




Redis Cluster 深度解析
一、Redis Cluster 概述
- 哨兵解决了高可用的问题,而集群就是终极方案,一举解决高可用和分布式问题。
- 数据分区: 数据分区 (或称数据分片) 是集群最核心的功能。集群将数据分散到多个节点,一方面 突破了 Redis 单机内存大小的限制,存储容量大大增加;另一方面 每个主节点都可以对外提供读服务和写服务,大大提高了集群的响应能力。
- 高可用: 集群支持主从复制和主节点的 自动故障转移 (与哨兵类似),当任一节点发生故障时,集群仍然可以对外提供服务。
核心特性
- 自动分片:数据自动分布在多个节点上
- 高可用性:内置故障检测和自动故障转移
- 线性扩展:支持动态增加或减少节点
- 客户端透明:客户端无需关心数据分布细节
二、数据分区机制
2.1 数据分区基础概念
数据分区是在集群创建的时候完成的。
数据分区(Data Partitioning)是分布式系统的核心设计之一,其本质是将数据集划分为多个子集分配到不同节点上。Redis 作为分布式缓存/数据库,主要通过三种分区策略实现数据分布。
分区核心目标
- 负载均衡:数据均匀分布避免热点
- 扩展性:支持动态增删节点
- 高效路由:快速定位数据所在节点
- 最小化迁移:节点变化时减少数据移动
2.2 节点取余分区原理
1. 基本实现
节点取余(Modular Hashing)是最简单的分区策略:
node_index = hash(key) % node_count
工作流程:
- 计算键的哈希值(如CRC32/MD5)
- 对当前节点数取余
- 根据余数选择对应节点
2. 特点分析
优势:
- 实现简单直接
- 数据分布均匀(依赖哈希函数质量)
致命缺陷:
- 扩容灾难:当节点数从N变为N+1时,约有N/(N+1)的数据需要迁移
- 不稳定性:节点宕机导致大量数据重分布
3. 适用场景
- 节点数量固定不变的场景
- 临时性数据分布需求
2.3 一致性哈希分区原理
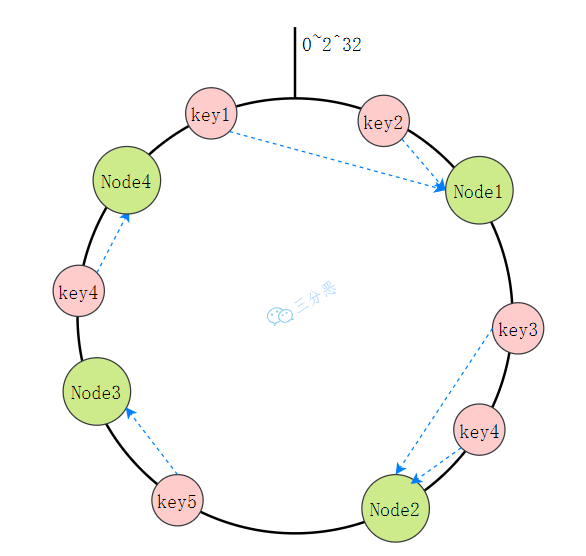
1. 环形空间设计
一致性哈希(Consistent Hashing)将哈希空间组织为环形(通常0~2³²-1):
class ConsistentHashing:
def __init__(self, nodes):
self.ring = SortedDict()
for node in nodes:
h = hash(node)
self.ring[h] = node
2. 数据定位机制
- 计算数据键的哈希值
- 在环上顺时针查找第一个节点
- 该节点即为数据归属节点
3. 虚拟节点优化
通过引入虚拟节点解决数据倾斜问题:
# 每个物理节点对应多个虚拟节点
VIRTUAL_NODES = 1000
for node in nodes:
for i in range(VIRTUAL_NODES):
h = hash(f"{node}-{i}")
self.ring[h] = node
4. 特点分析
优势:
- 扩容时仅影响相邻节点
- 通过虚拟节点改善数据均衡
局限性:
- 实现复杂度较高
- 节点故障时压力集中在后继节点
- 数据迁移量仍可达K/N(K为数据量,N为节点数)
2.4 虚拟槽分区原理
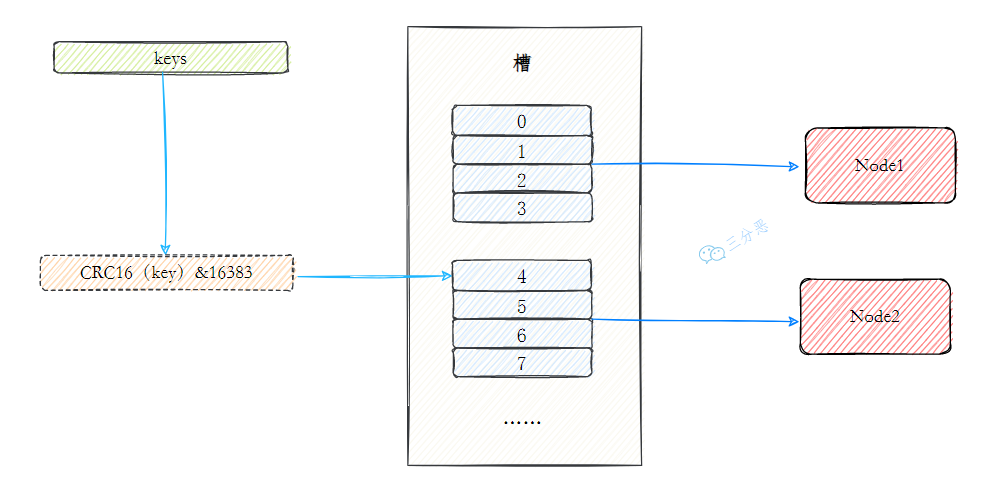
1. 分层设计思想
虚拟槽(Virtual Slot)是Redis Cluster的独创设计:
[键空间] → [固定数量槽位] → [动态节点映射]
核心组件:
- 哈希槽:固定16384个逻辑容器
- 槽位映射表:记录槽与节点的动态关系
2. 工作流程
- 键到槽映射:
slot = crc16(key) % 16384 - 槽到节点查找:
node = slot_map[slot]
3. 关键创新点
-
解耦数据与节点:
- 数据只关心槽位
- 槽位可灵活迁移
-
批量操作优化:
# 计算多个键的槽位 CLUSTER KEYSLOT key1 key2 key3 -
智能路由:
- 节点维护槽位映射表
- 可返回MOVED/ASK重定向
2.5 三种分区策略对比
| 特性 | 节点取余 | 一致性哈希 | 虚拟槽分区 |
|---|---|---|---|
| 数据分布均匀性 | 一般 | 依赖虚拟节点数 | 极佳 |
| 扩容数据迁移量 | 约N/(N+1) | 约1/N | 仅需迁移部分槽 |
| 故障影响范围 | 全局重分布 | 相邻节点受影响 | 仅影响故障节点槽 |
| 实现复杂度 | 简单 | 中等 | 复杂 |
| 动态调整能力 | 极差 | 较好 | 优秀 |
| Redis应用 | 无 | 早期客户端分片 | Redis Cluster |
2.6 虚拟槽分区的架构优势
1. 物理/逻辑分离设计
键空间 → 逻辑槽层 → 物理节点层
这种分层设计带来:
- 灵活迁移:槽位移动无需键重新哈希
- 细粒度控制:可以精确控制每个槽的位置
- 平滑扩容:支持槽的批量迁移
2. 集群总线协议
Redis Cluster使用TCP总线(端口号=客户端端口+10000)维护:
- 槽位映射表的传播
- 故障检测信息
- 配置更新通知
3. 智能客户端协作
- 客户端缓存槽位配置
- 处理MOVED重定向:
MOVED 3999 192.168.1.35:6381 - 支持ASK临时重定向:
ASK 3999 192.168.1.35:6382
三、集群架构原理
数据分区是在集群创建的时候完成的。
1. 集群组成
一个完整的 Redis Cluster 至少需要6个节点(3主3从),这是为了保证:
- 当任一主节点故障时,其从节点可以接管
- 选举时能获得多数票(N/2+1)
2. 节点角色
| 节点类型 | 职责 | 关键特性 |
|---|---|---|
| 主节点 | 处理读写请求,管理分配的槽 | 参与故障检测和投票 |
| 从节点 | 复制主节点数据,准备故障接管 | 不处理写请求,可处理读请求 |
3. 关键通信机制
-
Gossip协议:
- 节点间通过PING/PONG消息交换状态信息
- 传播速度 = O(logN),高效且低负载
-
故障检测流程:
节点A标记节点B为"主观下线" (PFail) → 通过Gossip传播 → 多数主节点确认 → 标记为"客观下线" (Fail) → 触发故障转移
四、故障转移机制
1. 自动故障转移流程
-
资格检查:
- 从节点与主节点断开时间不超过
cluster-node-timeout * 2 - 从节点数据足够新(复制偏移量接近)
- 从节点与主节点断开时间不超过
-
选举准备:
# 从节点增加选举纪元并广播FAILOVER_AUTH_REQUEST 127.0.0.1:6380> CLUSTER FAILOVER -
投票选举:
- 每个主节点在每个配置纪元只能投一票
- 从节点需要获得多数票(N/2+1)
-
角色切换:
- 获胜从节点执行
SLAVEOF NO ONE - 接管原主节点的槽位
- 其他从节点开始复制新主节点
- 获胜从节点执行
2. 与哨兵模式的区别
| 特性 | Redis Sentinel | Redis Cluster |
|---|---|---|
| 数据分布 | 单机/主从复制 | 分片存储 |
| 故障检测 | 集中式哨兵监控 | 分布式Gossip协议 |
| 适用规模 | 中小规模 | 大规模集群 |
| 客户端复杂度 | 需要处理主从切换 | 自动重定向 |
五、集群伸缩操作
1. 扩容流程
-
添加新节点:
redis-cli --cluster add-node new_host:new_port existing_host:existing_port -
迁移数据槽:
redis-cli --cluster reshard host:port --cluster-from <node-id> --cluster-to <node-id> --cluster-slots <num> --cluster-yes -
平衡槽分布:
redis-cli --cluster rebalance host:port --cluster-use-empty-masters
2. 缩容流程
-
迁移待移除节点的槽:
redis-cli --cluster reshard host:port -
安全移除节点:
redis-cli --cluster del-node host:port <node-id>
3. 数据迁移原理
- 在线迁移:不影响集群正常服务
- 原子性保证:使用
CLUSTER SETSLOT IMPORTING/MIGRATING - 重定向机制:
MOVED:永久重定向(槽已迁移)ASK:临时重定向(迁移中)
六、生产实践建议
1. 部署规范
-
硬件配置:
- 主从节点部署在不同物理机
- 建议16GB以上内存,SSD磁盘
-
网络配置:
cluster-announce-ip 192.168.1.100 # 公网IP cluster-announce-port 6379 cluster-announce-bus-port 16379 # 集群总线端口
2. 关键参数调优
cluster-node-timeout 15000 # 故障判定超时(毫秒)
cluster-replica-validity-factor 10 # 从节点有效性因子
cluster-migration-barrier 1 # 迁移屏障
3. 客户端最佳实践
-
智能客户端应实现:
- 缓存槽位映射表
- 自动处理MOVED/ASK重定向
- 支持读写分离
-
连接池配置:
// Jedis集群配置示例 JedisPoolConfig config = new JedisPoolConfig(); config.setMaxTotal(500); config.setMaxIdle(100); Set<HostAndPort> nodes = new HashSet<>(); nodes.add(new HostAndPort("127.0.0.1", 6379)); JedisCluster cluster = new JedisCluster(nodes, config);
七、常见问题解决方案
Q:为什么是16384个槽?
A:权衡考虑:
- 足够分散数据(16K足够)
- 心跳包携带完整槽信息(16K槽需要2KB空间)
- 集群规模限制(理论上最大1000节点)
Q:网络分区如何处理?
A:通过cluster-require-full-coverage配置:
yes(默认):必须所有槽可用才能服务no:允许部分分区继续服务
Q:如何保证数据一致性?
A:采用异步复制,可通过以下方式增强:
# 要求至少1个从节点确认
min-replicas-to-write 1
# 从节点延迟不超过10秒
min-replicas-max-lag 10
Redis Cluster 通过其精巧的设计,在性能、可用性和扩展性之间取得了出色的平衡,是构建大规模Redis服务的首选方案。理解其核心原理有助于在实际应用中做出合理的架构决策和问题排查。

















 7255
7255

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









