




Pod的易错点
- Pod 是在 Kubernetes 集群中运行部署应用或服务的最小单元,它是可以支持多容器的。 Pod 的设计理念是支持多个容器在一个 Pod 中共享网络地址和文件系统,可以通过进程间通信和文件共享这种简单高效的方式组合完成服务。Pod 对多容器的支持是 K8 最基础的设计理念。
- Pod 不是进程,而是容器运行的环境。 Pod 天生地为其成员容器提供了两种共享资源:网络 和 存储。在被删除之前,Pod 会一直存在。
- Pod中可以有多个容器,在主容器启动前,可以使用init容器进行初始化工作。
- Pod 在其生命周期中只会被调度一次。
将 Pod 分配到特定节点的过程称为绑定,而选择使用哪个节点的过程称为调度。 一旦 Pod 被调度并绑定到某个节点,Kubernetes 会尝试在该节点上运行 Pod。 Pod 会在该节点上运行,直到 Pod 停止或者被终止; - 可以使用Pod 调度就绪态来延迟 Pod 的调度,直到所有的调度门控都被移除。 例如,你可能想要定义一组 Pod,但只有在所有 Pod 都被创建完成后才会触发调度。
Pod的状态
| 项目 | Value |
|---|---|
| Pod的状态 | |
| Pending | Pod 已被 Kubernetes 系统接受,但有一个或者多个容器尚未创建亦未运行。此阶段包括等待 Pod 被调度的时间和通过网络下载镜像的时间。 |
| Running | Pod 已经绑定到了某个节点,Pod 中所有的容器都已被创建。至少有一个容器仍在运行,或者正处于启动或重启状态。 |
Pod生命周期
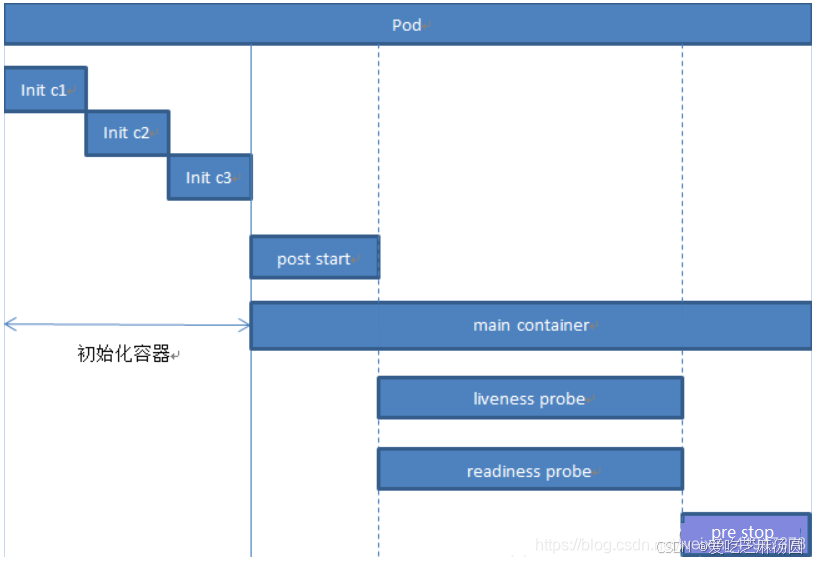
- 主容器就是我们的镜像构建的容器。
- 初始化容器阶段初始化pod中每一个init容器,他们是串行执行的,执行完成后就退出了。
- 三种探针
- liveness probe(存活探测)
- readiness probe(就绪探测)
- startup probe(启动探测)
- hook钩子函数
- post start:容器创建之后立即执行,如果失败了就会按照重启策略重启容器
- pre stop:容器终止前立即执行,执行完成之后容器将成功终止
kubectl explain pod.spec.containers.lifecycle.preStop
kubectl explain pod.spec.containers.lifecycle.postStart
Pod创建过程(重点)
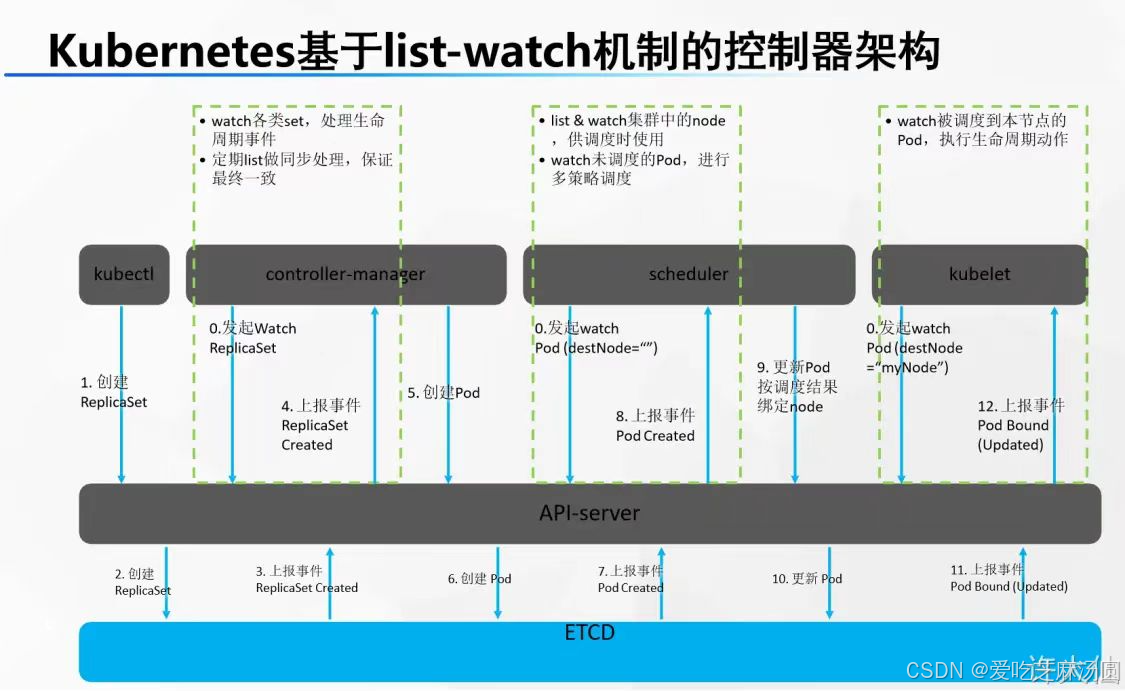
开机默认所有节点的 kubelet 、master 节点的scheduler(调度器)、controller-manager(控制管理器)一直监听 master 的 api-server 发来的事件变化。
- 1 :程序员使用命令行工具: kubectl ; kubectl create deploy tomcat --image=tomcat8(告诉 master 让集群使用 tomcat8 镜像,部署一个 tomcat 应用)。
- 2 :kubectl 命令行内容发给 api-server,api-server 保存此次创建信息到 etcd 。
- 3 :etcd 给 api-server 上报事件,说刚才有人给我里面保存一个信息。(部署Tomcat[deploy])
- 4:controller-manager 监听到 api-server 的事件,是 (部署Tomcat[deploy])。
- 5:controller-manager 处理这个 (部署Tomcat[deploy])的事件。controller-manager 会生成 Pod 的部署信息【pod信息】。
- 6:controller-manager 把 Pod 的信息交给 api-server ,再保存到 etcd 。
- 7:etcd 上报事件【pod信息】给 api-server 。
- 8:scheduler 专门监听 【pod信息】 ,拿到 【pod信息】的内容,计算,看哪个节点合适部署这个 Pod【pod 调度过后的信息(node: node-02)】。
- 9:scheduler 把 【pod 调度过后的信息(node: node-02)】交给 api-server 保存给 etcd 。
- 10:etcd 上报事件【pod调度过后的信息(node: node-02)】,给 api-server 。
- 11:其他节点的 kubelet 专门监听 【pod 调度过后的信息(node: node-02)】 事件,集群所有节点 kubelet 从 api-server 就拿到了 【pod调度过后的信息(node: node-02)】 事件。
- 12:每个节点的 kubelet 判断是否属于自己的事情;node-02 的 kubelet 发现是他的事情。
- 13:node-02 的 kubelet 启动这个 pod。汇报给 master 当前启动好的所有信息。
我们可以总结以下几点:
- kubelet、scheduler、controller都是采取watch机制的。
- 做一个动作都会经过类似的几步:
- api-server收到命令(无论是用户的还是组件的)
- 与底层的etcd交互,存信息
- etcd处理完后上报api-serever
- 上层的组件(包括用户)watch,了解变化后做出相应的动作再反馈给api-server
Pod的终止
- 当你请求删除某个 Pod 时,集群会记录并跟踪 Pod 的体面终止周期, 而不是直接强制地杀死 Pod。在存在强制关闭设施的前提下,kubelet会尝试体面地终止 Pod。
kubelet 先发送一个带有体面超时限期的 TERM(又名 SIGTERM) 信号到每个容器中的主进程,将请求发送到容器运行时来尝试停止 Pod 中的容器。停止容器的这些请求由容器运行时以异步方式处理。 这些请求的处理顺序无法被保证。许多容器运行时遵循容器镜像内定义的STOPSIGNAL值, 如果不同,则发送容器镜像中配置的 STOPSIGNAL,而不是 TERM 信号。一旦超出了体面终止限期,容器运行时会向所有剩余进程发送 KILL 信号,之后 Pod 就会被从API服务器上移除。如果kubelet或者容器运行时的管理服务在等待进程终止期间被重启, 集群会从头开始重试,赋予 Pod 完整的体面终止限期。
参考文档
https://xwl.io/


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









