




 美团视觉智能部推出了YOLOv6,一个针对工业应用的单阶段目标检测框架,侧重硬件友好性和效率。YOLOv6在Backbone中采用RepVGG结构,Neck部分使用Rep-PAN,检测头简化为SimplifiedDecoupledHead,并采用Anchor-free无锚范式、SimOTA标签分配策略和SIoU损失函数。实验结果显示,YOLOv6在精度和速度上均有显著提升,特别是在与YOLOv5的对比中,YOLOv6-nano、YOLOv6-tiny和YOLOv6-s在精度和速度上均有优势。
美团视觉智能部推出了YOLOv6,一个针对工业应用的单阶段目标检测框架,侧重硬件友好性和效率。YOLOv6在Backbone中采用RepVGG结构,Neck部分使用Rep-PAN,检测头简化为SimplifiedDecoupledHead,并采用Anchor-free无锚范式、SimOTA标签分配策略和SIoU损失函数。实验结果显示,YOLOv6在精度和速度上均有显著提升,特别是在与YOLOv5的对比中,YOLOv6-nano、YOLOv6-tiny和YOLOv6-s在精度和速度上均有优势。
浅读一下美团视觉智能部提出的YOLOV6:专用于工业应用的单阶段目标检测框架
目前该项目已经开源:https://github.com/meituan/YOLOv6,但是没有看到相应的论文,然后去找了一下。

虽然没有更详细的论文介绍,不过人家代码已经开源了,还是值得看看的。
一、相关知识:
1.1、FP16和FP32?
当前Pytorch的默认存储数据类型是整数INT64(8字节),浮点数FP32(4字节),PyTorch Tensor的默认类型为单精度浮点数FP32。随着模型越来越大,加速训练模型的需求就产生了。
在深度学习模型中使用FP32主要存在几个问题:
- 模型尺寸大,训练的时候对显卡的显存要求高;
- 模型训练速度慢;
- 模型推理速度慢。
解决方案就是使用低精度计算对模型进行优化。
与单精度浮点数float32(32bit,4个字节)相比,半精度浮点数float16仅有16bit,2个字节组成。使用FP16可以解决或者缓解上面FP32的两个问题:显存占用更少:通用的模型FP16占用的内存只需原来的一半,训练的时候可以使用更大的batchsize,计算速度更快。
一般采用混合精度(AMP, Automatic mixed precision),用半精度可能对acc的影响较大,Pytorch原生支持自动混合精度训练(torch.cuda.amp),AMP 训练能在 Tensor Core GPU (Tensor Core是一种矩阵乘累加的计算单元,每个Tensor Core每个时钟执行64个浮点混合精度操作,FP16矩阵相乘和FP32累加)上实现更高的性能并节省多达 50% 的内存,主要节省的还是内存开销问题,在实际测试中,训练时间并没有节省。低精度计算也是未来深度学习的一个重要趋势。
二、改进
2.1 Hardware-friendly Backbone
之前的YOLO系列模型主干都是采用的CSPNet,采用了多分支的方式和残差结构,如下图中yolox的主干:
对于 GPU 等硬件来说,这种结构会一定程度上增加延时,同时减小内存带宽利用率。图 2 为计算机体系结构领域中的 Roofline Model介绍图,显示了硬件中计算能力和内存带宽之间的关联关系。
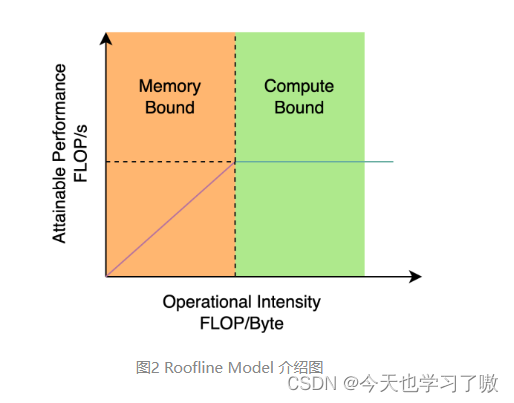
基于硬件感知神经网络设计的思想,综合考虑硬件计算能力、内存带宽、编译优化特性、网络表征能力等。
2.1.1 RepVGG style 结构:
RepVGG为每一个3×3的卷积添加平行了一个1x1的卷积分支和恒等映射的分支。这种结构就构成了构成一个RepVGG Block。
该结构在训练时具有多分支拓扑,而在实际部署时可以等效融合为单个 3x3 卷积的一种可重参数化的结构(融合过程如下图 3 所示)。通过融合成的 3x3 卷积结构,可以有效利用计算密集型硬件计算能力(比如 GPU),同时也可获得 GPU/CPU 上已经高度优化的 NVIDIA cuDNN 和 Intel MKL 编译框架的帮助。
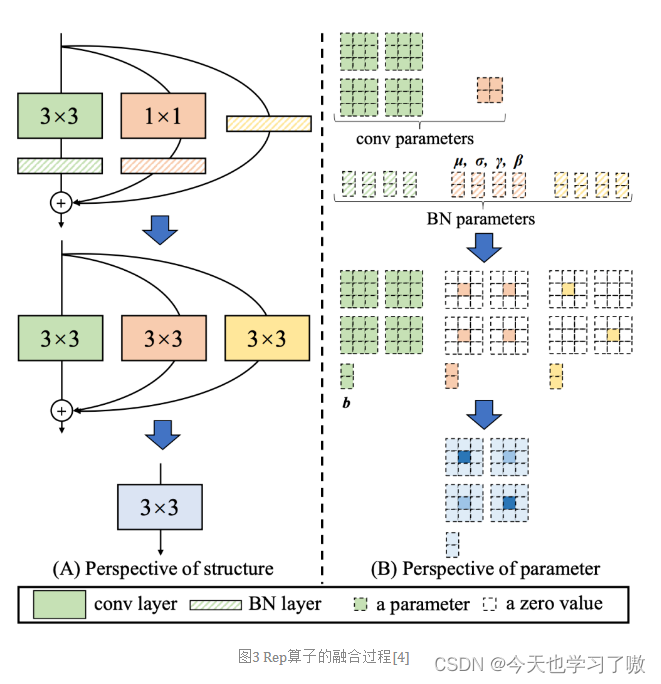
具体结构为:
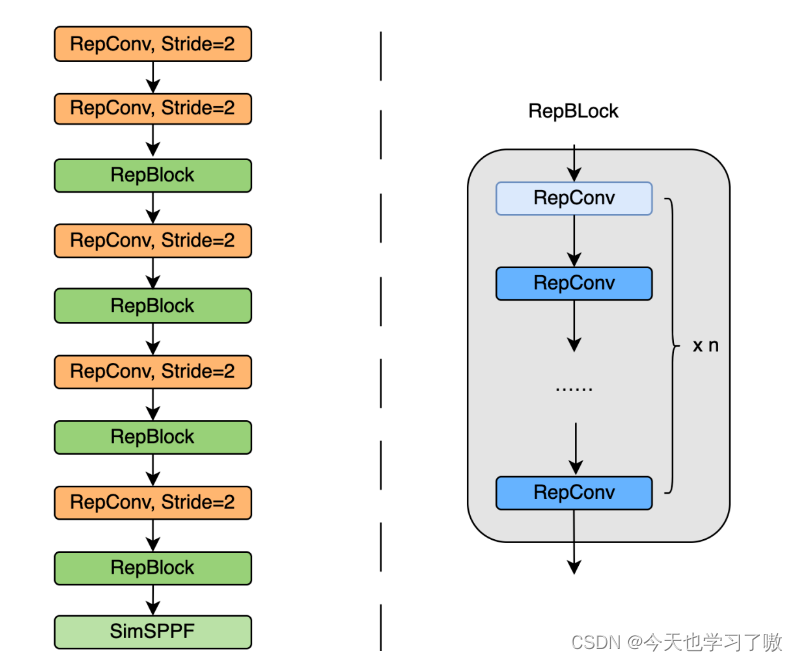
将 Backbone 中 stride=2 的普通 Conv 层替换成了 stride=2 的 RepConv层。同时,将原始的 CSP-Block 都重新设计为 RepBlock,其中 RepBlock 的第一个 RepConv 会做 channel 维度的变换和对齐。
另外,原始的 SPPF 优化设计为更加高效的 SimSPPF。
2.1.2 SPP、SPPF、SimSPPF的区别
(1)SPP的应用背景:
在卷积神经网络中我们经常看到固定输入的设计,但是如果我们输入的不能是固定尺寸的该怎么办呢?
通常来说,有以下几种方法:
- 对输入进行resize操作,让他们统统变成你设计的层的输入规格那样。但是这样过于暴力直接,可能会丢失很多信息或者多出很多不该有的信息(图片变形等),影响最终的结果;
- 替换网络中的全连接层,对最后的卷积层使用global average pooling,全局平均池化只和通道数有关,而与特征图大小没有关系;
- SPP结构:又称空间金字塔池化,能够将能将任意大小的特征图转换成固定大小的特征向量。
(2)SPP:
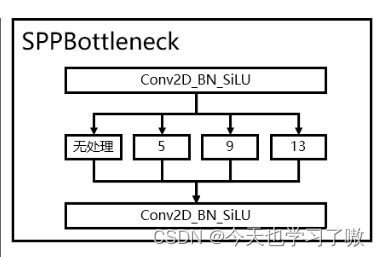
SPP的处理过程:
输入层:首先我们现在有一张任意大小的图片,其大小为w * h。
输出层:276个神经元 – 即我们希望提取到276个特征。
分别对 1 * 1分块,5* 5分块、9 * 9分块、13 * 13分块子图里分别取每一个框内的最大值,这一步就是作最大池化,这样最后提取出来的特征值(即取出来的最大值)一共有1 * 1 + 5 * 5 + 9 * 9+13 * 13 = 276个。得出的特征再concat在一起。
(3)SPPF:

SPPF结构是将输入串行通过多个5x5大小的MaxPool层,这里需要注意的是串行两个5x5大小的MaxPool层是和一个9x9大小的MaxPool层计算结果是一样的,串行三个5x5大小的MaxPool层是和一个13x13大小的MaxPool层计算结果是一样的。
SPPF结构与SPP结构作用一样,但SPPF结构效率更高、速度更快
(4)SimSPPF:
官方没有细说,直接看代码吧:
class SimSPPF(nn.Module):
'''Simplified SPPF with ReLU activation'''
def __init__(self, in_channels, out_channels, kernel_size=5):
super().__init__()
c_ = in_channels // 2 # hidden channels
self.cv1 = SimConv(in_channels, c_, 1, 1)
self.cv2 = SimConv(c_ * 4, out_channels, 1, 1)
self.m = nn.MaxPool2d(kernel_size=kernel_size, stride=1, padding=kernel_size // 2)
def forward(self, x):
x = self.cv1(x)
with warnings.catch_warnings():
warnings.simplefilter('ignore')
y1 = self.m(x)
y2 = self.m(y1)
return self.cv2(torch.cat([x, y1, y2, self.m(y2)], 1))
class SimConv(nn.Module):
'''Normal Conv with ReLU activation'''
def __init__(self, in_channels, out_channels, kernel_size, stride, groups=1, bias=False):
super().__init__()
padding = kernel_size // 2
self.conv = nn.Conv2d(
in_channels,
out_channels,
kernel_size=kernel_size,
stride=stride,
padding=padding,
groups=groups,
bias=bias,
)
self.bn = nn.BatchNorm2d(out_channels)
self.act = nn.ReLU()
def forward(self, x):
return self.act(self.bn(self.conv(x)))
def forward_fuse(self, x):
return self.act(self.conv(x))
和SPPF基本上一样。
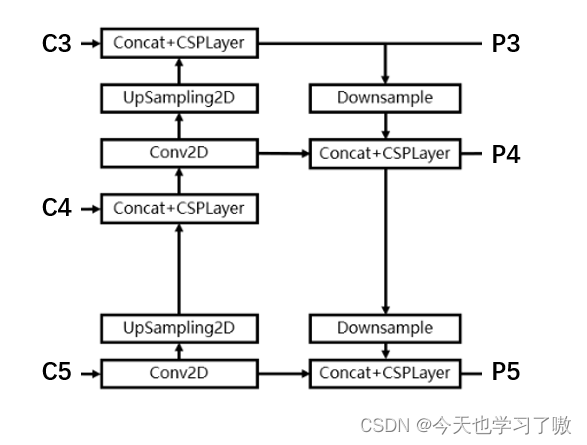
2.2 Rep-PAN Neck
在 Neck 设计方面,为了让其在硬件上推理更加高效,以达到更好的精度与速度的平衡,基于硬件感知神经网络设计思想,设计了一个更有效的特征融合网络结构:Rep-PAN。
Rep-PAN 基于 PAN拓扑方式,用 RepBlock 替换了 YOLOv5 中使用的 CSP-Block,同时对整体 Neck 中的算子进行了调整,目的是在硬件上达到高效推理的同时,保持较好的多尺度特征融合能力。
Rep-PAN结构:

对比yolox中的Neck:
2.3 Simplified Decoupled Head
在 YOLOv6 中,采用了解耦检测头(Decoupled Head)结构,并对其进行了精简设计。
原始 YOLOv5 的检测头是通过分类和回归分支融合共享的方式来实现的,而 YOLOX 的检测头则是将分类和回归分支进行解耦,同时新增了两个额外的 3x3 的卷积层,虽然提升了检测精度,但一定程度上增加了网络延时。
因此,对解耦头进行了精简设计,同时综合考虑到相关算子表征能力和硬件上计算开销这两者的平衡,采用 Hybrid Channels 策略重新设计了一个更高效的解耦头结构,在维持精度的同时降低了延时,缓解了解耦头中 3x3 卷积带来的额外延时开销。通过在 nano 尺寸模型上进行消融实验,对比相同通道数的解耦头结构,精度提升 0.2% AP 的同时,速度提升6.8%。

2.4 训练策略
2.4.1 Anchor-free无锚范式
由于 Anchor-based检测器需要在训练之前进行聚类分析以确定最佳 Anchor 集合,这会一定程度提高检测器的复杂度;同时,在一些边缘端的应用中,需要在硬件之间搬运大量检测结果的步骤,也会带来额外的延时。而 Anchor-free 无锚范式因其泛化能力强,解码逻辑更简单,在近几年中应用比较广泛。经过对 Anchor-free 的实验调研,我们发现,相较于Anchor-based 检测器的复杂度而带来的额外延时,Anchor-free 检测器在速度上有51%的提升。
2.4.2 SimOTA 标签分配策略
YOLOv5 的标签分配策略是基于 Shape 匹配,并通过跨网格匹配策略增加正样本数量,从而使得网络快速收敛,但是该方法属于静态分配方法,并不会随着网络训练的过程而调整。
为了获得更多高质量的正样本,YOLOv6 同样沿用了 YOLOX的SimOTA算法动态分配正样本,进一步提高检测精度。
2.4.3 SIoU 边界框回归损失
SIoU 边界框回归损失函数是2022年5月份提出的:SIoU Loss: More Powerful Learning for Bounding Box Regression
YOLOv6 采用了 SIoU 边界框回归损失函数来监督网络的学习。
目标检测网络的训练一般需要至少定义两个损失函数:分类损失和边界框回归损失,而损失函数的定义往往对检测精度以及训练速度产生较大的影响。
近年来,常用的边界框回归损失包括IoU、GIoU、CIoU、DIoU loss等等,这些损失函数通过考虑预测框与目标框之前的重叠程度、中心点距离、纵横比等因素来衡量两者之间的差距,从而指导网络最小化损失以提升回归精度,但是这些方法都没有考虑到预测框与目标框之间方向的匹配性。SIoU 损失函数通过引入了所需回归之间的向量角度,重新定义了距离损失,有效降低了回归的自由度,加快网络收敛,进一步提升了回归精度。
通过在 YOLOv6s 上采用 SIoU loss 进行实验,对比 CIoU loss,平均检测精度提升 0.3% AP。
三、实验结果
3.1 YOLOv6-nano 消融实验

3.2 YOLOv6与主流的YOLO系列模型对比
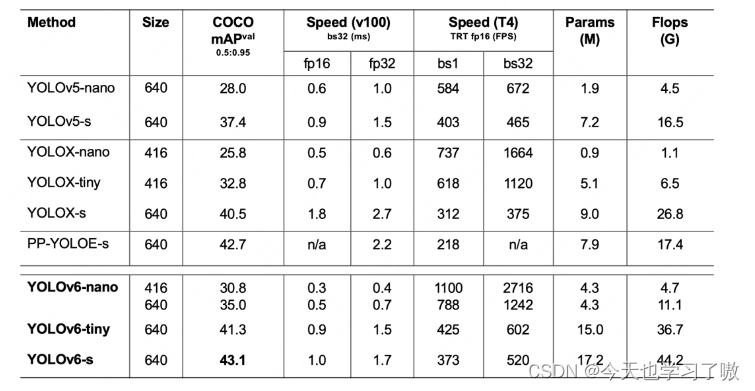
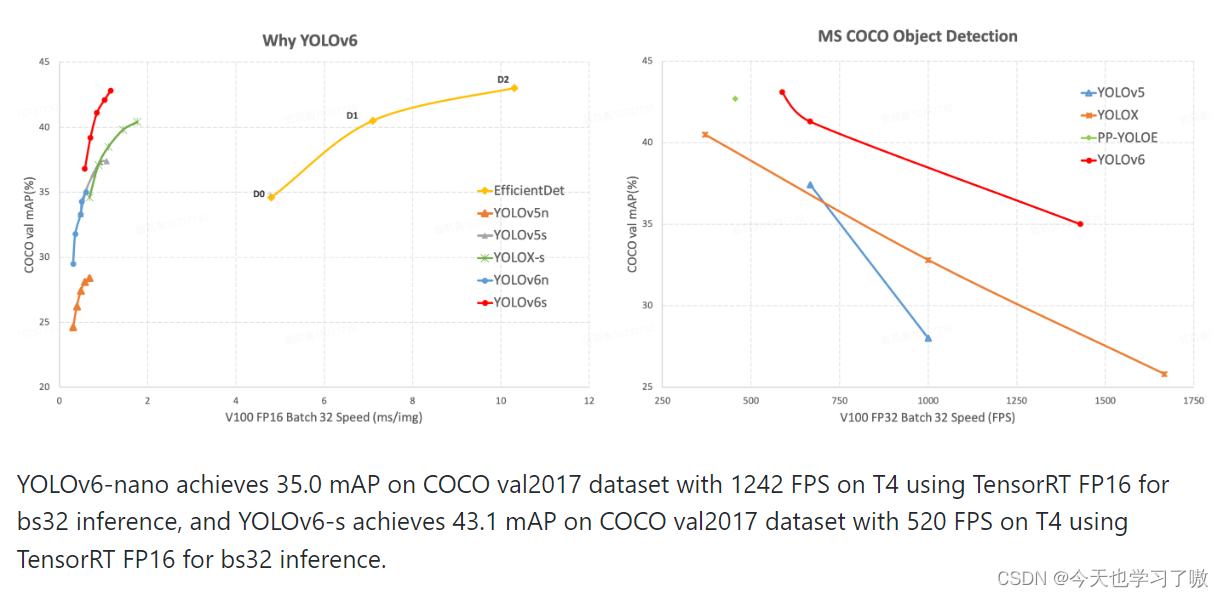
- YOLOv6-nano 在 COCO val 上 取得了 35.0% AP 的精度,同时在 T4 上使用 TRT FP16 batchsize=32 进行推理,可达到 1242FPS 的性能,相较于 YOLOv5-nano 精度提升 7% AP,速度提升 85%。
- YOLOv6-tiny 在 COCO val 上 取得了 41.3% AP 的精度, 同时在 T4 上使用 TRT FP16 batchsize=32 进行推理,可达到 602FPS 的性能,相较于 YOLOv5-s 精度提升 3.9% AP,速度提升 29.4%。
- YOLOv6-s 在 COCO val 上 取得了 43.1% AP 的精度, 同时在 T4 上使用 TRT FP16 batchsize=32 进行推理,可达到 520FPS 的性能,相较于 YOLOX-s 精度提升 2.6% AP,速度提升 38.6%;相较于 PP-YOLOE-s 精度提升 0.4% AP的条件下,在T4上使用 TRT FP16 进行单 batch 推理,速度提升 71.3%。
3.3 实验测试





















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









