



 本文介绍如何在Jetson TX2上使用Python捕获相机视频并进行Caffe推理。先说明了前提条件,包括运行相机视频捕获脚本和构建Caffe。还给出参考资料,详细讲解运行示例代码的方法,最后用不同相机和Caffe模型进行测试,并提及灰度图像输入模型的代码修改。
本文介绍如何在Jetson TX2上使用Python捕获相机视频并进行Caffe推理。先说明了前提条件,包括运行相机视频捕获脚本和构建Caffe。还给出参考资料,详细讲解运行示例代码的方法,最后用不同相机和Caffe模型进行测试,并提及灰度图像输入模型的代码修改。
https://jkjung-avt.github.io/tx2-camera-caffe/
How to Capture Camera Video and Do Caffe Inferencing with Python on Jetson TX2
Oct 27, 2017
Quick link: tegra-cam-caffe.py
2018-06-14 update: I’ve extended the TX2 camera caffe inferencing code with a (better) multi-threaded design. Check out this newer post for details: Multi-threaded Camera Caffe Inferencing.
Last week I shared a python script which could be used to capture and display live video from camera (IP, USB or onboard) on Jetson TX2. Here I extend that script and show how you can run Caffe image classification (inferencing) on the captured camera images, all done in python code. This tegra-cam-caffe.py sample should be good for quickly verifying your newly trained Caffe image classification models, for prototyping, or for building Caffe demo programs with live camera input.
I mainly tested the script with python3 on Jetson TX2. But I think the code also works with python2, as well as on Jetson TX1.
Prerequisite:
- Refer to my previous post “How to Capture and Display Camera Video with Python on Jetson TX2” and make sure
tegra-cam.pyruns OK on your Jetson TX2. - Build Caffe on your Jetson TX2. You can use either BVLC Caffe, NVIDIA Caffe or other flavors of Caffe of your preference, while referring to my earlier post about how to build the code: How to Install Caffe and PyCaffe on Jetson TX2.
- My python code assumes the built Caffe code is located at
/home/nvidia/caffe. In order to run the script with the defaultbvlc_reference_caffenetmodel, you’ll have to download the pre-trained weights and labels by:
$ cd /home/nvidia/caffe
$ python3 ./scripts/download_model_binary.py ./models/bvlc_reference_caffenet
$ ./data/ilsvrc12/get_ilsvrc_aux.sh
Reference:
- How to classify images with Caffe’s python API: https://github.com/BVLC/caffe/blob/master/examples/00-classification.ipynb
- How to calculate mean pixel values for mean subtraction: https://devtalk.nvidia.com/default/topic/1023944/loading-custom-models-on-jetson-tx2/#5209641
How to run the Tegra camera Caffe sample code:
- Download the
tegra-cam-caffe.pysource code from my GitHubGist: https://gist.github.com/jkjung-avt/d408aaabebb5b0041c318f4518bd918f - To dump help messages.
$ python3 tegra-cam-caffe.py --help
- To do Caffe image classification with the default
bvlc_reference_caffenetmodel using the Jetson onboard camera (default behavior of the python program).
$ python3 tegra-cam-caffe.py
- To use USB webcam
/dev/video1instead, while setting video resolution to 1280x720.
$ python3 tegra-cam-caffe.py --usb --vid 1 --width 1280 --height 720
- Or, to use an IP CAM.
$ python3 tegra-cam-caffe.py --rtsp --uri rtsp://admin:XXXXXX@192.168.1.64:554
- To do image classification with a different Caffe model using the onboard camera.
$ python3 tegra-cam-caffe.py --prototxt XXX.prototxt \
--model YYY.caffemodel \
--labels ZZZ.txt \
--mean UUU.binaryproto
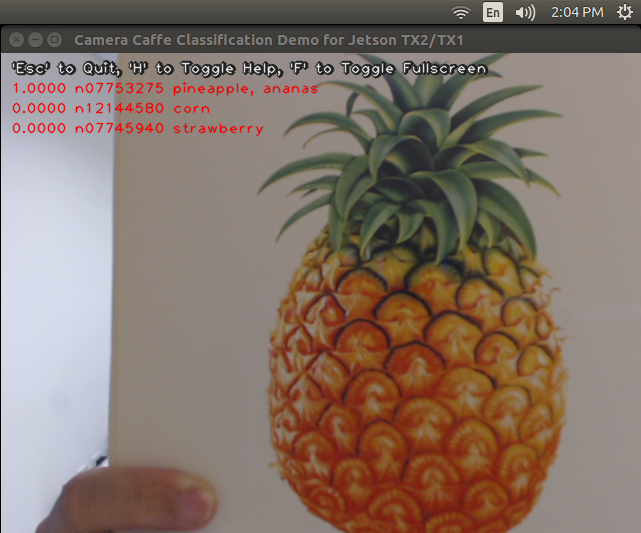
When I tested the code with a USB camera and a picture of pineapple, the default bvlc_reference_caffenet said it was 100% sure (probability ~ 1.0) the image was a pineapple!
Next, I tried to test with a Caffe model trained with NVIDIA DIGITS. More specifically, I trained an AlexNet with ‘Caltech 101’ dataset, as mentioned in this NVIDIA QuikLabs course: Image Classification with DIGITS. One very nice thing about this free QuickLabs course is that you get 2-hour access of a K520 GPU based cloud server with NVIDIA DIGITS, with no charge at all. After successfully training an AlexNet model with ‘Caltech 101’ dataset (I just trained the model for 30 epochs with plain SGD and the default learning rate, 0.01), I then downloaded the model snapshot of the last training epoch from DIGITS: 20171022-025612-7b04_epoch_30.0.tar.gz. Here’s the list of files in that snapshot tarball.
info.json
labels.txt
mean.binaryproto
original.prototxt
snapshot_iter_1620.caffemodel
solver.prototxt
train_val.prototxt
I then verified this trained Caffe model with the following command. During training, the logs indicated this trained model has an accuracy at only around 67.5% (for classifying 101 classes of objects). When testing, I did find this model working poorly on many test images. But anyway I managed to get this model to classify a ‘pegion’ picture correctly.
$ python3 ./tegra-cam-caffe.py --usb --vid 1 --crop \
--prototxt alexnet/deploy.prototxt \
--model alexnet/snapshot_iter_1620.caffemodel \
--labels alexnet/labels.txt \
--mean alexnet/mean.binaryproto \
--output softmax
By the way, in case you’d like to run the code with a Caffe model trained for grayscale image inputs (e.g. LeNet), you’ll have to modify the python code to convert the input camera images to grayscale before feeding them to the Caffe transformer for processing. This could be done by, say, gray = cv2.cvtColor(img_crop, cv2.COLOR_BGR2GRAY) and then net.blobs["data"].data[...] = transformer.preprocess("data", gray).
I have not done much testing of this code with various cameras or Caffe models. Feel free to let me know if you find any issue with the code, and I’ll look into it as soon as I can.

















 955
955

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









