




 博主通过实测对比了NVIDIA A100 GPU与V100、2080 Ti在深度学习任务上的表现,结果显示A100在多数模型训练中性能超出V100约1.5倍,部分场景可达1.7倍,全面超越2080 Ti。测试采用TensorFlow官方Benchmarks,涵盖了ResNet50、AlexNet、Inception v3、VGG16、GoogLeNet和ResNet152等多个模型。
博主通过实测对比了NVIDIA A100 GPU与V100、2080 Ti在深度学习任务上的表现,结果显示A100在多数模型训练中性能超出V100约1.5倍,部分场景可达1.7倍,全面超越2080 Ti。测试采用TensorFlow官方Benchmarks,涵盖了ResNet50、AlexNet、Inception v3、VGG16、GoogLeNet和ResNet152等多个模型。
眼看游戏卡RTX3080 发售在即,我终于等到了滴滴云(感谢)A100的测试机会。因为新卡比较紧张,一直在排队中,直到昨天才拿了半张A100...今天终于上手了单张40G的A100,小激动,小激动,小激动!!!基于安培架构的最新一代卡皇(NVIDIA GPU A100 Ampere)可以搞起来了。
Part 1:系统环境
A100正处于内存阶段,官网上还看不到。内测通过ssh连接,ssh连上去之后大概看了下系统环境。
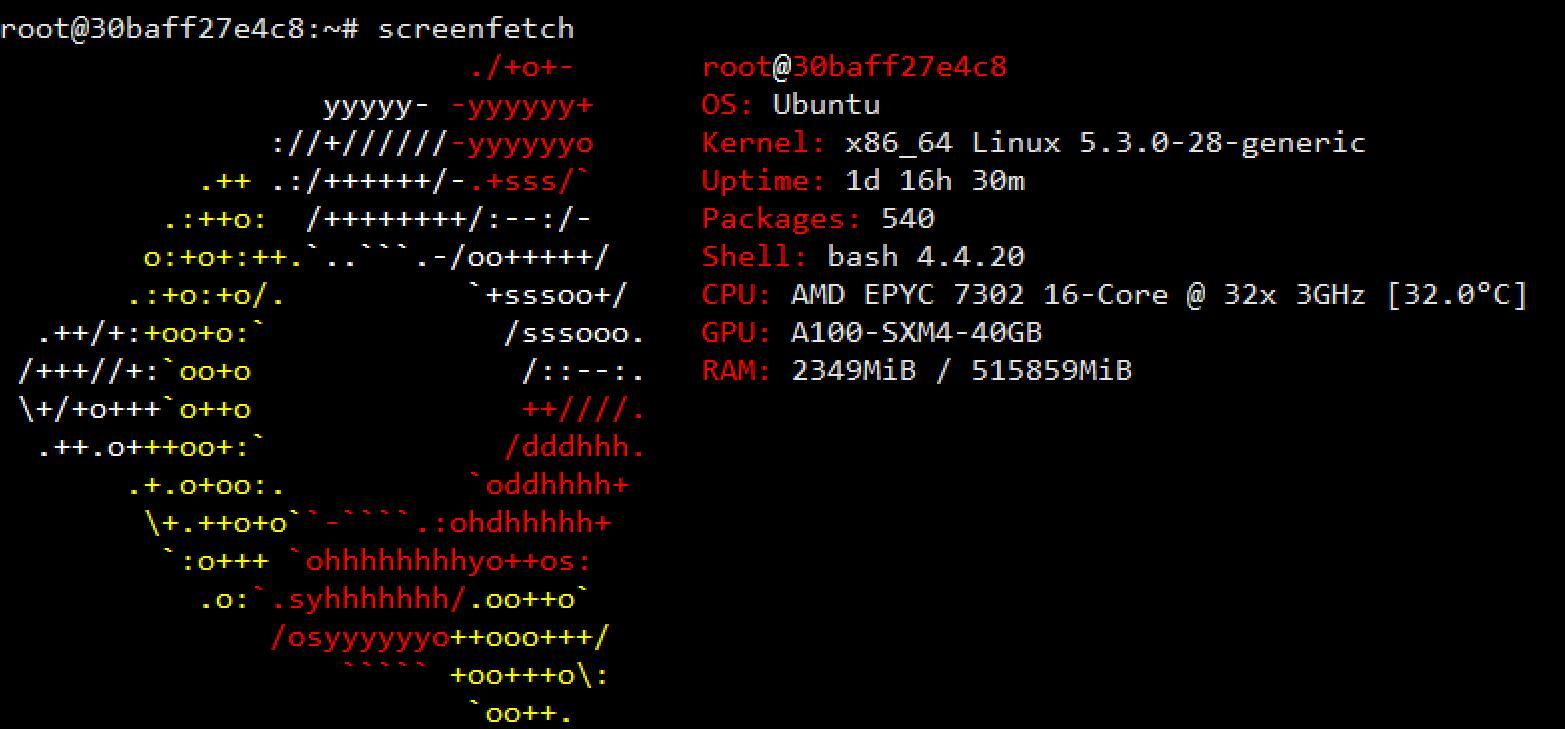
操作系统,CPU,RAM数据如上。重点关注GPU:A100-SXM4-40GB (上次摸DGX A100的时候,没有把测试跑起来,好悔)
CUDA11,CudNN,TensorFlow1.5.2 等配套环境滴滴云都已经部署好了,可以省去好多时间!
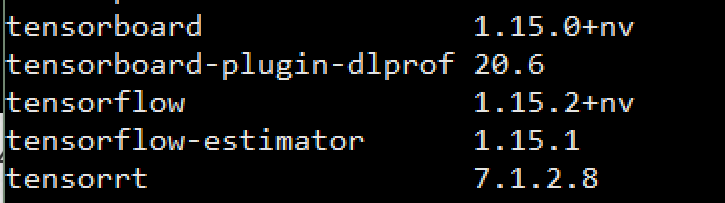
这里需要注意,新版显卡必须要用CUDA11,而且得用NV自己编译的TensorFlow1.5.2。
然后,网上捞一段Python代码:
from tensorflow.python.client
import device_lib print(device_lib.list_local_devices())输出:
Created TensorFlow device (/device:GPU:0 with 36672 MB memory) -> physical GPU (device: 0, name: A100-SXM4-40GB, pci bus id: 0000:cb:00.0, compute capability: 8.0)
[name: "/device:CPU:0"
device_type: "CPU"
memory_limit: 268435456
locality {
}
incarnation: 3653225364972814250
, name: "/device:XLA_CPU:0"
device_type: "XLA_CPU"
memory_limit: 17179869184
locality {
}
incarnation: 7582640257522961335
physical_device_desc: "device: XLA_CPU device"
, name: "/device:XLA_GPU:0"
device_type: "XLA_GPU"
memory_limit: 17179869184
locality {
}
in 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 4万+
4万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









