python numpy newaxis 记录(不懂)
最新推荐文章于 2025-02-06 14:18:39 发布





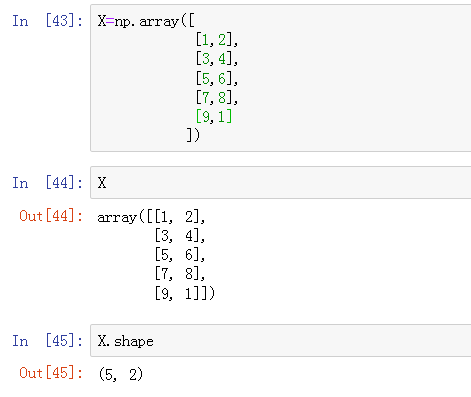
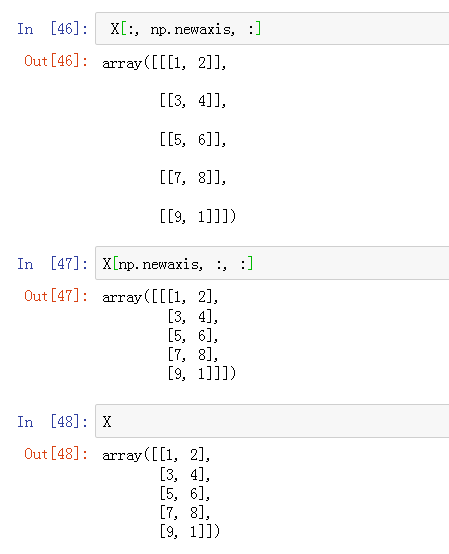
 本文详细介绍了使用NumPy库进行数组创建及操作的方法,包括如何使用np.array构建二维数组,展示数组形状(shape),以及如何通过增加维度进行数组重塑。这些技巧对于数据科学和机器学习项目中的数据预处理至关重要。
本文详细介绍了使用NumPy库进行数组创建及操作的方法,包括如何使用np.array构建二维数组,展示数组形状(shape),以及如何通过增加维度进行数组重塑。这些技巧对于数据科学和机器学习项目中的数据预处理至关重要。
本文详细介绍了使用NumPy库进行数组创建及操作的方法,包括如何使用np.array构建二维数组,展示数组形状(shape),以及如何通过增加维度进行数组重塑。这些技巧对于数据科学和机器学习项目中的数据预处理至关重要。
本文详细介绍了使用NumPy库进行数组创建及操作的方法,包括如何使用np.array构建二维数组,展示数组形状(shape),以及如何通过增加维度进行数组重塑。这些技巧对于数据科学和机器学习项目中的数据预处理至关重要。
 1489
329
324
295
1489
329
324
295

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言