




调度器详解
一、调度过程
API Server 在接受客户端提交的 Pod 对象创建请求后,通过调度器(kube-scheduler)从集群中选择一个可用的最佳节点来创建并运行 Pod。
调度器通过以下步骤完成调度:
- Watch API Server:调度器 watch API Server,将
spec.nodeName为空的 Pod 放入调度器内部的调度队列中。 - 节点预选(Predicates):调度器基于一系列的预选规则对每个节点进行检查,过滤不符合条件的节点。例如:
- 节点标签必须匹配 Pod 资源的标签选择器(
MatchNodeSelector)。 - Pod 容器的资源请求量不能大于节点上剩余的可分配资源(
PodFitsResources)。 - 如果预选未能选定合适的节点,Pod 会一直处于
Pending状态,直到有可用节点完成调度。
- 节点标签必须匹配 Pod 资源的标签选择器(
- 节点优选(Priorities):调度器对预选出的节点进行打分并排序,以便选出最合适运行 Pod 的节点。调度器会向每个通过预选的节点传递一系列的优选函数来计算其优先级分值,并加权得到节点的最终优先级分值。
- 节点选定(Binding):调度器从优先级排序结果中挑选出优先级最高的节点运行 Pod。当有多个节点优先级相同时,随机选择一个节点。调度器与 API Server 通信(发送绑定调用),设置 Pod 的
spec.nodeName属性以表示将该 Pod 调度到的节点。
调度上下文:调度过程为 Pod 选择一个合适的节点,绑定过程则将调度过程的决策应用到集群中(即在被选定的节点上运行 Pod)。调度过程和绑定过程合在一起称为调度上下文(scheduling context)。
- 调度过程:同步运行(同一时间点只为一个 Pod 进行调度)。
- 绑定过程:异步运行(同一时间点可并发为多个 Pod 执行绑定)。
调度中断:调度过程和绑定过程在以下情况下会中途退出:
- 调度程序认为当前没有该 Pod 的可选节点。
- 内部错误。
此时,该 Pod 将被放回到待调度队列,等待下次重试。
二、优先级调度
优先级调度与节点优先级不同,它指的是 Pod 的优先级。高优先级的 Pod 会优先被调度,或在资源不足时牺牲低优先级的 Pod,以便重要的 Pod 能够得到资源部署。
1. 定义 Pod 优先级
要定义 Pod 优先级,需要先定义 PriorityClass 对象:
apiVersion: v1
kind: PriorityClass
metadata:
name: priority-high
value: 5000
globalDefault: false
description: "This priority class should be used for XYZ service pods only."
- value:32 位整数的优先级,值越大,优先级越高。
- globalDefault:用于未配置
PriorityClassName的 Pod,整个集群中应该只有一个PriorityClass将其设置为true。
2. 在 Pod 中指定优先级
通过在 Pod 的 spec.priorityClassName 中指定已定义的 PriorityClass 名称即可:
apiVersion: v1
kind: Pod
metadata:
name: nginx
labels:
app: nginx
spec:
containers:
- name: nginx
image: nginx
imagePullPolicy: IfNotPresent
priorityClassName: high-priority
3. 抢占(Preemption)
当节点没有足够的资源供调度器调度 Pod,导致 Pod 处于 Pending 状态时,抢占逻辑会被触发。抢占会尝试从一个节点删除低优先级的 Pod,从而释放资源使高优先级的 Pod 得到节点资源进行部署。
三、调度器调优
percentageOfNodesToScore 参数
percentageOfNodesToScore 是一个用于优化大规模集群调度性能的参数。它是一个百分比值,范围在 1 到 100 之间,表示调度器在筛选可调度节点时,最多会检查集群中多少比例的节点。
- 默认值:如果用户没有显式配置该参数,Kubernetes 会根据集群规模自动计算一个默认值:
- 100 个节点的集群,默认值为 50%。
- 5000 个节点的集群,默认值为 10%。
- 最低值为 5%,即调度器至少会检查集群中 5% 的节点。
- 特殊情况:
- 如果集群中可调度节点少于 50 个,调度器会检查所有节点。
- 如果将该参数设置为 100,调度器会检查所有节点(即关闭该优化功能)。
参数设置的注意事项
- 小规模集群:如果集群规模较小(例如几百个节点),不建议将该参数设置得比默认值更低,因为对性能提升不明显。
- 大规模集群:在超过 1000 个节点的大规模集群中,将该参数设置为较低的值(如 10%)可以显著提高调度器性能。但需要注意,设置过低的值可能会导致一些本应在打分阶段得分较高的节点被忽略,从而影响调度质量。
- 极端情况:如果调度器的吞吐量非常高,且对节点的打分不重要(即只需任意选择一个可调度节点运行 Pod),可以将该参数设置为较低的值(如 5% 或更低)。但通常情况下,不建议将该参数设置得低于 10。
四、默认调度器
Kubernetes 的默认调度器(kube-scheduler)通常是以 Pod 的形式运行,但它并不是普通的用户 Pod,而是 Kubernetes 控制平面(Control Plane)的一部分。
1. kube-scheduler 的运行方式
- 作为静态 Pod 运行:在大多数 Kubernetes 集群中,kube-scheduler 是以静态 Pod(Static Pod)的形式运行的。静态 Pod 的配置文件通常位于节点的
/etc/kubernetes/manifests目录下,例如kube-scheduler.yaml。 - 作为系统组件运行:kube-scheduler 是 Kubernetes 控制平面的核心组件之一,负责将 Pod 调度到合适的节点上。它通常与
kube-apiserver、kube-controller-manager等组件一起运行在 Master 节点上。 - 高可用性(HA)部署:在生产环境中,kube-scheduler 通常会以高可用模式部署,即运行多个 kube-scheduler 实例。多个实例通过 Leader Election 机制选举出一个主实例,主实例负责执行调度任务,其他实例处于备用状态。
2. kube-scheduler 的配置文件
kube-scheduler 的配置文件一般在 /etc/kubernetes 下。以下是一个示例配置文件:
apiVersion: kubescheduler.config.k8s.io/v1beta1
kind: KubeSchedulerConfiguration
clientConnection:
kubeconfig: /etc/kubernetes/kubeconfig
qps: 100
burst: 150
profiles:
- schedulerName: default-scheduler
plugins:
postFilter:
disabled:
- name: DefaultPreemption
preFilter:
enabled:
- name: CheckCSIStorageCapacity
filter:
enabled:
- name: CheckPodCountLimit
- name: CheckPodLimitResources
- name: CheckCSIStorageCapacity
- name: LvmVolumeCapacity
pluginConfig:
- name: CheckPodCountLimit
args:
podCountLimit: 2
- name: CheckPodLimitResources
args:
limitRatio:
cpu: 0.7
memory: 0.7
- apiVersion 和 kind:
apiVersion: kubescheduler.config.k8s.io/v1beta1:指定了 Kubernetes Scheduler 配置的 API 版本。kind: KubeSchedulerConfiguration:表示这是一个 Kubernetes Scheduler 的配置文件。
- clientConnection:
kubeconfig: /etc/kubernetes/kubeconfig:指定了调度器连接 Kubernetes API Server 的 kubeconfig 文件路径。qps: 100:每秒查询数(Queries Per Second),限制调度器对 API Server 的请求频率。burst: 150:突发请求数,允许调度器在短时间内超过 QPS 限制的请求数。
- profiles:
- 定义了调度器的配置模板,这里只有一个名为
default-scheduler的调度器。 - plugins:启用了或禁用了某些调度插件:
postFilter:禁用DefaultPreemption插件(默认抢占机制)。preFilter:启用CheckCSIStorageCapacity插件(检查 CSI 存储容量)。filter:启用了多个插件,包括CheckPodCountLimit(检查 Pod 数量限制)、CheckPodLimitResources(检查 Pod 资源限制)、CheckCSIStorageCapacity(检查 CSI 存储容量)和LvmVolumeCapacity(检查 LVM 卷容量)。
- pluginConfig:为某些插件提供了配置参数:
CheckPodCountLimit:设置 Pod 数量限制为 2。CheckPodLimitResources:设置 CPU 和内存的资源使用比例限制为 70%。
- 定义了调度器的配置模板,这里只有一个名为
五、自定义调度器
1. 调度器扩展程序
调度器扩展程序是一个可配置的 Webhook,包含过滤器和优先级两个端点,分别对应调度周期中的两个主要阶段(过滤和打分)。
- 默认调度器:默认调度器是主导,外部调度器是辅助角色。外部调度器仅在需要时被调用,例如 Pod 的资源需求涉及
managedResources。 - 外部调度器:外部调度器根据自身的逻辑,对节点进行过滤、优先级排序或绑定操作。外部调度器的结果会返回给默认调度器。
- 综合结果:默认调度器会结合自身的结果和外部调度器的结果,决定最终的调度决策。如果有多个外部调度器,默认调度器会根据它们的权重(weight)对结果进行加权计算。
2. 调度框架
Kubernetes v1.15 版本中引入了可插拔架构的调度框架,使得定制调度器变得更加容易。调度框架向现有的调度器中添加了一组插件化的 API,使得大部分的调度功能以插件的形式存在。
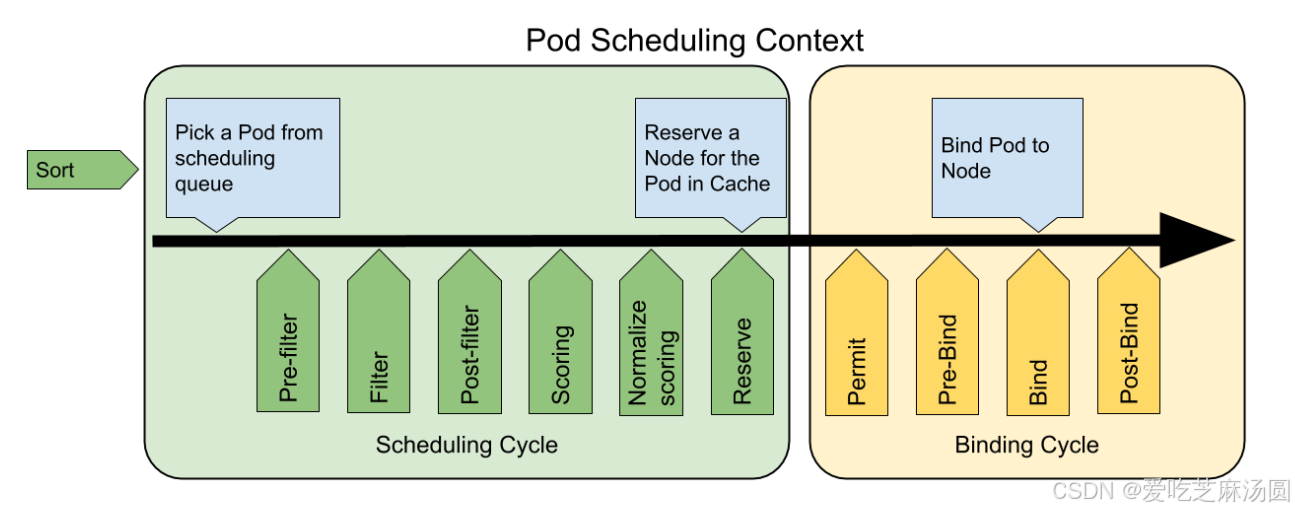
图片来源:Kubernetes 调度器概述
- 扩展点:调度框架定义了一组扩展点,用户可以实现扩展点定义的接口来定义自己的调度逻辑,并将扩展注册到扩展点上。调度框架在执行调度工作流时,遇到对应的扩展点时,将调用用户注册的扩展。
- 扩展点类型:
- QueueSort:对 Pod 的待调度队列进行排序。
- Pre-filter:对 Pod 的信息进行预处理或检查集群或 Pod 必须满足的前提条件。
- Filter:排除不能运行该 Pod 的节点。
- Post-filter:通知类型的扩展点,用于更新内部状态或产生日志、metrics 信息。
- Scoring:为所有可选节点进行打分。
- Normalize scoring:在调度器对节点进行最终排序之前修改每个节点的评分结果。
- Reserve:通知性质的扩展点,用于获得节点上为 Pod 预留的资源。
- Permit:阻止或延迟 Pod 与节点的绑定。
- Pre-bind:在 Pod 绑定之前执行某些逻辑。
- Bind:将 Pod 绑定到节点上。
- Post-bind:在 Pod 成功绑定到节点上之后执行资源清理的动作。
- Unreserve:释放已经为 Pod 预留的节点上的计算资源。
3. 调度器扩展程序的局限性
- 通信成本:数据在默认调度程序和调度器扩展程序之间以 HTTP(S) 传输,存在序列化和反序列化的成本。
- 有限的扩展点:扩展程序只能在某些阶段的末尾参与,例如“Filter”和“Prioritize”。
- 减法优于加法:调度器扩展程序最好执行“减法”(进一步过滤),而不是“加法”(添加节点)。
- 缓存共享:默认调度程序无法共享其缓存,必须构建和维护自己的缓存。


















 3万+
3万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









