






 本文介绍了SpringBoot 2.x中使用Lettuce替代1.x的Jedis作为Redis客户端的情况,并详细讲解了Redisson在分布式环境下的应用,特别是ScoredSortedSet的使用场景,如实时排行榜、时间线和任务调度等。同时,提到了RedissionAtomicLong在统计订单和在线设备数量上的应用。
本文介绍了SpringBoot 2.x中使用Lettuce替代1.x的Jedis作为Redis客户端的情况,并详细讲解了Redisson在分布式环境下的应用,特别是ScoredSortedSet的使用场景,如实时排行榜、时间线和任务调度等。同时,提到了RedissionAtomicLong在统计订单和在线设备数量上的应用。
lettuce
redistemplate是springboot2.X后面,由lettuce具体实现,1.x的是jedis,redisson是redis的分布式客户端
Lettuce 是一个 基于 Netty 的高性能、线程安全的 Java Redis 客户端,专为高并发和异步场景设计。以下是其核心要点
异步与非阻塞:基于 Netty 实现,支持异步和响应式编程(如 Reactive Streams)。
线程安全:单个连接实例可被多线程共享,无需连接池。
协议支持:完整支持 Redis 5/6/7 的协议(RESP2/RESP3)、集群、哨兵、管道、事务等。
长连接:支持连接自动重连和心跳保活,适合长时间运行的分布式服务。
redisson
<dependency>
<groupId>org.redisson</groupId>
<artifactId>redisson</artifactId>
<version>3.15.4</version>
</dependenc
命令
- 1
redisson
1. 使用官网git
什么场景需要用到RScoredSortedSet,举例说明
-
实时排行榜:在游戏、竞赛或社交应用中,需要实时地根据分数来排名用户或团队。ScoredSortedSet可以将用户的得分作为分数,并将用户对象添加到集合中。通过调用方法如
reverseRange,可以轻松地获取排行榜上的前几名。 -
时间线:类似于社交媒体平台的时间线,可以使用ScoredSortedSet按照发布时间对帖子进行排序。每个帖子可以关联一个时间戳作为分数,通过添加帖子对象到集合中并调用
range方法,可以按照时间顺序获取帖子列表。 -
任务调度:当需要按优先级执行任务时,可以使用ScoredSortedSet来存储任务对象,并将任务的优先级作为分数。通过调用
range方法,可以按优先级顺序获取要执行的任务列表。 -
范围查询:ScoredSortedSet还支持范围查询操作,可以根据指定的分数范围来获取成员列表。例如,在电子商务应用程序中,可以使用ScoredSortedSet来存储商品,并将商品的价格作为分数。这样,可以方便地根据指定价格范围来获取商品列表。
aip
add(double score, V object): 将成员对象添加到集合中,并为其指定分数。removeRangeByScore(double startScore, boolean startIncluded, double endScore, boolean endIncluded): 删除给定范围内的成员。可以选择是否包含起始和结束分数。score(V object): 获取指定成员的分数。rank(V object): 获取指定成员在集合中的排名(从0开始)。count(double startScore, boolean startIncluded, double endScore, boolean endIncluded): 计算给定范围内成员的数量。可以选择是否包含起始和结束分数。range(double startScore, boolean startIncluded, double endScore, boolean endIncluded): 返回给定范围内的成员列表。可以选择是否包含起始和结束分数。reverseRank(V object): 获取指定成员在集合中的逆序排名(从0开始)。reverseRange(int startIndex, int endIndex): 返回指定范围内的成员列表,按逆序排列。
RScoredSortedSet原理
RScoredSortedSet 通过 Redis 原生的 Sorted Set 实现分布式有序集合,借助跳跃表和哈希表的高效性,结合 Lua 脚本的原子性,提供了高性能的排序、范围查询
3. Redission RAtomicLong
今天有多少订单产生,统计大屏;
有多少柜机在线;
RAtomicLong本身可以满足单次操作的原子性需求,
简单计数场景
直接使用RAtomicLong的原子方法(如incrementAndGet()),无需额外处理。
高并发场景优化
本地预生成ID缓冲池(减少Redis访问)
冷热数据分离(高频操作用RAtomicLong,低频数据用数据库)
4. RScoredSortedSet 实现LFU
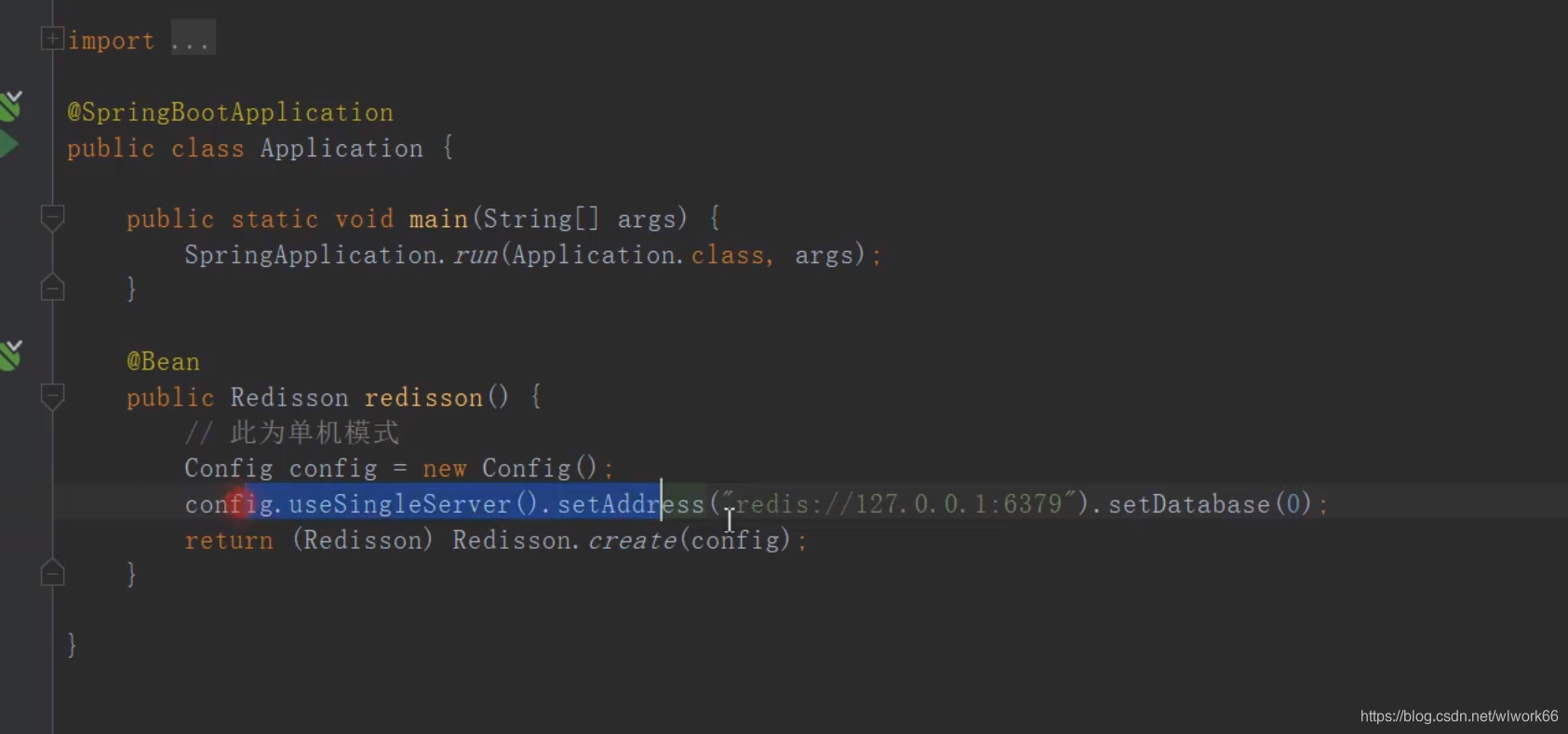
public static void main(String[] args) {
// 创建 Redisson 配置
Config config = new Config();
config.useSingleServer().setAddress("redis://127.0.0.1:6379");
// 创建 Redisson 客户端
RedissonClient redisson = Redisson.create(config);
// 获取有序集合
RScoredSortedSet<String> sortedSet = redisson.getScoredSortedSet("mySortedSet");
// 插入数据的函数
insertData(sortedSet, "data1");
insertData(sortedSet, "data2");
insertData(sortedSet, "data1"); // "data1" already exists, score should be incremented
insertData(sortedSet, "data3");
insertData(sortedSet, "data4");
insertData(sortedSet, "data5");
insertData(sortedSet, "data5");
insertData(sortedSet, "data6");
insertData(sortedSet, "data7");
insertData(sortedSet, "data8");
insertData(sortedSet, "data9");
insertData(sortedSet, "data10");
insertData(sortedSet, "data11");
insertData(sortedSet, "data12");
// 打印集合内容
System.out.println("111");
final val scoredEntries = sortedSet.entryRangeReversed(0, -1);
final val collect = scoredEntries.stream().map(ScoredEntry::getValue).collect(Collectors.toList());
System.out.println(JSONObject.toJSONString(collect));
// 获取按分数由高到低排序的所有数据
// 打印集合内容
for (ScoredEntry<String> entry : scoredEntries) {
System.out.println("Data: " + entry.getValue() + ", Score: " + entry.getScore());
}
// 关闭 Redisson 客户端
redisson.shutdown();
}
public static void insertData(RScoredSortedSet<String> sortedSet, String data) {
Double currentScore = sortedSet.getScore(data);
if (currentScore != null) {
// 数据已经存在,分数加一
sortedSet.addScore(data, 60*60*24);
} else {
// 数据不存在,插入新数据
if (sortedSet.size() < 10) {
sortedSet.add(System.currentTimeMillis()/100000, data);
} else {
// 插入新数据
sortedSet.add(System.currentTimeMillis()/100000, data);
// 获取分数最低的元素集合(有多个分数相同的情况)
Collection<String> lowestScoreElements = sortedSet.valueRange(0, 0);
// 找到插入时间最早的元素
String earliestElement = null;
long earliestTimestamp = Long.MAX_VALUE;
for (String element : lowestScoreElements) {
Double score = sortedSet.getScore(element);
if (score != null && score < earliestTimestamp) {
earliestTimestamp = score.longValue();
earliestElement = element;
}
}
// 删除分数最低且插入时间最早的元素
if (earliestElement != null) {
sortedSet.remove(earliestElement);
}
}
}
}
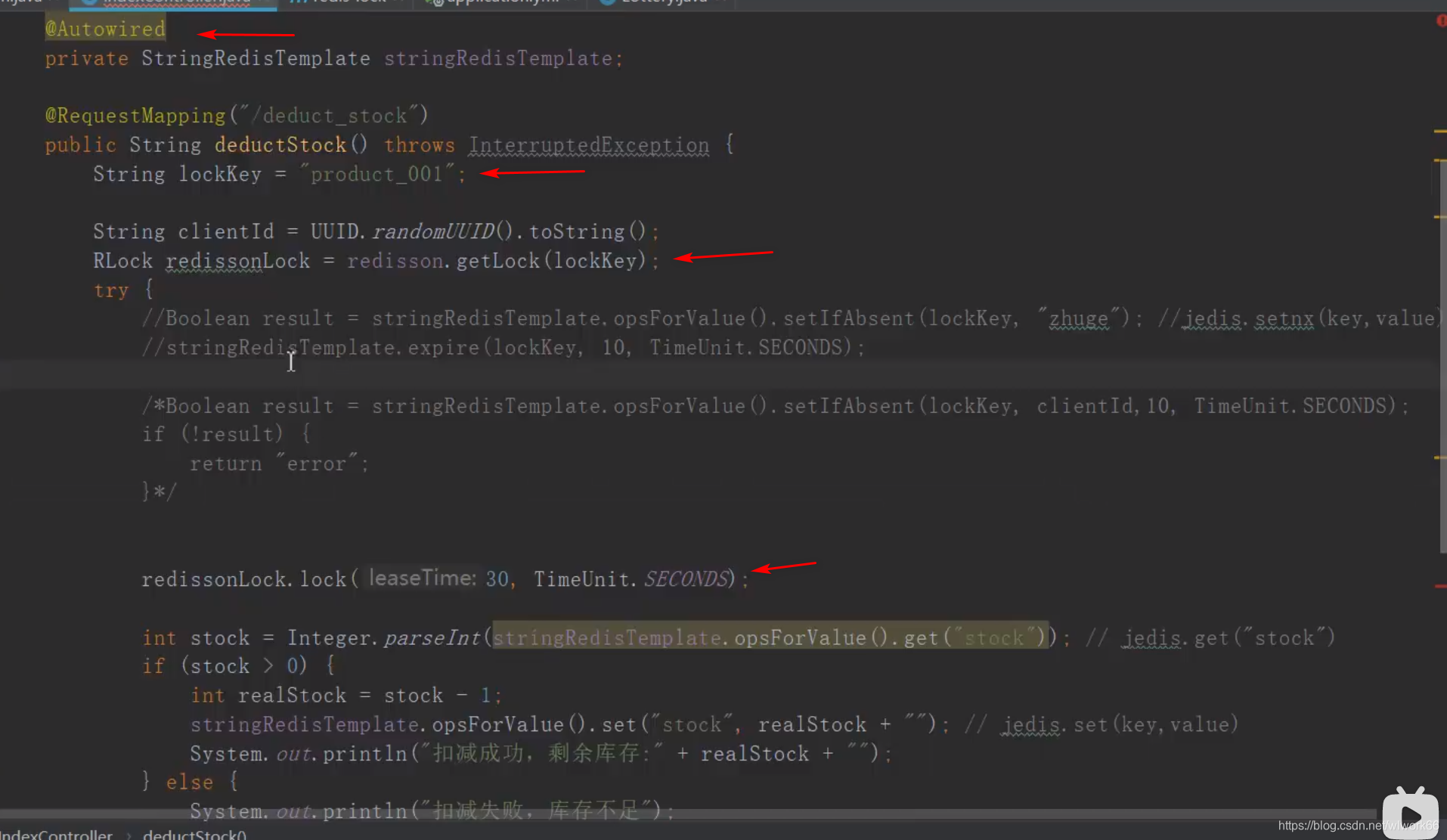
5. 分布式锁
one 原理
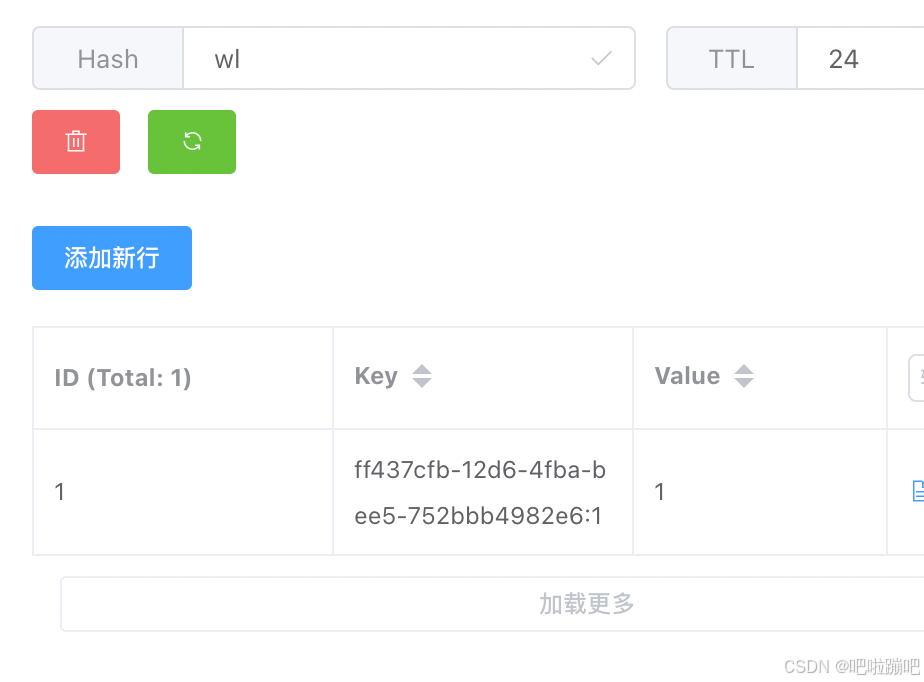
1. 锁的存储结构
Redisson 的分布式锁通过 Redis 的 Hash 结构 存储锁信息,键的格式为 锁名称(例如 myLock),字段(field)为客户端唯一标识(UUID + 线程ID),值为锁的重入次数(计数器)。例如:
HGETALL myLock
1) "b983c153-8b6a-4a7a-8e2a-3f0a7d8f3c7b:1" # 客户端ID:线程ID
2) "3" # 重入次数
2. 加锁过程(lock())
当调用 lock() 方法时,Redisson 执行以下流程:
步骤 1:尝试加锁
使用 Lua 脚本(保证原子性)尝试在 Redis 中创建锁:
- 如果锁不存在(
exists == 0),则通过hset设置锁的 Hash 字段,初始化重入次数为 1,并设置过期时间(默认 30 秒)。 - 如果锁已存在且是当前线程持有(可重入),则重入次数加 1,并更新过期时间。
- 如果锁被其他线程占用,则通过 Redis 的发布订阅机制订阅锁释放事件,进入循环等待。
-- Lua 脚本伪代码
if (redis.call('exists', KEYS[1]) == 0) then
redis.call('hset', KEYS[1], ARGV[2], 1);
redis.call('pexpire', KEYS[1], ARGV[1]);
return nil;
end;
if (redis.call('hexists', KEYS[1], ARGV[2]) == 1) then
redis.call('hincrby', KEYS[1], ARGV[2], 1);
redis.call('pexpire', KEYS[1], ARGV[1]);
return nil;
end;
return redis.call('pttl', KEYS[1]);
步骤 2:锁续期(Watchdog 机制)
如果锁获取成功,Redisson 会启动一个后台线程(看门狗),每隔 10 秒 检查锁是否仍被持有。如果是,则自动将锁的过期时间重置为 30 秒,防止业务逻辑未执行完锁被自动释放。
3. 解锁过程(unlock())
调用 unlock() 时,Redisson 通过 Lua 脚本减少重入次数,直到计数器归零后删除锁:
-- Lua 脚本伪代码
if (redis.call('hexists', KEYS[1], ARGV[3]) == 0) then
return nil;
end;
local counter = redis.call('hincrby', KEYS[1], ARGV[3], -1);
if (counter > 0) then
redis.call('pexpire', KEYS[1], ARGV[2]);
return 0;
else
redis.call('del', KEYS[1]);
redis.call('publish', KEYS[2], ARGV[1]);
return 1;
end;
- 每次解锁会将重入次数减 1,直到计数器为 0 时删除锁。
- 通过 Redis 的发布订阅机制通知等待线程锁已释放。
4. 关键特性
-
可重入性
同一线程多次获取锁时,重入次数递增,避免死锁。 -
自动续期(Watchdog)
防止因业务执行时间过长导致锁超时释放。 -
避免死锁
锁默认 30 秒过期(即使未显式释放),结合 Watchdog 续期。 -
互斥性
基于 Redis 的单线程特性,确保锁的互斥访问。
5. 高可用场景(RedLock)
在 Redis 集群模式下,Redisson 支持 RedLock 算法(多节点加锁),通过多个独立的 Redis 实例协同工作,提升分布式锁的可靠性。但 getLock 默认基于单节点实现,若需高可用需显式使用 RedissonRedLock。
总结
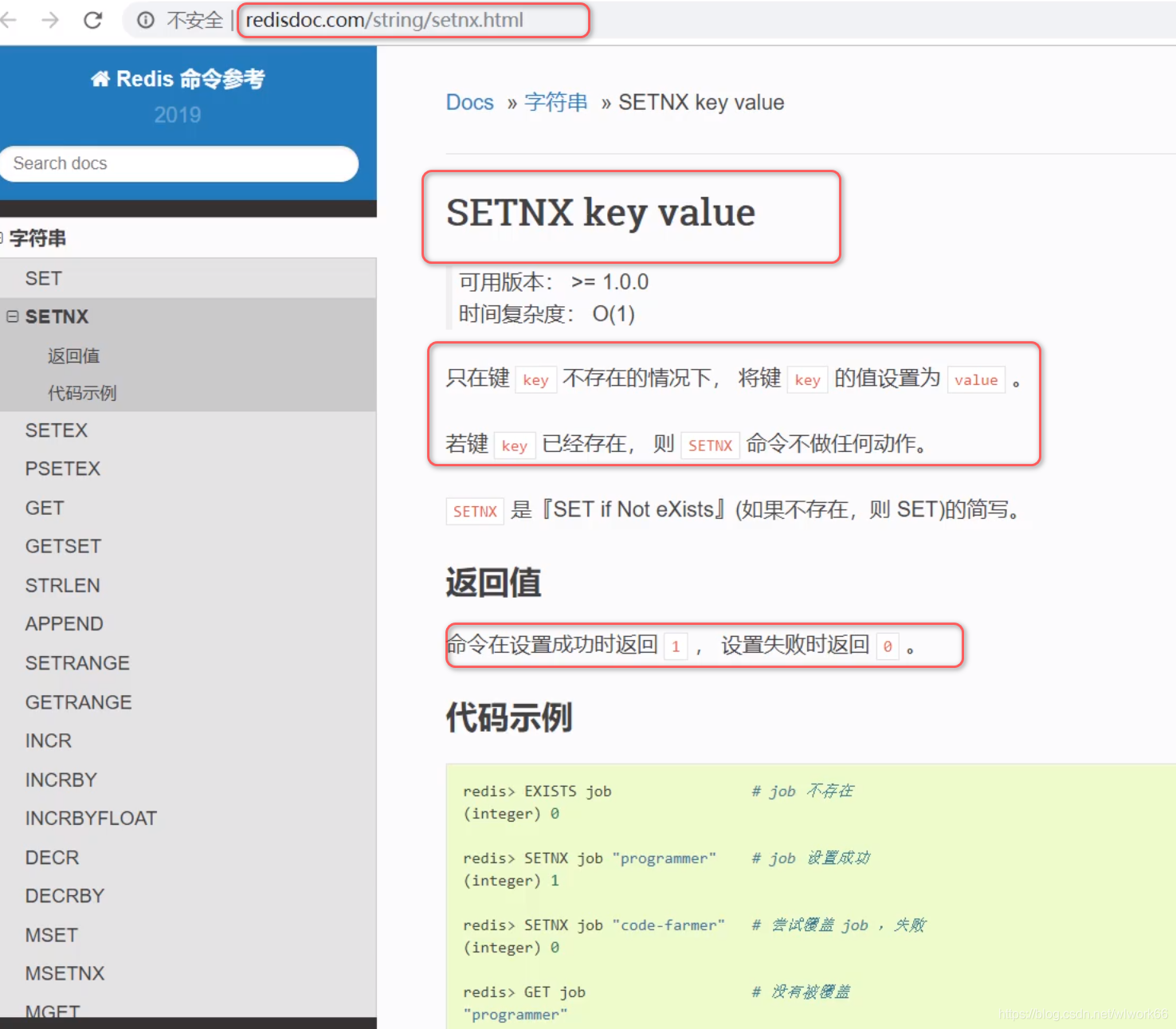
RedissonClient.getLock() 的底层实现结合了 Redis 的原子操作、Lua 脚本、发布订阅和看门狗机制,提供了一个高效、可靠的分布式锁,解决了传统 SETNX 命令的局限性(如不可重入、无自动续期等问题)。
模版代码
Lock lock = ...;
if (lock.tryLock()) {
try {
// manipulate protected state
} finally {
lock.unlock();
}
} else {
// perform alternative actions
}
6. redission实现公平锁的实现原理
- 排队机制:
-
当多个客户端尝试获取锁时,Redisson 会将它们放入一个队列中(这个队列存储在 Redis 里),按照请求的时间顺序排队。
-
只有队列中的第一个客户端才能获得锁。
- 监听机制:
-
每个客户端在尝试获取锁失败后,会订阅一个特定的频道(channel),以监听前一个释放锁的事件。
-
当前一个客户端释放锁时,它会发布一个消息到该频道,通知下一个客户端来尝试获取锁。
- 超时与重试:
-
客户端在等待锁的过程中会有一个超时时间,如果超时仍未获得锁,则放弃获取锁并移出队列。
-
客户端可以设置等待锁的最长时间和锁的持有时间。
7. 再谈公平锁
Redisson 公平锁实现原理与最佳实践
Redisson 的公平锁(Fair Lock)是一种分布式锁实现,它按照请求锁的顺序来分配锁,确保所有等待锁的客户端按照先来先服务的原则获得锁资源。
公平锁的实现原理
Redisson 公平锁基于 Redis 的 Lua 脚本和发布/订阅机制实现,核心设计如下:
1. 排队机制
- 使用 Redis 的 List 数据结构作为等待队列
- 每个客户端尝试获取锁时,会生成唯一标识并加入队列尾部
- 只有队列头部的客户端才能获得锁
2. 锁获取流程
3. 关键组件
- 等待队列:Redis List 存储等待客户端(键格式:
redisson_lock_queue:{lockName}) - 超时集合:Redis Sorted Set 跟踪客户端等待时间(键格式:
redisson_lock_timeout:{lockName}) - 订阅通道:Redis Pub/Sub 通知锁释放事件
公平锁的使用方式
基本用法
import org.redisson.api.RLock;
import org.redisson.api.RedissonClient;
public class FairLockExample {
private final RedissonClient redissonClient;
public void performTaskWithFairLock() {
RLock fairLock = redissonClient.getFairLock("myFairLock");
try {
// 尝试获取锁,最多等待10秒,锁持有时间30秒
if (fairLock.tryLock(10, 30, TimeUnit.SECONDS)) {
// 执行需要锁保护的代码
executeCriticalSection();
}
} catch (InterruptedException e) {
Thread.currentThread().interrupt();
} finally {
if (fairLock.isLocked() && fairLock.isHeldByCurrentThread()) {
fairLock.unlock();
}
}
}
private void executeCriticalSection() {
// 关键业务逻辑
}
}
最佳实践建议
-
合理设置等待时间
// 根据业务场景设置合理的等待时间 boolean acquired = fairLock.tryLock(15, 60, TimeUnit.SECONDS); -
避免锁泄漏
finally { // 确保只有持有锁的线程才能解锁 if (fairLock.isHeldByCurrentThread()) { fairLock.unlock(); } } -
处理中断异常
catch (InterruptedException e) { Thread.currentThread().interrupt(); // 执行清理操作或重试逻辑 }
公平锁 vs 非公平锁
| 特性 | 公平锁 | 非公平锁 |
|---|---|---|
| 获取顺序 | 先进先出(FIFO) | 随机竞争 |
| 性能 | 较低(维护队列开销) | 较高 |
| 饥饿问题 | 不会发生 | 可能发生 |
| 实现复杂度 | 较高 | 较低 |
| 适用场景 | 需要严格顺序执行的业务 | 高并发、低延迟场景 |
fair and unfair
公平用的队列, 非公平用的发布订阅
Redisson的公平锁和非公平锁在锁释放通知机制上有重要区别。下面我将详细解释两种锁在锁释放时如何通知等待的客户端:
1. 公平锁(Fair Lock)的通知机制
公平锁使用队列机制保证获取锁的顺序(FIFO)。当锁释放时:
-
仅通知队列中的第一个等待客户端(即等待时间最长的客户端)
-
其他等待客户端不会收到通知,直到它们成为队列头部
实现关键点:
-
使用Redis的List结构作为等待队列(键:
redisson_lock_queue:{lockName}) -
每个客户端在队列中的位置固定
-
锁释放时,Redis执行Lua脚本:
-
从队列头部取出第一个客户端
-
向该客户端的专属频道发布通知
2. 非公平锁(Non-fair Lock)的通知机制
非公平锁在锁释放时:
-
向所有等待客户端广播锁释放消息
-
所有收到通知的客户端会同时竞争锁
最佳实践建议
-
需要严格顺序:使用公平锁(如订单处理、资源分配)
-
追求高吞吐:使用非公平锁(如库存扣减)
-
避免大量等待:
-
设置合理的锁等待超时时间
-
使用
tryLock而非无限制的lock
- 监控等待队列长度:
RLock lock = redisson.getFairLock("fairLock");
// 获取等待线程数(Redisson 3.17+)
int waitCount = lock.getQueueSize();
结论
-
公平锁:锁释放时只通知等待队列中的第一个客户端(甲),确保获取顺序。
-
非公平锁:锁释放时向所有等待客户端广播通知,引发竞争。
这种设计差异使得公平锁能保证先到先得的公平性,而非公平锁则通过竞争获得更高的吞吐量。
高级特性
1. 锁续期(Watchdog)
当不指定锁超时时间时,Redisson 会启动看门狗线程自动续期:
// 无超时时间参数,启动自动续期
fairLock.lock();
// 后台线程每10秒续期一次(默认1/3看门狗超时时间)
2. 多锁管理(MultiLock)
RLock lock1 = redissonClient.getFairLock("lock1");
RLock lock2 = redissonClient.getFairLock("lock2");
RedissonMultiLock multiLock = new RedissonMultiLock(lock1, lock2);
multiLock.lock();
try {
// 同时获得多个锁
} finally {
multiLock.unlock();
}
性能优化建议
- 减少锁粒度:根据业务拆分多个细粒度锁
- 设置合理超时:避免锁持有时间过长
- 监控锁等待时间:
long waitTime = System.currentTimeMillis(); if (fairLock.tryLock()) { long acquiredTime = System.currentTimeMillis() - waitTime; // 记录等待时间指标 } - 避免嵌套锁:防止死锁发生
典型应用场景
- 订单处理系统:按照订单创建顺序处理
- 资源分配系统:公平分配有限资源
- 定时任务调度:确保任务按提交顺序执行
- 分布式工作队列:保证任务处理顺序性
通过合理使用 Redisson 公平锁,可以在分布式系统中实现公平的资源分配,避免某些客户端长时间等待导致的"饥饿"问题,特别适合需要严格顺序执行的业务场景。
8. A B 两个服务的客户端唯一标识应该不一样,那么 A加的锁,B识别不到吧,那么自己加自己的锁,就不是分布式的呀
我们讨论的是Redisson分布式锁的实现机制。您提到的结构确实如此:Redisson使用Redis的Hash结构存储锁信息,其中:
-
键(key)是锁的名称,例如"myLock"。
-
字段(field)是客户端唯一标识,由UUID(每个Redisson客户端实例有一个唯一的UUID)和线程ID组成。
-
值(value)是锁的重入次数(计数器)。
现在,问题来了:服务A和服务B是两个不同的服务,它们各自启动一个Redisson客户端实例,那么它们的UUID肯定是不同的。因此,服务A加的锁,服务B在尝试获取同一把锁(同一个key)时,看到的Hash中的field(即客户端标识)是服务A的,而不是自己的。那么,服务B如何知道自己不能获取锁呢?这会不会导致服务B自己加自己的锁,从而破坏了分布式锁的互斥性?
答案是:不会。因为Redisson的分布式锁机制保证了互斥性。下面我来详细解释:
- 加锁机制:
当服务A要获取锁"myLock"时,它会执行一段Lua脚本(保证原子性):
-
首先检查锁是否存在(即是否存在key为"myLock"的Hash)。
-
如果不存在,则创建这个Hash,并设置一个字段(field为服务A的UUID+线程ID),值为1(重入次数)。同时设置一个过期时间(避免死锁)。
-
如果存在,再检查这个Hash中是否已经包含服务A的UUID+线程ID的字段:
-
如果存在,则重入:将值加1,并重新设置过期时间。
-
如果不存在,说明是其他客户端(比如服务B)持有锁,那么加锁失败。
所以,服务B在尝试获取锁时,会执行同样的Lua脚本,发现锁已经存在(服务A创建的),并且字段不是自己的,那么它就会加锁失败。
- 锁互斥:
服务B在加锁失败后,并不会自己创建一个新的锁(即不会覆盖服务A的锁),而是会进入等待状态(通过Redis的发布订阅机制监听锁释放事件),或者根据tryLock的参数进行重试或直接返回失败。
- 解锁机制:
当服务A释放锁时,它会执行另一个Lua脚本:
-
检查锁的Hash中对应自己客户端标识(UUID+线程ID)的值(重入次数):
-
如果值大于1,则减1(因为可重入,可能多次加锁)。
-
如果值等于1,则删除这个字段,并且删除整个key(因为Hash空了)。
同时,服务A会发布一个消息到对应的频道,通知其他等待的客户端(如服务B)锁已经被释放。
因此,整个过程中,虽然服务A和服务B有不同的客户端标识,但Redisson通过上述机制保证了同一时间只有一个客户端(即一个服务的一个线程)能持有锁。
所以,您担心的“自己加自己的锁”的情况不会发生。服务B在尝试获取锁时,会检查当前锁的持有者是否是它自己(通过自己的UUID+线程ID去匹配),如果不是,它就不会获取锁,也不会覆盖已有的锁。
总结:Redisson的分布式锁正是通过这种客户端唯一标识来区分不同的客户端,从而保证只有持有锁的客户端才能释放锁,并且不同客户端之间互斥地获取锁。
补充一点:同一个服务内的不同线程,它们的客户端UUID相同(因为同一个Redisson实例),但线程ID不同,所以同一个服务内的不同线程也会互斥(除非是同一个线程的重入)

















 1199
1199



 到【灌水乐园】发言
到【灌水乐园】发言








