1.7ms inference, 0.0ms loss, 0.2ms postprocess per image
Results saved to /home/wqt/Projects/NEU-DET-with-yolov8/runs/detect/train30
pretrained model: 从yolo10改为
load('/home/wqt/Projects/yolov10NEU/runs/SIXRay/train_yolo10nRTHead_e200_b32_i640_/weights/best.pt'
200 epochs completed in 2.931 hours.
Optimizer stripped from /home/wqt/Projects/yolov10NEU/runs/SIXRay/train_yolo10nRTHead_EMA_e200_b32_i640_/weights/best.pt, 17.9MB
Validating /home/wqt/Projects/yolov10NEU/runs/SIXRay/train_yolo10nRTHead_EMA_e200_b32_i640_/weights/best.pt...
Ultralytics YOLOv8.1.34 🚀 Python-3.9.19 torch-2.0.1+cu117 CUDA:0 (NVIDIA GeForce RTX 4090, 24209MiB)
YOLOv10nRTDETRHead_EMA summary: 332 layers, 8820518 parameters, 0 gradients, 16.2 GFLOPs
Class Images Instances Box(P R mAP50 mAP50-95): 100%|██████████| 26/26 [00:06<00:00, 3.93it/s]
all 1662 3176 0.929 0.859 0.914 0.69
gun 1662 888 0.974 0.959 0.981 0.769
knife 1662 442 0.896 0.808 0.864 0.659
wrench 1662 1110 0.928 0.857 0.927 0.687
pliers 1662 206 0.925 0.864 0.903 0.655
scissors 1662 530 0.921 0.808 0.896 0.679
Speed: 0.4ms preprocess, 1.8ms inference, 0.0ms loss, 0.2ms postprocess per image
Results saved to /home/wqt/Projects/yolov10NEU/runs/SIXRay/train_yolo10nRTHead_EMA_e200_b32_i640_
结果:这样的提升变为69的mAP。
尝试三: 魔改注意力进行二次创新,使用EMA*N增加注意力。
EMA的使用参考:https://blog.youkuaiyun.com/ShawN1022/article/details/132854884
训练过程如下:
from n params module arguments
0 -1 1 464 ultralytics.nn.modules.conv.Conv [3, 16, 3, 2]
1 -1 1 4672 ultralytics.nn.modules.conv.Conv [16, 32, 3, 2]
2 -1 1 7360 ultralytics.nn.modules.block.C2f [32, 32, 1, True]
3 -1 1 18560 ultralytics.nn.modules.conv.Conv [32, 64, 3, 2]
4 -1 2 49664 ultralytics.nn.modules.block.C2f [64, 64, 2, True]
5 -1 1 9856 ultralytics.nn.modules.block.SCDown [64, 128, 3, 2]
6 -1 2 197632 ultralytics.nn.modules.block.C2f [128, 128, 2, True]
7 -1 1 36096 ultralytics.nn.modules.block.SCDown [128, 256, 3, 2]
8 -1 1 460288 ultralytics.nn.modules.block.C2f [256, 256, 1, True]
9 -1 1 164608 ultralytics.nn.modules.block.SPPF [256, 256, 5]
10 -1 1 249728 ultralytics.nn.modules.block.PSA [256, 256]
11 -1 1 0 torch.nn.modules.upsampling.Upsample [None, 2, 'nearest']
12 [-1, 6] 1 0 ultralytics.nn.modules.conv.Concat [1]
13 -1 1 148224 ultralytics.nn.modules.block.C2f [384, 128, 1]
14 -1 1 0 torch.nn.modules.upsampling.Upsample [None, 2, 'nearest']
15 [-1, 4] 1 0 ultralytics.nn.modules.conv.Concat [1]
16 -1 1 37248 ultralytics.nn.modules.block.C2f [192, 64, 1]
17 -1 1 48 ultralytics.nn.modules.block.EMA [64, 64]
18 -1 1 36992 ultralytics.nn.modules.conv.Conv [64, 64, 3, 2]
19 [-1, 13] 1 0 ultralytics.nn.modules.conv.Concat [1]
20 -1 1 123648 ultralytics.nn.modules.block.C2f [192, 128, 1]
21 -1 1 176 ultralytics.nn.modules.block.EMA [128, 128]
22 -1 1 18048 ultralytics.nn.modules.block.SCDown [128, 128, 3, 2]
23 [-1, 10] 1 0 ultralytics.nn.modules.conv.Concat [1]
24 -1 1 282624 ultralytics.nn.modules.block.C2fCIB [384, 256, 1, True, True]
25 -1 1 672 ultralytics.nn.modules.block.EMA [256, 256]
26 [17, 21, 25] 1 7232262 ultralytics.nn.modules.head.RTDETRDecoder [6, [64, 128, 256]]
YOLOv10nRTDETRHead_EMAN summary: 429 layers, 9078870 parameters, 9078870 gradients, 16.6 GFLOPs
Transferred 572/587 items from pretrained weights
AMP: running Automatic Mixed Precision (AMP) checks with YOLOv8n...
AMP: checks passed ✅
train: Scanning /home/wqt/Projects/data/SIXRay/train/labels.cache... 5819 images, 13 backgrounds, 0 corrupt: 100%|██████████| 5819/5819 [00:00<?, ?it/s]
val: Scanning /home/wqt/Projects/data/SIXRay/valid/labels.cache... 1662 images, 2 backgrounds, 0 corrupt: 100%|██████████| 1662/1662 [00:00<?, ?it/s]
Plotting labels to /home/wqt/Projects/yolov10NEU/runs/SIXRay/train_yolo10nRTHead_EMAN_e400_b32_i640_4/labels.jpg...
optimizer: 'optimizer=auto' found, ignoring 'lr0=0.01' and 'momentum=0.937' and determining best 'optimizer', 'lr0' and 'momentum' automatically...
optimizer: SGD(lr=0.01, momentum=0.9) with parameter groups 84 weight(decay=0.0), 148 weight(decay=0.0005), 169 bias(decay=0.0)
Image sizes 640 train, 640 val
Using 8 dataloader workers
Logging results to /home/wqt/Projects/yolov10NEU/runs/SIXRay/train_yolo10nRTHead_EMAN_e400_b32_i640_4
Starting training for 400 epochs...
训练结果如下:
Validating /home/wqt/Projects/NEU-DET-with-yolov8/runs/detect/train30/weights/best.pt...
Ultralytics YOLOv8.1.34 🚀 Python-3.9.19 torch-2.0.1+cu117 CUDA:0 (NVIDIA GeForce RTX 4090, 24209MiB)
YOLOv10nRTDETRHead_EMA summary: 332 layers, 8820518 parameters, 0 gradients, 16.2 GFLOPs
Class Images Instances Box(P R mAP50 mAP50-95): 100%|██████████| 26/26 [00:06<00:00, 3.96it/s]
all 1662 3176 0.904 0.791 0.888 0.65
gun 1662 888 0.963 0.937 0.978 0.748
knife 1662 442 0.892 0.735 0.852 0.633
wrench 1662 1110 0.91 0.795 0.897 0.642
pliers 1662 206 0.889 0.781 0.882 0.6
scissors 1662 530 0.864 0.705 0.833 0.626
Speed: 0.4ms preprocess, 1.7ms inference, 0.0ms loss, 0.2ms postprocess per image
Results saved to /home/wqt/Projects/NEU-DET-with-yolov8/runs/detect/train30
修改epoch=400重新训练,预训练模型为:train_yolo10nRTHead_e200_b32_i640_/weights/best.pt
训练结果如下:
/home/wqt/anaconda3/envs/yolov10/lib/python3.9/site-packages/torch/autograd/__init__.py:200: UserWarning: adaptive_avg_pool2d_backward_cuda does not have a deterministic implementation, but you set 'torch.use_deterministic_algorithms(True, warn_only=True)'. You can file an issue at https://github.com/pytorch/pytorch/issues to help us prioritize adding deterministic support for this operation. (Triggered internally at ../aten/src/ATen/Context.cpp:71.)
Variable._execution_engine.run_backward( # Calls into the C++ engine to run the backward pass
269/400 13.5G 0.3126 0.5049 0.1545 98 640: 100%|██████████| 182/182 [00:48<00:00, 3.75it/s]
Class Images Instances Box(P R mAP50 mAP50-95): 100%|██████████| 26/26 [00:05<00:00, 4.91it/s]
all 1662 3176 0.926 0.862 0.912 0.665
Stopping training early as no improvement observed in last 100 epochs. Best results observed at epoch 169, best model saved as best.pt.
To update EarlyStopping(patience=100) pass a new patience value, i.e. `patience=300` or use `patience=0` to disable EarlyStopping.
269 epochs completed in 4.100 hours.
Optimizer stripped from /home/wqt/Projects/yolov10NEU/runs/SIXRay/train_yolo10nRTHead_EMAN_e400_b32_i640_4/weights/last.pt, 18.5MB
Optimizer stripped from /home/wqt/Projects/yolov10NEU/runs/SIXRay/train_yolo10nRTHead_EMAN_e400_b32_i640_4/weights/best.pt, 18.5MB
Validating /home/wqt/Projects/yolov10NEU/runs/SIXRay/train_yolo10nRTHead_EMAN_e400_b32_i640_4/weights/best.pt...
Ultralytics YOLOv8.1.34 🚀 Python-3.9.19 torch-2.0.1+cu117 CUDA:0 (NVIDIA GeForce RTX 4090, 24209MiB)
YOLOv10nRTDETRHead_EMAN summary: 369 layers, 9069062 parameters, 0 gradients, 16.4 GFLOPs
Class Images Instances Box(P R mAP50 mAP50-95): 100%|██████████| 26/26 [00:06<00:00, 3.93it/s]
all 1662 3176 0.918 0.858 0.91 0.672
gun 1662 888 0.975 0.959 0.982 0.751
knife 1662 442 0.892 0.81 0.863 0.636
wrench 1662 1110 0.943 0.843 0.923 0.682
pliers 1662 206 0.893 0.854 0.895 0.64
scissors 1662 530 0.89 0.821 0.887 0.653
Speed: 0.4ms preprocess, 1.8ms inference, 0.0ms loss, 0.2ms postprocess per image
Results saved to /home/wqt/Projects/yolov10NEU/runs/SIXRay/train_yolo10nRTHead_EMAN_e400_b32_i640_4
尝试四:YOLOv10全网最新创新点改进系列: 添加KAN
参考:https://github.com/danielsyahputra/ultralytics/blob/main/ultralytics/nn/modules/conv.py
在conv. block.等文件中添加KAN模块,修改ymal添加ConvWithKAN,开始训练:
from n params module arguments
0 -1 1 464 ultralytics.nn.modules.conv.Conv [3, 16, 3, 2]
1 -1 1 4672 ultralytics.nn.modules.conv.Conv [16, 32, 3, 2]
2 -1 1 7360 ultralytics.nn.modules.block.C2f [32, 32, 1, True]
3 -1 1 18560 ultralytics.nn.modules.conv.Conv [32, 64, 3, 2]
4 -1 2 49664 ultralytics.nn.modules.block.C2f [64, 64, 2, True]
5 -1 1 9856 ultralytics.nn.modules.block.SCDown [64, 128, 3, 2]
6 -1 2 197632 ultralytics.nn.modules.block.C2f [128, 128, 2, True]
7 -1 1 36096 ultralytics.nn.modules.block.SCDown [128, 256, 3, 2]
8 -1 1 460288 ultralytics.nn.modules.block.C2f [256, 256, 1, True]
9 -1 1 164608 ultralytics.nn.modules.block.SPPF [256, 256, 5]
10 -1 1 672 ultralytics.nn.modules.block.EMA [256, 256]
11 -1 1 0 torch.nn.modules.upsampling.Upsample [None, 2, 'nearest']
12 [-1, 6] 1 0 ultralytics.nn.modules.conv.Concat [1]
13 -1 1 148224 ultralytics.nn.modules.block.C2f [384, 128, 1]
14 -1 1 0 torch.nn.modules.upsampling.Upsample [None, 2, 'nearest']
15 [-1, 4] 1 0 ultralytics.nn.modules.conv.Concat [1]
16 -1 1 37248 ultralytics.nn.modules.block.C2f [192, 64, 1]
17 -1 1 36992 ultralytics.nn.modules.conv.Conv [64, 64, 3, 2]
18 [-1, 13] 1 0 ultralytics.nn.modules.conv.Concat [1]
19 -1 1 320776 ultralytics.nn.modules.block.C2fKAN [192, 128, 1]
20 -1 1 18048 ultralytics.nn.modules.block.SCDown [128, 128, 3, 2]
21 [-1, 10] 1 0 ultralytics.nn.modules.conv.Concat [1]
22 -1 1 282624 ultralytics.nn.modules.block.C2fCIB [384, 256, 1, True, True]
23 [16, 19, 22] 1 7232262 ultralytics.nn.modules.head.RTDETRDecoder [6, [64, 128, 256]]
YOLOv10nRTDETRHead_EMA_KAN summary: 391 layers, 9026046 parameters, 9026038 gradients, 16.3 GFLOPs
Transferred 526/541 items from pretrained weights
WARNING ⚠️ setting 'requires_grad=True' for frozen layer 'model.19.cv2.conv.rbf.grid'. See ultralytics.engine.trainer for customization of frozen layers.
AMP: running Automatic Mixed Precision (AMP) checks with YOLOv8n...
AMP: checks passed ✅
train: Scanning /home/wqt/Projects/data/SIXRay/train/labels.cache... 5819 images, 13 backgrounds, 0 corrupt: 100%|██████████| 5819/5819 [00:00<?, ?it/s]
val: Scanning /home/wqt/Projects/data/SIXRay/valid/labels.cache... 1662 images, 2 backgrounds, 0 corrupt: 100%|██████████| 1662/1662 [00:00<?, ?it/s]
Plotting labels to /home/wqt/Projects/yolov10NEU/runs/SIXRay/train_yolo10nRTHead_EMA_KAN_e300_b32_i640_/labels.jpg...
optimizer: 'optimizer=auto' found, ignoring 'lr0=0.01' and 'momentum=0.937' and determining best 'optimizer', 'lr0' and 'momentum' automatically...
optimizer: SGD(lr=0.01, momentum=0.9) with parameter groups 75 weight(decay=0.0), 141 weight(decay=0.0005), 160 bias(decay=0.0)
Image sizes 640 train, 640 val
Using 8 dataloader workers
Logging results to /home/wqt/Projects/yolov10NEU/runs/SIXRay/train_yolo10nRTHead_EMA_KAN_e300_b32_i640_
Starting training for 300 epochs...
Epoch GPU_mem giou_loss cls_loss l1_loss Instances Size
0%| | 0/182 [00:00<?, ?it/s]/home/wqt/anaconda3/envs/yolov10/lib/python3.9/site-packages/torch/autograd/__init__.py:200:
1/300 15.2G 0.4525 11.47 0.2303 68 640: 100%|██████████| 182/182 [00:52<00:00, 3.46it/s]
Class Images Instances Box(P R mAP50 mAP50-95): 100%|██████████| 26/26 [00:05<00:00, 4.83it/s]
all 1662 3176 0.895 0.812 0.872 0.611
最终训练结果如下:
Variable._execution_engine.run_backward( # Calls into the C++ engine to run the backward pass
300/300 13.8G 0.1809 0.2897 0.1072 52 640: 100%|██████████| 182/182 [00:48<00:00, 3.72it/s]
Class Images Instances Box(P R mAP50 mAP50-95): 100%|██████████| 26/26 [00:05<00:00, 4.87it/s]
all 1662 3176 0.934 0.858 0.914 0.69
300 epochs completed in 4.592 hours.
Optimizer stripped from /home/wqt/Projects/yolov10NEU/runs/SIXRay/train_yolo10nRTHead_EMA_KAN_e300_b32_i640_/weights/last.pt, 18.3MB
Optimizer stripped from /home/wqt/Projects/yolov10NEU/runs/SIXRay/train_yolo10nRTHead_EMA_KAN_e300_b32_i640_/weights/best.pt, 18.3MB
Validating /home/wqt/Projects/yolov10NEU/runs/SIXRay/train_yolo10nRTHead_EMA_KAN_e300_b32_i640_/weights/best.pt...
Ultralytics YOLOv8.1.34 🚀 Python-3.9.19 torch-2.0.1+cu117 CUDA:0 (NVIDIA GeForce RTX 4090, 24209MiB)
YOLOv10nRTDETRHead_EMA_KAN summary: 340 layers, 9017902 parameters, 0 gradients, 16.2 GFLOPs
Class Images Instances Box(P R mAP50 mAP50-95): 100%|██████████| 26/26 [00:06<00:00, 3.93it/s]
all 1662 3176 0.928 0.863 0.914 0.69
gun 1662 888 0.977 0.956 0.982 0.772
knife 1662 442 0.91 0.828 0.885 0.662
wrench 1662 1110 0.936 0.851 0.927 0.697
pliers 1662 206 0.908 0.854 0.884 0.631
scissors 1662 530 0.908 0.824 0.894 0.689
Speed: 0.4ms preprocess, 1.8ms inference, 0.0ms loss, 0.2ms postprocess per image
Results saved to /home/wqt/Projects/yolov10NEU/runs/SIXRay/train_yolo10nRTHead_EMA_KAN_e300_b32_i640_
尝试5:train_yolo10nRTHead_EMA_KAN增大容量至RT-DETRX模型
这是small-版本的检测结果
Validating /home/wqt/Projects/yolov10NEU/runs/SIXRay/train_yolo10nRTHead_EMA_KAN_BBoard_e300_b32_i640_2/weights/best.pt...
Ultralytics YOLOv8.1.34 🚀 Python-3.9.19 torch-2.0.1+cu117 CUDA:0 (NVIDIA GeForce RTX 4090, 24209MiB)
YOLOv10nRTDETRHead_EMA_KAN summary: 340 layers, 9030232 parameters, 0 gradients, 16.2 GFLOPs
Class Images Instances Box(P R mAP50 mAP50-95): 100%|██████████| 79/79 [00:18<00:00, 4.33it/s]
all 5000 6390 0.986 0.971 0.986 0.886
powerbank 5000 75 0.996 1 0.995 0.854
mobilephone 5000 522 0.999 1 0.995 0.956
battery 5000 914 0.993 0.989 0.995 0.823
scissors 5000 130 0.982 1 0.995 0.891
fruitknife 5000 50 0.972 1 0.993 0.912
cleaver 5000 90 0.986 1 0.994 0.94
suspiciousliquid1 5000 4035 0.991 0.993 0.995 0.917
suspiciousliquid2 5000 498 0.984 0.998 0.995 0.892
lighter 5000 22 1 0.678 0.897 0.608
handcuffs 5000 22 0.986 1 0.995 0.95
expandablebatons 5000 17 0.974 1 0.995 0.939
pressure 5000 15 0.964 1 0.995 0.947
Speed: 0.2ms preprocess, 1.9ms inference, 0.0ms loss, 0.1ms postprocess per image
Results saved to /home/wqt/Projects/yolov10NEU/runs/SIXRay/train_yolo10nRTHead_EMA_KAN_BBoard_e300_b32_i640_2
检测速度如下:
image 1/1 /home/wqt/Projects/data/BBoardXRay/B_test/pro00033110.jpg: 640x640 1 mobilephone, 17.3ms
Speed: 1.4ms preprocess, 17.3ms inference, 0.3ms postprocess per image at shape (1, 3, 640, 640)
image 1/1 /home/wqt/Projects/data/BBoardXRay/B_test/pro00010215.jpg: 640x640 1 mobilephone, 17.8ms
Speed: 1.3ms preprocess, 17.8ms inference, 0.8ms postprocess per image at shape (1, 3, 640, 640)
image 1/1 /home/wqt/Projects/data/BBoardXRay/B_test/pro00007724.jpg: 640x640 2 suspiciousliquid1s, 17.4ms
Speed: 1.2ms preprocess, 17.4ms inference, 0.3ms postprocess per image at shape (1, 3, 640, 640)
XML files are generated and zipped into B_Output.zip
这是X-版本的检测结果
#这是使用X-版本的结果:0.886直接干到96.2%
300/300 21G 0.06637 0.143 0.05596 9 640: 100%|██████████| 313/313 [02:56<00:00, 1.77it/s]
Class Images Instances Box(P R mAP50 mAP50-95): 100%|██████████| 157/157 [00:51<00:00, 3.08it/s]
all 5000 6390 0.988 0.982 0.993 0.962
300 epochs completed in 19.087 hours.
Validating /home/wqt/Projects/yolov10NEU/runs/SIXRay/train_yolo10xRTHead_EMA_KAN_BBoard_e300_b16_i640_/weights/best.pt...
Ultralytics YOLOv8.1.34 🚀 Python-3.9.19 torch-2.0.1+cu117 CUDA:0 (NVIDIA GeForce RTX 4090, 24209MiB)
YOLOv10xRTDETRHead_EMA_KAN summary: 456 layers, 61151592 parameters, 0 gradients, 220.1 GFLOPs
Class Images Instances Box(P R mAP50 mAP50-95): 100%|██████████| 157/157 [00:51<00:00, 3.05it/s]
all 5000 6390 0.989 0.983 0.993 0.962
powerbank 5000 75 0.998 1 0.995 0.966
mobilephone 5000 522 1 1 0.995 0.993
battery 5000 914 1 0.991 0.995 0.949
scissors 5000 130 0.998 0.992 0.995 0.974
fruitknife 5000 50 0.996 1 0.995 0.969
cleaver 5000 90 0.995 1 0.995 0.971
suspiciousliquid1 5000 4035 0.996 0.995 0.995 0.976
suspiciousliquid2 5000 498 0.995 0.994 0.995 0.964
lighter 5000 22 0.907 0.818 0.968 0.851
handcuffs 5000 22 0.993 1 0.995 0.957
expandablebatons 5000 17 0.991 1 0.995 0.984
pressure 5000 15 0.995 1 0.995 0.987
Speed: 0.2ms preprocess, 8.6ms inference, 0.0ms loss, 0.1ms postprocess per image
Results saved to /home/wqt/Projects/yolov10NEU/runs/SIXRay/train_yolo10xRTHead_EMA_KAN_BBoard_e300_b16_i640_
检测速度如下:
image 1/1 /home/wqt/Projects/data/BBoardXRay/B_test/pro00015758.jpg: 640x640 1 battery, 30.1ms
Speed: 1.3ms preprocess, 30.1ms inference, 0.3ms postprocess per image at shape (1, 3, 640, 640)
image 1/1 /home/wqt/Projects/data/BBoardXRay/B_test/pro00008281.jpg: 640x640 3 batterys, 30.2ms
Speed: 1.3ms preprocess, 30.2ms inference, 0.3ms postprocess per image at shape (1, 3, 640, 640)
尝试X:YOLOv10全网最新创新点改进系列:融合空间信息关注机制(SimAM)
参考:https://blog.youkuaiyun.com/weixin_51692073/article/details/139310653
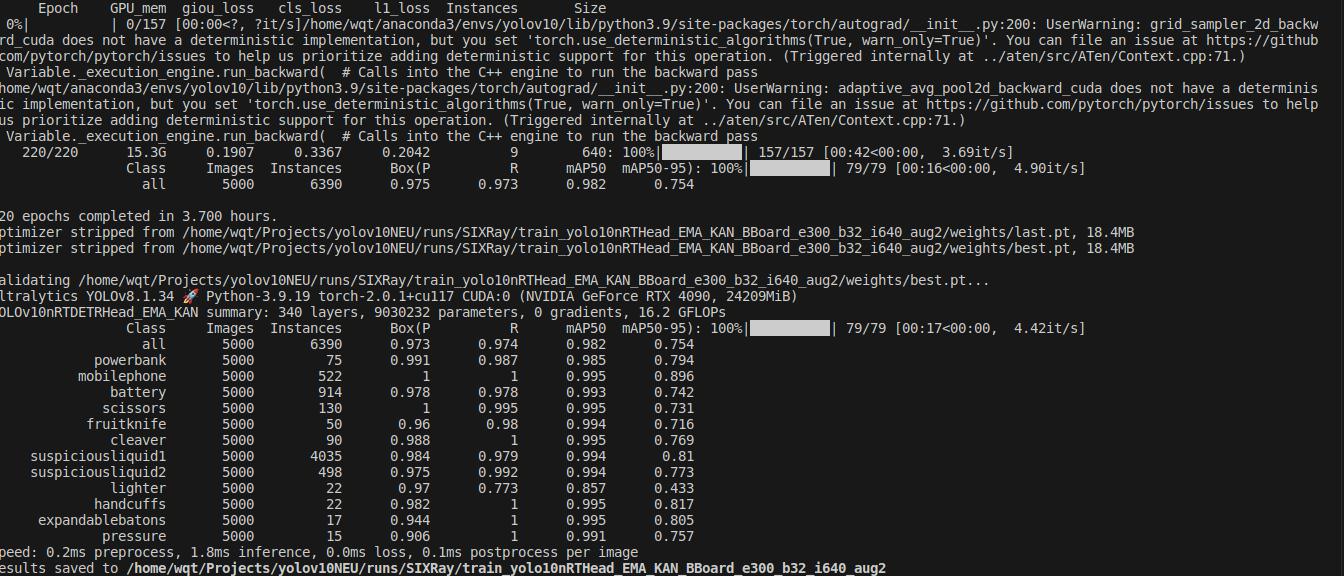
Validating /home/wqt/Projects/yolov10NEU/runs/SIXRay/train_yolo10nRTHead_EMA_KAN_BBoard_e300_b32_i640_aug2/weights/best.pt...
Ultralytics YOLOv8.1.34 🚀 Python-3.9.19 torch-2.0.1+cu117 CUDA:0 (NVIDIA GeForce RTX 4090, 24209MiB)
YOLOv10nRTDETRHead_EMA_KAN summary: 340 layers, 9030232 parameters, 0 gradients, 16.2 GFLOPs
Class Images Instances Box(P R mAP50 mAP50-95): 100%|██████████| 79/79 [00:17<00:00, 4.42it/s]
all 5000 6390 0.973 0.974 0.982 0.754
powerbank 5000 75 0.991 0.987 0.985 0.794
mobilephone 5000 522 1 1 0.995 0.896
battery 5000 914 0.978 0.978 0.993 0.742
scissors 5000 130 1 0.995 0.995 0.731
fruitknife 5000 50 0.96 0.98 0.994 0.716
cleaver 5000 90 0.988 1 0.995 0.769
suspiciousliquid1 5000 4035 0.984 0.979 0.994 0.81
suspiciousliquid2 5000 498 0.975 0.992 0.994 0.773
lighter 5000 22 0.97 0.773 0.857 0.433
handcuffs 5000 22 0.982 1 0.995 0.817
expandablebatons 5000 17 0.944 1 0.995 0.805
pressure 5000 15 0.906 1 0.991 0.757
Speed: 0.2ms preprocess, 1.8ms inference, 0.0ms loss, 0.1ms postprocess per image
Results saved to /home/wqt/Projects/yolov10NEU/runs/SIXRay/train_yolo10nRTHead_EMA_KAN_BBoard_e300_b32_i640_aug2
总结
通过这次安装到最后的功能实现,体现了yolo10的特点:便捷安装,运行好。



















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











