




 本文介绍了Apache Flink的基础知识,包括checkpoint、state、时间处理和窗口机制。Flink提供SQL、DataStream和DataSet API,以及CEP、FlinkML等扩展库。在数据处理流程中,通过source、Transformation和Sink实现数据流动。分布式执行涉及JobClient、JobManager和TaskManager的角色。Flink适用于分布式流处理,支持无序数据和容错,具备良好的大规模运行性能和内存管理。
本文介绍了Apache Flink的基础知识,包括checkpoint、state、时间处理和窗口机制。Flink提供SQL、DataStream和DataSet API,以及CEP、FlinkML等扩展库。在数据处理流程中,通过source、Transformation和Sink实现数据流动。分布式执行涉及JobClient、JobManager和TaskManager的角色。Flink适用于分布式流处理,支持无序数据和容错,具备良好的大规模运行性能和内存管理。
本系列为学习笔记,记录点比较分散,用于记录重要知识点或复习,由于初学,难免存在问题,欢迎讨论指出。后续会在学习过程中不断围绕 WWW(what,how,why)补充改正。
WHAT
- Flink的基石
checkpoint:基于Chandy-Lamport,实现分布式一致性快照
state: 丰富stateAPI
Time:实现Watermark机制,乱序、迟到容忍
Window:开箱即用滚动、滑动、会话窗口,灵活自定义窗口 - APIS
SQL、DataStream(有界或无界)、DataSet(有界) - 扩展库
CEP、FlinkML、Gelly、Table
HOW
- source: 基于本地集合的source、基于文件的source、基于网络socket的source、自定义的source(kafka、kinesis streams、rabbitMQ、NiFi etc)
- Transformation:数据转换操作。Map、FlatMap、KeyBy、Filter、Reduce、Fold、Aggregations、Window、WindowAll、Union、Window join、Split、Select、Project等
- Sink:接收器,Sink类别有 - 写入文件、打印、写入socket、自定义sink(kafka、rabbitMQ、MySQL、ES、Cassandra、Hadoop FileSystem etc)。

写到这里感觉Flink在数据处理流程上和物联网里的传感器网络有那么一点点的类似(可能是Sink这个词),多Sensor节点负责收集、处理数据,再将数据汇总到Sink节点上供上游使用。
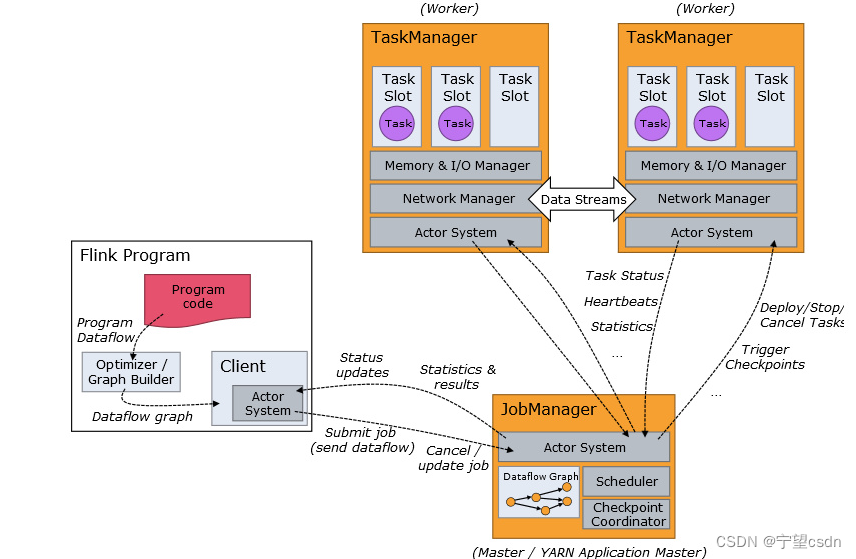
分布式执行
- Job Client: 任务起点,接受用户代码,创建数据流,将数据流交给Job Manager进一步执行,并负责接收返回结果
- Jon Manager:协调管理程序,集群中至少要一个master,负责调度task,协调checkpoints和容灾,高可用可多个master(保证一个leader)
- Task Manager:接收Job Manager接受Task,任务的并行性由可用槽决定,槽中可运行多个线程,同一插槽共享相同JVM(共享TCP和心跳消息),槽间共享CPU,不共享内存,共享Task,不共享Job
WHY
如果你的需求能被满足时:
- 开源分布式流处理
- 支持无序或延迟加载的数据
- 状态化、容错,同时在维护一次完整的应用状态时,能无缝修复错误
- 大规模运行,支持很好的吞吐量和低延迟
- 内存管理,Flink在JVM中提供了自己的内存管理,使用散列、索引、缓存和排序有效管理内存
- 拥有机器学习、图形处理、关系数据处理库
引用
- github - (zhisheng): flink-learning.


















 2432
2432

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









