




- 🍨 本文为🔗365天深度学习训练营 中的学习记录博客
- 🍖 原作者:K同学啊
目录
前言
在NLP任务中,单词的序列顺序是非常重要的,将单词的顺序重新排列,整个句子的意思可能会发生改变。在RNN循环神经网络中,有着处理序列顺序的内置机制。Transformer通过引入位置编码机制来保存文本中字符的位置信息。
什么是位置编码
1. 定义
位置编码记录了文本中字符的位置信息,它并没有使用单个数字(例如索引值)的形式来记录位置信息。原因主要有:
- 对于长序列,索引的大小可能会变得很大,不利于存储。
- 将索引值规范化到0-1之间,可能会为可变长度序列带来问题(它们的标准化方式不同)。
Transformer使用智能位置编码方案,第个位置/索引都映射到了一个向量,所以位置编码层的输出明天是一个矩阵,其中矩阵的每一行代表序列中的一个编码对象与其位置信息相加。
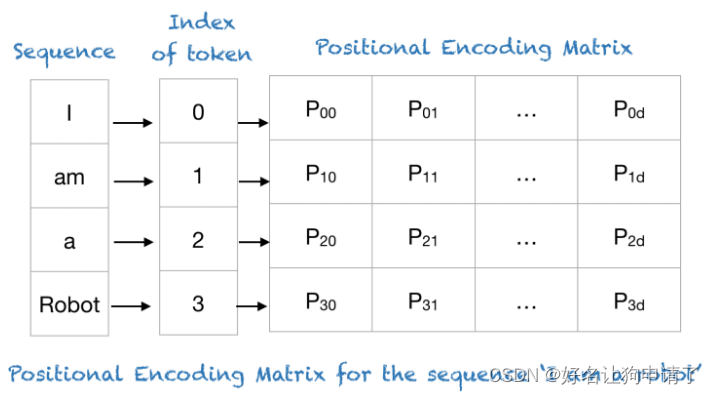
2. 三角函数
正弦函数的值域为[-1, 1],可以等效地使用正弦函数或余弦函数。

3. 位置编码公式
假设你有一个长度为L的输入序列,要计算第K个元素的位置编码,可以由不同频率的正弦和余弦函数给出:
P ( k , 2 i ) = s i n ( k n 2 i / d ) P(k, 2i) = sin(\frac k {n^{2i/d}}) P(k,2i)=sin(n2i/dk)
P ( k , 2 i + 1 ) = c o s ( k n 2 i / d ) P(k, 2i + 1) = cos(\frac k {n^{2i/d}}) P(k,2i+1)=
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 2386
2386

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









