




📕目录
具体集合(ConcreteAggregate):ArrayAggregate
具体迭代器(ConcreteIterator):ArrayIterator
三、实战案例 2:链表集合的迭代器(解决 “结构变化” 问题)
四、实战案例 3:带过滤功能的迭代器(解决 “复杂遍历” 问题)
1. 第一步:定义过滤迭代器(FilterEvenIterator)
九、结语:迭代子模式的核心不是 “写迭代器”,而是 “解耦”

class 卑微码农:
def __init__(self):
self.技能 = ['能读懂十年前祖传代码', '擅长用Ctrl+C/V搭建世界', '信奉"能跑就别动"的玄学']
self.发量 = 100 # 初始发量
self.咖啡因耐受度 = '极限'
def 修Bug(self, bug):
try:
# 试图用玄学解决问题
if bug.严重程度 == '离谱':
print("这一定是环境问题!")
else:
print("让我看看是谁又没写注释...哦,是我自己。")
except Exception as e:
# 如果try块都救不了,那就...
print("重启一下试试?")
self.发量 -= 1 # 每解决一个bug,头发-1
# 实例化一个我
我 = 卑微码农()引言:你是不是也被 “遍历” 坑过?
作为一名 C++ 开发者,你一定写过不少遍历集合的代码吧?

比如遍历数组,我们会写for (int i = 0; i < arrSize; i++) { ... };遍历链表,又要改成ListNode* p = head; while (p != nullptr) { ...; p = p->next; }。要是哪天产品说 “把数组换成链表存数据”,你就得把所有遍历数组的代码逐个改成链表的遍历逻辑 —— 这活儿又繁琐又容易出错,改漏一个地方就可能出 bug。
再比如,要是需要两种遍历方式:一种正向遍历所有元素,一种只遍历偶数元素,你是不是得写两套不同的循环?如果多个地方都要这两种遍历,重复代码就会堆得像小山一样。更麻烦的是,要是集合的内部结构不想暴露给外部(比如你封装了一个复杂的缓存集合,不想让调用者知道你用了哈希表还是红黑树),直接让外部写遍历逻辑就等于把内部实现裸奔了。
这些问题,其实早在几十年前就被设计模式解决了 —— 它就是迭代子模式(Iterator Pattern)。今天这篇文章,咱们就从实际开发痛点出发,用通俗的语言讲透迭代子模式,再结合 3 个 C++ 实战案例,让你不仅懂原理,还能直接用到项目里。
一、什么是迭代子模式?用 “图书馆” 类比秒懂

先别着急记定义,咱们用一个生活场景类比:你去图书馆找书,不需要知道书架是怎么排列的(是按类别分三层,还是按作者首字母分区域),只需要找图书管理员 —— 他会带你找到你要的书,甚至能按你的需求(比如 “找 2024 年出版的计算机书籍”)筛选着给你推荐。
在这里:
- 图书馆 = 我们代码里的 “集合(Aggregate)”:负责存储数据(书籍),但不对外暴露内部结构(书架排列方式)。
- 图书管理员 = “迭代器(Iterator)”:负责帮你遍历 / 筛选数据(找书),你只需要跟管理员交互(问 “还有下一本吗?”“下一本是什么?”),不用管图书馆内部怎么运作。
所以,迭代子模式的核心思想很简单:把 “集合的存储” 和 “集合的遍历” 拆分开,让遍历逻辑独立于集合本身。不管集合是数组、链表还是哈希表,不管你要正向遍历、反向遍历还是筛选遍历,只需要通过统一的 “迭代器” 接口操作,不用修改集合代码,也不用重复写遍历逻辑。
官方定义(咱们通俗化一下):迭代子模式提供一种方法顺序访问一个聚合对象(集合)中的各个元素,而又不暴露该对象的内部表示。
二、迭代子模式的 4 个核心角色:职责要分清
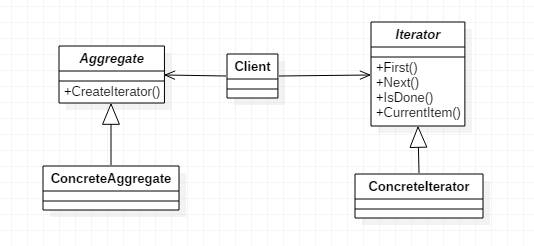
迭代子模式虽然简单,但要写好代码,得先明确 4 个核心角色的职责 —— 就像一个团队里,有人负责定规则,有人负责做执行,分工明确才不会乱。
我们用 C++ 的类结构来对应这 4 个角色,每个角色的作用和代码模板都给你列清楚:
| 角色名称 | 核心职责 | C++ 中的体现(类 / 接口) |
|---|---|---|
| 抽象迭代器(Iterator) | 定义遍历集合的 “规则接口”,比如 “有没有下一个元素”“获取下一个元素” | 纯虚基类,包含hasNext()、next()等纯虚函数 |
| 具体迭代器(ConcreteIterator) | 实现抽象迭代器的接口,持有集合的引用,跟踪当前遍历位置(比如数组的索引) | 继承抽象迭代器,实现虚函数,维护遍历状态 |
| 抽象集合(Aggregate) | 定义 “创建迭代器” 的接口,告诉外界 “我能生成遍历自己的迭代器” | 纯虚基类,包含createIterator()纯虚函数 |
| 具体集合(ConcreteAggregate) | 实现抽象集合的接口,返回对应的具体迭代器,同时负责存储数据 | 继承抽象集合,实现createIterator(),管理数据 |
光看表格可能有点抽象,咱们先写一套 “最小可用” 的代码框架,把这 4 个角色串起来 —— 后面的实战案例都是在这个框架上扩展的。
1. 第一步:定义抽象迭代器(Iterator)
抽象迭代器是 “遍历规则” 的契约,必须包含两个核心方法:
hasNext():判断是否还有未访问的元素,返回bool。next():获取下一个元素,并移动遍历指针,返回元素的引用(或指针)。
为了通用性,我们用模板类(template)实现,这样不管集合存的是int、string还是自定义对象,都能复用这个接口。
// 抽象迭代器:定义遍历接口(模板类,支持任意元素类型)
template <typename T>
class Iterator {
public:
virtual ~Iterator() {} // 虚析构,确保子类析构时能调用到
// 核心方法1:判断是否还有下一个元素
virtual bool hasNext() const = 0;
// 核心方法2:获取下一个元素,并移动到下一个位置
virtual T& next() = 0;
// 可选方法:删除当前元素(根据需求实现,不是必须的)
virtual void remove() {
// 默认空实现,子类需要则重写
throw std::runtime_error("当前迭代器不支持删除操作");
}
};
2. 第二步:定义抽象集合(Aggregate)
抽象集合是 “创建迭代器” 的契约,只需要一个核心方法:createIterator(),返回一个指向抽象迭代器的指针(多态的关键,确保不同集合能返回不同迭代器)。
同样用模板类,和迭代器的元素类型保持一致:
// 抽象集合:定义创建迭代器的接口(模板类)
template <typename T>
class Aggregate {
public:
virtual ~Aggregate() {}
// 核心方法:创建一个遍历当前集合的迭代器
virtual Iterator<T>* createIterator() const = 0;
// 集合的通用方法(纯虚函数,子类实现)
virtual void add(const T& element) = 0; // 添加元素
virtual size_t getSize() const = 0; // 获取元素个数
};
3. 第三步:实现具体集合与具体迭代器(以数组集合为例)
接下来,我们实现第一个具体场景:存储int类型的 “数组集合”,以及对应的 “数组迭代器”。
具体集合(ConcreteAggregate):ArrayAggregate
这个类负责用动态数组存储数据,实现add()、getSize(),以及关键的createIterator()—— 返回ArrayIterator对象。
// 具体集合:基于动态数组的集合
template <typename T>
class ArrayAggregate : public Aggregate<T> {
private:
std::vector<T> elements; // 用vector存储数据(底层是动态数组)
public:
// 添加元素
void add(const T& element) override {
elements.push_back(element);
}
// 获取元素个数
size_t getSize() const override {
return elements.size();
}
// 创建迭代器:返回数组对应的迭代器
Iterator<T>* createIterator() const override {
// 把当前集合的引用传给迭代器,让迭代器能访问集合的数据
return new ArrayIterator<T>(*this);
}
// 友元声明:让ArrayIterator能访问当前集合的私有成员(elements)
friend class ArrayIterator<T>;
};
具体迭代器(ConcreteIterator):ArrayIterator
这个类需要:
- 持有
ArrayAggregate的引用(才能访问数组数据)。 - 用
currentIndex跟踪当前遍历位置。 - 实现
hasNext()和next()。
// 具体迭代器:遍历ArrayAggregate的迭代器
template <typename T>
class ArrayIterator : public Iterator<T> {
private:
const ArrayAggregate<T>& aggregate; // 持有具体集合的引用
size_t currentIndex; // 当前遍历的索引(状态)
public:
// 构造函数:初始化时从索引0开始遍历
ArrayIterator(const ArrayAggregate<T>& agg)
: aggregate(agg), currentIndex(0) {}
// 判断是否还有下一个元素:索引 < 集合大小
bool hasNext() const override {
return currentIndex < aggregate.elements.size();
}
// 获取下一个元素:返回当前索引的元素,并递增索引
T& next() override {
// 先判断是否有下一个元素,避免越界
if (!hasNext()) {
throw std::out_of_range("迭代器已遍历到末尾,无下一个元素");
}
// 返回当前元素,并将索引+1(移动到下一个位置)
return aggregate.elements[currentIndex++];
}
};
4. 第四步:测试第一个案例 —— 用迭代器遍历数组集合
写个main函数测试一下,看看迭代器怎么用。注意:迭代器是new出来的,用完要记得delete(或者用智能指针,后面会优化)。
#include <iostream>
#include <vector>
#include <stdexcept>
using namespace std;
// (前面的抽象迭代器、抽象集合、ArrayAggregate、ArrayIterator代码要放在这里)
int main() {
// 1. 创建具体集合(数组集合)
ArrayAggregate<int> numAggregate;
// 2. 往集合里加元素
numAggregate.add(10);
numAggregate.add(20);
numAggregate.add(30);
numAggregate.add(40);
// 3. 获取迭代器(多态:父类指针指向子类对象)
Iterator<int>* iterator = numAggregate.createIterator();
// 4. 用迭代器遍历集合(统一接口,不用管集合是数组)
cout << "遍历数组集合的元素:";
while (iterator->hasNext()) {
int& num = iterator->next();
cout << num << " "; // 输出:10 20 30 40
}
cout << endl;
// 5. 释放迭代器内存(避免内存泄漏)
delete iterator;
return 0;
}
运行结果会输出10 20 30 40,这说明咱们的迭代子模式框架跑通了!
这里有个关键点:遍历代码完全没依赖 “数组” 这个具体结构。如果后面把ArrayAggregate换成 “链表集合”,只要链表集合也返回符合Iterator接口的迭代器,main里的遍历代码一行都不用改 —— 这就是迭代子模式的核心价值。
三、实战案例 2:链表集合的迭代器(解决 “结构变化” 问题)
刚才的案例是数组,现在咱们来实现一个 “链表集合”,看看迭代器怎么适配不同的集合结构。
首先,需要定义链表的节点类,然后实现 “链表集合(ListAggregate)” 和 “链表迭代器(ListIterator)”。
1. 第一步:定义链表节点类
// 链表节点类(存储T类型数据)
template <typename T>
class ListNode {
public:
T data; // 节点数据
ListNode* next; // 指向 next 节点的指针
ListNode(const T& d) : data(d), next(nullptr) {}
~ListNode() {
// 析构时递归删除下一个节点(避免内存泄漏)
if (next != nullptr) {
delete next;
}
}
};
2. 第二步:实现链表集合(ListAggregate)
// 具体集合:基于单向链表的集合
template <typename T>
class ListAggregate : public Aggregate<T> {
private:
ListNode<T>* head; // 链表头节点
size_t size; // 链表元素个数
public:
// 构造函数:初始化空链表
ListAggregate() : head(nullptr), size(0) {}
// 析构函数:删除整个链表(避免内存泄漏)
~ListAggregate() {
if (head != nullptr) {
delete head; // ListNode的析构会递归删除后续节点
}
}
// 添加元素:从链表尾部插入
void add(const T& element) override {
ListNode<T>* newNode = new ListNode<T>(element);
if (head == nullptr) {
head = newNode; // 空链表时,新节点作为头节点
} else {
// 找到链表尾部
ListNode<T>* cur = head;
while (cur->next != nullptr) {
cur = cur->next;
}
cur->next = newNode; // 尾部插入新节点
}
size++;
}
// 获取元素个数
size_t getSize() const override {
return size;
}
// 创建迭代器:返回链表对应的迭代器
Iterator<T>* createIterator() const override {
return new ListIterator<T>(*this);
}
// 友元声明:让ListIterator能访问私有成员(head)
friend class ListIterator<T>;
};
3. 第三步:实现链表迭代器(ListIterator)
链表的迭代器不需要索引,而是用currentNode跟踪当前节点:
// 具体迭代器:遍历ListAggregate的迭代器
template <typename T>
class ListIterator : public Iterator<T> {
private:
const ListAggregate<T>& aggregate; // 持有链表集合的引用
ListNode<T>* currentNode; // 当前遍历的节点(状态)
public:
// 构造函数:初始化时指向链表头节点
ListIterator(const ListAggregate<T>& agg)
: aggregate(agg), currentNode(agg.head) {}
// 判断是否还有下一个元素:当前节点不为空
bool hasNext() const override {
return currentNode != nullptr;
}
// 获取下一个元素:返回当前节点的数据,并移动到下一个节点
T& next() override {
if (!hasNext()) {
throw std::out_of_range("迭代器已遍历到末尾,无下一个元素");
}
ListNode<T>* temp = currentNode; // 保存当前节点
currentNode = currentNode->next; // 移动到下一个节点
return temp->data; // 返回当前节点的数据
}
};
4. 第四步:测试链表集合的遍历(遍历代码完全复用)
咱们修改main函数,把ArrayAggregate换成ListAggregate,看看遍历代码是不是真的不用改:
int main() {
// 1. 创建具体集合(链表集合,替换了之前的数组集合)
ListAggregate<int> numAggregate;
// 2. 往集合里加元素(代码和之前一样)
numAggregate.add(10);
numAggregate.add(20);
numAggregate.add(30);
numAggregate.add(40);
// 3. 获取迭代器(代码和之前一样)
Iterator<int>* iterator = numAggregate.createIterator();
// 4. 用迭代器遍历集合(代码完全没改!)
cout << "遍历链表集合的元素:";
while (iterator->hasNext()) {
int& num = iterator->next();
cout << num << " "; // 输出:10 20 30 40
}
cout << endl;
// 5. 释放迭代器内存
delete iterator;
return 0;
}
运行结果和之前一样!这就证明了:不管集合是数组还是链表,只要实现了统一的迭代器接口,遍历逻辑就能完全复用。如果你的项目里有多种集合类型,用迭代子模式能省不少重复代码。
四、实战案例 3:带过滤功能的迭代器(解决 “复杂遍历” 问题)

除了适配不同集合,迭代子模式还能轻松实现 “复杂遍历”—— 比如只遍历偶数、只遍历长度大于 5 的字符串。
这种需求不用修改集合,只需要写一个 “过滤迭代器”,包装一个普通迭代器,在next()的时候跳过不符合条件的元素。
咱们以 “筛选偶数” 为例,实现一个FilterEvenIterator:
1. 第一步:定义过滤迭代器(FilterEvenIterator)
这个迭代器需要:
- 包装一个普通迭代器(比如
ArrayIterator或ListIterator)。 - 定义过滤条件(这里是 “是否为偶数”)。
- 在
hasNext()和next()中处理过滤逻辑。
// 具体迭代器:带过滤功能的迭代器(筛选偶数)
template <typename T>
class FilterEvenIterator : public Iterator<T> {
private:
Iterator<T>* baseIterator; // 包装的基础迭代器
T* nextElement; // 缓存符合条件的下一个元素(避免重复判断)
// 辅助函数:找到下一个符合条件的元素(偶数)
void findNextEven() {
nextElement = nullptr; // 先置空
// 遍历基础迭代器,直到找到偶数或遍历结束
while (baseIterator->hasNext()) {
T& elem = baseIterator->next();
if (elem % 2 == 0) { // 过滤条件:是偶数
nextElement = &elem;
break; // 找到后退出循环
}
}
}
public:
// 构造函数:传入要包装的基础迭代器
FilterEvenIterator(Iterator<T>* baseIt)
: baseIterator(baseIt), nextElement(nullptr) {
// 初始化时就找到第一个符合条件的元素
findNextEven();
}
// 析构函数:释放基础迭代器
~FilterEvenIterator() {
delete baseIterator;
}
// 判断是否还有符合条件的元素:nextElement不为空
bool hasNext() const override {
return nextElement != nullptr;
}
// 获取下一个符合条件的元素,并找好下下一个
T& next() override {
if (!hasNext()) {
throw std::out_of_range("无符合条件的下一个元素");
}
T& result = *nextElement; // 保存当前符合条件的元素
findNextEven(); // 提前找到下一个符合条件的元素
return result;
}
};
2. 第二步:修改抽象集合,支持创建过滤迭代器(可选)
为了方便使用,我们可以在抽象集合或具体集合中加一个createFilterEvenIterator()方法,直接返回过滤迭代器:
// 在ArrayAggregate中添加方法(ListAggregate同理)
template <typename T>
class ArrayAggregate : public Aggregate<T> {
// (前面的代码不变)
// 新增:创建过滤偶数的迭代器
Iterator<T>* createFilterEvenIterator() const {
// 先创建基础迭代器,再包装成过滤迭代器
return new FilterEvenIterator<T>(this->createIterator());
}
};
3. 第三步:测试过滤迭代器
int main() {
// 1. 创建数组集合,添加元素(包含奇数和偶数)
ArrayAggregate<int> numAggregate;
numAggregate.add(11);
numAggregate.add(12);
numAggregate.add(13);
numAggregate.add(14);
numAggregate.add(15);
numAggregate.add(16);
// 2. 获取过滤迭代器(筛选偶数)
Iterator<int>* evenIterator = numAggregate.createFilterEvenIterator();
// 3. 遍历筛选后的元素
cout << "筛选后的偶数元素:";
while (evenIterator->hasNext()) {
int& num = evenIterator->next();
cout << num << " "; // 输出:12 14 16
}
cout << endl;
// 4. 释放迭代器
delete evenIterator;
return 0;
}
运行结果会输出12 14 16,正好是集合中的所有偶数。如果后面需要筛选 “大于 15 的数”,只需要再写一个FilterGreaterThan15Iterator,完全不用改集合代码 —— 这就是迭代子模式的灵活性。
五、C++ STL 中的迭代子模式:你每天都在用来着!

其实,你每天用的 C++ STL,就是迭代子模式的 “教科书级实现”。比如vector、list、map这些容器,都自带迭代器,用法和咱们前面写的一模一样。
咱们来对比一下 STL 和咱们自己实现的迭代子模式:
| 我们实现的角色 | STL 中的对应实现 | 说明 |
|---|---|---|
| 抽象集合(Aggregate) | std::vector、std::list等容器 | STL 容器就是具体集合,不用显式抽象类 |
| 抽象迭代器(Iterator) | std::iterator(C++17 前) | STL 迭代器的基类,定义了迭代器的类型特性 |
| 具体迭代器 | vector<int>::iterator、list<int>::iterator | 对应容器的具体迭代器,实现遍历逻辑 |
createIterator() | begin()、end() | STL 用begin()返回迭代器,end()返回尾后迭代器 |
比如遍历std::vector的代码:
#include <vector>
#include <iostream>
using namespace std;
int main() {
vector<int> vec = {1,2,3,4};
// 获取迭代器(begin() = createIterator())
vector<int>::iterator it = vec.begin();
// 遍历(hasNext() = it != vec.end(),next() = *it++)
while (it != vec.end()) {
cout << *it << " ";
++it;
}
return 0;
}
这段代码和咱们前面写的迭代器遍历逻辑完全一致!STL 的迭代器还支持更丰富的操作,比如随机访问(vector的迭代器可以it + 2)、反向遍历(reverse_iterator),本质上都是 “具体迭代器” 的不同实现。
知道了 STL 的迭代器是迭代子模式,你就能更深刻地理解为什么vector和list的迭代器用法相似但底层实现不同 —— 因为它们都遵循了迭代子模式的契约。
六、迭代子模式的优缺点:别啥场景都用

迭代子模式虽好,但不是万能的。咱们客观分析一下它的优缺点,避免滥用。
优点:
- 解耦集合与遍历:集合只负责存数据,遍历交给迭代器。修改集合结构(比如数组改链表),遍历代码不用改;修改遍历逻辑(比如正向改反向),集合代码不用改。
- 统一遍历接口:不管是
vector、list还是自定义集合,都用hasNext()/next()(或 STL 的it++)遍历,降低学习成本和代码冗余。 - 支持多遍历方式:一个集合可以有多个迭代器(比如普通迭代器、过滤迭代器、反向迭代器),互不干扰。
- 隐藏集合内部结构:外部只通过迭代器访问元素,不用知道集合是用数组、链表还是哈希表实现的,符合 “封装” 原则。
缺点:
- 增加类数量:每个集合可能对应多个迭代器,会让代码中的类数量增加(比如
ArrayAggregate对应ArrayIterator、FilterEvenIterator)。 - 简单遍历有冗余:如果只是遍历一个简单的数组,直接用
for (int i=0; i<len; i++)比写迭代器更简单。迭代子模式更适合复杂场景(多集合、多遍历方式)。 - 迭代器失效问题:这是 C++ 开发者常踩的坑 —— 比如遍历
vector时用erase(it),会导致迭代器失效(因为vector删除元素后会移动后续元素,迭代器指向的位置变了)。解决办法是用it = vec.erase(it),让erase()返回新的有效迭代器。
七、迭代子模式的适用场景:别用错地方
知道了优缺点,咱们再说说什么时候该用迭代子模式:
- 你有多种集合类型,需要统一遍历接口时:比如项目里同时用了数组、链表、哈希表,想让遍历代码一致,不用写多套循环。
- 你需要多种遍历方式时:比如正向遍历、反向遍历、筛选遍历、排序后遍历,不想在集合里写一堆遍历方法。
- 你想隐藏集合的内部结构时:比如你封装了一个复杂的缓存类(底层用红黑树),不想让调用者知道红黑树的实现细节,只暴露迭代器让他们遍历缓存数据。
- 你想避免遍历代码重复时:比如多个地方都要遍历同一个集合,用迭代器可以把遍历逻辑抽出来,不用每个地方都写一遍循环。
八、扩展:其他语言中的迭代子模式
迭代子模式不是 C++ 独有的,几乎所有主流语言都有实现,原理都一样,只是语法不同:
1. Java 中的迭代子模式
Java 有java.util.Iterator接口,对应抽象迭代器;ArrayList、LinkedList等集合类对应具体集合,用iterator()方法返回具体迭代器。
import java.util.ArrayList;
import java.util.Iterator;
public class Main {
public static void main(String[] args) {
ArrayList<Integer> list = new ArrayList<>();
list.add(10);
list.add(20);
// 获取迭代器
Iterator<Integer> it = list.iterator();
// 遍历
while (it.hasNext()) {
System.out.println(it.next());
}
}
}
2. Python 中的迭代子模式
Python 没有显式的Iterator接口,但通过__iter__()和__next__()方法实现迭代器。for...in循环本质上就是调用迭代器的__next__()方法,直到抛出StopIteration异常。
# 自定义集合
class MyList:
def __init__(self):
self.data = [1,2,3,4]
# __iter__() = createIterator(),返回迭代器
def __iter__(self):
return MyIterator(self.data)
# 自定义迭代器
class MyIterator:
def __init__(self, data):
self.data = data
self.index = 0
# __next__() = next()
def __next__(self):
if self.index >= len(self.data):
raise StopIteration
result = self.data[self.index]
self.index += 1
return result
# 遍历(for...in自动调用迭代器)
my_list = MyList()
for num in my_list:
print(num)
九、结语:迭代子模式的核心不是 “写迭代器”,而是 “解耦”
看到这里,你应该明白:迭代子模式的核心不是 “写一个迭代器类”,而是 “把集合的存储和遍历拆分开”,用统一的接口屏蔽不同集合的差异,让代码更灵活、更易维护。
咱们总结一下这篇文章的重点:
- 迭代子模式解决的痛点:集合结构变化导致遍历代码修改、多遍历方式重复写代码、暴露集合内部结构。
- 4 个核心角色:抽象迭代器(定规则)、具体迭代器(做遍历)、抽象集合(造迭代器)、具体集合(存数据)。
- C++ 实战:数组迭代器、链表迭代器、过滤迭代器,以及 STL 中的迭代器实现。
- 适用场景:多集合类型、多遍历方式、需隐藏内部结构时用,简单遍历不用。
下次你再遇到 “遍历集合” 的需求,别着急手写循环,先想想迭代子模式 —— 说不定能让你的代码优雅不少。如果这篇文章对你有帮助,欢迎点赞收藏,也可以在评论区分享你用迭代子模式的经历~



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









