






 本文介绍如何使用BeautifulSoup进行网页解析,包括安装配置、基本用法等,并通过实例演示了如何提取HTML标签、文本及属性。
本文介绍如何使用BeautifulSoup进行网页解析,包括安装配置、基本用法等,并通过实例演示了如何提取HTML标签、文本及属性。
安装
pip install beautifulsoup
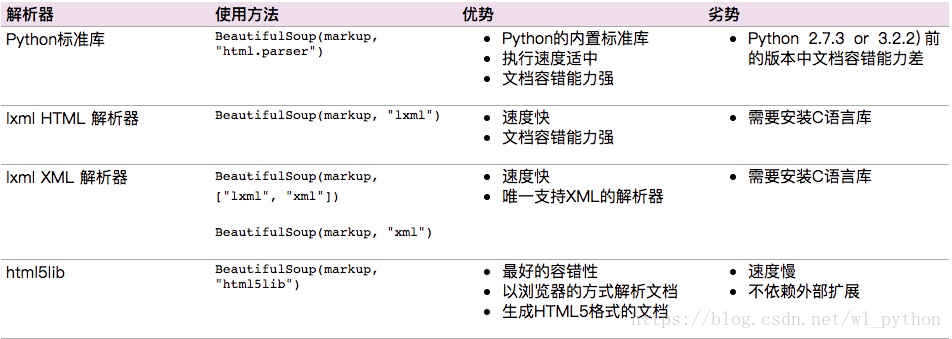
解析器
Beautiful Soup支持Python标准库中的HTML解析器,还支持一些第三方的解析器,如果我们不安装它,则 Python 会使用 Python默认的解析器,lxml 解析器更加强大,速度更快,推荐安装。
简单实用
from bs4 import BeautifulSoup
html='<p>hello<h1 class= big><span id="num1">test</span><span id=num2>test2</span></h1><h2>python</h2></p>'
#解析html对象
soup=BeautifulSoup(html,'html.parser')
print(soup)
#prettify()方法 按格式返回html,可以补齐缺失的引号
fixed_html=soup.prettify()
print(fixed_html)
#按标签查找,返回第一个符合的标签
print(soup.h1)
print(soup.span)
#标签名
print(soup.h1.name)
#返回标签的文本内容
print(soup.span.string)
#获取嵌套标签的内童
print(soup.h1.span.string)
#返回父节点信息
print(soup.span.parent)
print(soup.span.parent.name)
#返回第一个查找道德属性值
print(soup.span['id'])
#返回一个列表,包含所有的标签信息
print(soup.find_all('span'))
#按属性查找指定的标签信息
print(soup.find(id='num2'))
#获取所有的文本信息,返回一个字符串
print(soup.get_text())
#link.get('href')可以获取标签中的链接
######contents和children的用法:返回所有子节点的信息,contents返回的是一个列表,
# 而children返回的时已迭代器,需要for循环来查看
print(soup.p.contents)
print(soup.p.children)
for i in soup.p.children:
print(i)

















 56万+
56万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









