




- 🍨 本文为🔗365天深度学习训练营 中的学习记录博客
- 🍖 原作者:K同学啊 | 接辅导、项目定制
环境
- 系统: Linux
- 语言: Python3.8.10
- 深度学习框架: Pytorch2.0.0+cu118
- 显卡:GTX2080TI
步骤
环境设置
首先是包引用,使用pytorch,处理CV任务,一般包引用都是统一的
import torch
import torch.nn as nn
import torch.optim as optim
import torch.nn.functional as F
import torch.utils.data import DataLoader, random_split
import torchvision import datasets, transforms
import matplotlib.pyplot as plt
import numpy as np
from torchinfo import summary
from PIL import Image
import random, pathlib, copy
from collections import OrderedDict
声明一个设备对象,模型、数据都要转移到相同的设备对象中,才能访问
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
数据准备
下载并解压猴痘识别数据集,然后通过pathlib打开查看一下图像的尺寸等信息
path = './monkeypox'
lib_path = pathlib.Path(path)
images = list(lib_path.glob('*/*'))
for _ in range(5):
print(np.array(Image.open(str(random.choice(images))).shape)
打印的结果展示所有的图像都是三通道,大小为224*224的,我一般还会再把图像随机取几个打印一下看看是什么样的。不过这个猴痘病毒的图像有点恶心,所以我就不贴了。
(224, 224, 3)
(224, 224, 3)
(224, 224, 3)
(224, 224, 3)
(224, 224, 3)
# 随机打印20张图像
plt.figure(figsize=(20, 4))
for i in range(20):
plt.subplot(2, 10, i+1)
plt.axis('off')
image = random.choice(images)
plt.title(image.parts[-2])
plt.imshow(Image.open(str(image)))
由此可以开始编写数据集的预处理transform
transform = transforms.Compose([
transforms.Resize([224, 224]),
transforms.ToTensor(),
transforms.Normalize(
mean=[0.485, 0.456, 0.406],
std=[0.229, 0.224, 0.225],
)])
定义好了图像转换到向量的transform后,就可以开始进行数据集的制作环节了
dataset = datasets.ImageFolder(path, transform=transform)
class_names = [x for x in dataset.class_to_idx]
print(class_names)
['Others', 'MonkeyPox']
然后是训练集和测试集的划分
train_size = int(len(dataset) * 0.9)
test_size = len(dataset) - train_size
train_dataset, test_dataset = random_split(dataset, [train_size, test_size])
然后是将数据集创建数据加载器
batch_size = 32
train_loader = DataLoader(train_dataset, batch_size=batch_size, shuffle=True)
test_loader = DataLoader(test_dataset, batch_size=batch_size)
模型设计
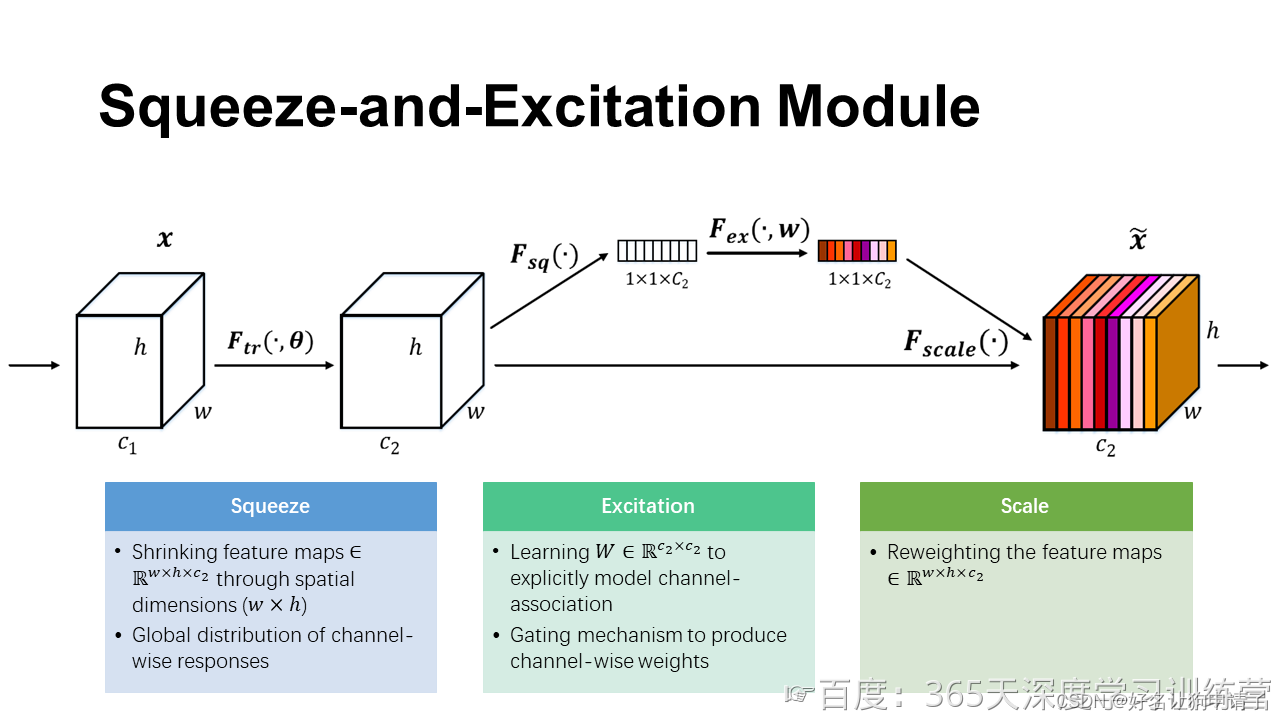
从图中可以发现,SE模块的输入和输入形状完全一致,目的是为了逐通道计算一个权重值,更好的抑制无关的参数,增强真正学习到的参数。
首先是创建SE层
class SELayer(nn.Module):
def __init__(self, input_size, hidden_size):
super().__init__()
self.avgpool = nn.AdaptiveAvgPool2d(1)
self.hidden = nn.Linear(input_size, hidden_size)
self.restore = nn.Lineare(hidden_size, input_size)
def forward(self, inputs):
x = self.avgpool(inputs)
x = x.view(x.size(0), -1)
x = self.hidden(x)
x = F.relu(x)
x = self.restore(x)
x = F.sigmoid(x)
x = x.view(x.size(0), -1, 1, 1)
scaled = x*inputs
return scaled
创建测试向量来测试SE模块
se = SELayer(1024, 256)
inputs = np.zeros((16, 1024, 6, 6))
se(inputs).shape
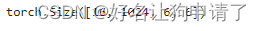
通过结果可以发现,输入和输出的形状是完全一致的。接下来开始编写DenseNet的DenseBlock模块
class ConvBlock(nn.Sequential):
def __init__(self, input_size, growth_rate, name):
super().__init__()
self.add_module(name + '_0_bn', nn.BatchNorm2d(input_size))
self.add_module(name + '_0_relu', nn.ReLU())
self.add_module(name + '_1_conv', nn.Conv2d(input_size, 4*growth_rate, kernel_size=1, bias=False))
self.add_module(name + '_1_bn', nn.BatchNorm2d(4*growth_rate))
self.add_module(name + '_1_relu', nn.ReLU())
self.add_module(name + '_2_conv', nn.Conv2d(4*growth_rate, growth_rate, kernel_size=3, padding='same', bias=False)
def forward(self, inputs):
x = super().forward(inputs)
return torch.cat([inputs, x], dim=1)
class DenseBlock(nn.Sequential):
def __init__(self, input_size, blocks, name):
super().__init__()
growth_rate =  最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 873
873

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









