






一、配置文件
apiVersion: apps/v1
kind: DaemonSet
metadata:
name: fluentd
spec:
selector:
matchLabels:
app: logging
template:
metadata:
labels:
app: logging
id: fluentd
name: fluentd
spec:
containers:
- name: fluentd-es
image: agilestacks/fluentd-elasticsearch:v1.3.0
imagePullPolicy: IfNotPresent
env:
- name: FLUENTD_ARGS
value: -qq
volumeMounts:
- name: containers
mountPath: /var/lib/docker/containers
- name: varlog
mountPath: /varlog
volumes:
- hostPath:
path: /var/lib/docker/containers
name: containers
- hostPath:
path: /var/log
name: varlog
# 通过这种方式创建的daemonset,会在每个非master节点都创建pod
# 添加标签
[root@k8s-master daemonset]# kubectl label no k8s-node1 type=microservices
node/k8s-node1 labeled查看标签,会发现k8s-node1多出一个标签

# 查看当前的部署情况
[root@k8s-master daemonset]# kubectl get po -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
dns-test 1/1 Running 1 (23h ago) 2d2h 10.244.169.161 k8s-node2 <none> <none>
fluentd-c8gpx 1/1 Running 0 23h 10.244.36.98 k8s-node1 <none> <none>
fluentd-nps8w 1/1 Running 0 23h 10.244.169.163 k8s-node2 <none> <none>
# 在 k8s-node1 和 k8s-node2 都有部署二、指定节点
DaemonSet 会忽略 Node 的 unschedulable 状态,有两种方式来指定 Pod 只运行在指定的 Node 节点上:
nodeSelector:只调度到匹配指定 label 的 Node 上
nodeAffinity:功能更丰富的 Node 选择器,比如支持集合操作
podAffinity:调度到满足条件的 Pod 所在的 Node 上先为 Node 打上标签
kubectl label nodes k8s-node1 svc_type=microsvc
然后再 daemonset 配置中设置 nodeSelector
spec:
template:
spec:
nodeSelector:
svc_type: microsvc
# 重新编辑配置文件
[root@k8s-master daemonset]# kubectl edit ds fluentd
apiVersion: apps/v1
kind: DaemonSet
metadata:
annotations:
deprecated.daemonset.template.generation: "1"
creationTimestamp: "2025-01-06T17:13:22Z"
generation: 1
name: fluentd
namespace: default
resourceVersion: "301917"
uid: 75f82c83-c526-4bba-8ce9-983343b1d30d
spec:
revisionHistoryLimit: 10
selector:
matchLabels:
app: logging
template:
metadata:
creationTimestamp: null
labels:
app: logging
id: fluentd
name: fluentd
spec:
nodeSelector:
type: microservices
containers:
- env:
- name: FLUENTD_ARGS
value: -qq
image: agilestacks/fluentd-elasticsearch:v1.3.0
imagePullPolicy: IfNotPresent
name: fluentd-es
resources: {}
terminationMessagePath: /dev/termination-log
terminationMessagePolicy: File
volumeMounts:
- mountPath: /var/lib/docker/containers
name: containers
- mountPath: /varlog
name: varlog
dnsPolicy: ClusterFirst
restartPolicy: Always
schedulerName: default-scheduler
securityContext: {}
terminationGracePeriodSeconds: 30
volumes:
- hostPath:
path: /var/lib/docker/containers
type: ""
name: containers
- hostPath:
path: /var/log
type: ""
name: varlog
updateStrategy:
rollingUpdate:
maxSurge: 0
maxUnavailable: 1
type: RollingUpdate
# 再次查看ds
[root@k8s-master daemonset]# kubectl get ds
NAME DESIRED CURRENT READY UP-TO-DATE AVAILABLE NODE SELECTOR AGE
fluentd 1 1 1 1 1 type=microservices 23h
# 由之前的2个,变成现在的1个
# 查看所部署的机器
[root@k8s-master daemonset]# kubectl get po -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
dns-test 1/1 Running 1 (23h ago) 2d2h 10.244.169.161 k8s-node2 <none> <none>
fluentd-4w66f 1/1 Running 0 94s 10.244.36.99 k8s-node1 <none> <none>
# 可以看到部署到了k8s-node1机器上
# 此时再给k8s-node2节点加同样的标签
[root@k8s-master daemonset]# kubectl label no k8s-node2 type=microservices
node/k8s-node2 labeled
# 立刻查看pod的部署情况
[root@k8s-master daemonset]# kubectl get po -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
dns-test 1/1 Running 1 (23h ago) 2d2h 10.244.169.161 k8s-node2 <none> <none>
fluentd-4w66f 1/1 Running 0 3m37s 10.244.36.99 k8s-node1 <none> <none>
fluentd-6wk2g 1/1 Running 0 4s 10.244.169.164 k8s-node2 <none> <none>
# 可以看到,k8s-node2也迅速被部署上了三、滚动更新
不建议使用 RollingUpdate,建议使用 OnDelete 模式,这样避免频繁更新 ds,注意daemonSet没有扩容缩容的概念,它是根据匹配的标签来决定在那个机器上部署应用,没有replicas属性。
四、Horizontal Pod Autoscaler(HPA)
HPA能够根据观察到的CPU利用率(或在支持自定义指标的情况下,根据其他一些应用程序提供的指标)自动伸缩replication controller、deployment、replica set、stateful set中的Pod数量。这使得应用能够根据实际负载动态扩缩容,从而提高资源利用率和系统可用性。
(1)工作原理
- HPA实现为一个控制循环,其周期由
--horizontal-pod-autoscaler-sync-period选项指定(默认15秒)。在每个周期内,controller manager都会根据每个HorizontalPodAutoscaler定义的指定指标去查询资源利用率。 - controller manager从资源指标API(针对每个Pod资源指标)或自定义指标API(针对所有其他指标)获取指标。对于每个Pod资源指标(如CPU),控制器会从资源指标API中获取相应的指标。
- 如果设置了目标利用率值,则控制器计算利用率值作为容器上等效的资源请求百分比;如果设置了目标原始值,则直接使用原始指标值。然后,控制器将所有目标容器的利用率或原始值(取决于指定的目标类型)取平均值,并产生一个用于缩放所需副本数量的比率。
- HPA使用特定的算法来计算期望的副本数量(desiredReplicas),算法公式为:
desiredReplicas = ceil[currentReplicas * (currentMetricValue / desiredMetricValue)]。即(当前指标值/期望指标值)×当前副本数,结果再向上取整。
(2)组成部分
HPA对象主要包括以下字段:
- 元数据:包含HPA的名称、命名空间、标签等。
- scaleTargetRef:指向需要自动扩展的目标资源,通常是Deployment。
- minReplicas:定义最小副本数,HPA不会缩减Pods少于此值。
- maxReplicas:定义最大副本数,HPA不会扩展Pods超过此值。
- metrics:定义用于扩展的指标,通常包括CPU、内存或自定义指标。
- 状态信息:包含当前Pods的数量、目标指标的实际值等。
(3)应用场景
- 流量波动的应用:在流量波动较大的应用中,HPA可以根据需求自动扩展或缩减Pods,确保服务稳定。
- 微服务架构:HPA非常适合微服务架构,可以为不同服务设置不同的扩展策略。
- 高可用性应用:对于需要高可用性的应用,HPA可以确保在高负载时提供足够的处理能力,减少故障和延迟。
(4)使用示例
以下是一个HPA的YAML示例,它根据CPU使用率自动扩展名为my-deployment的Deployment:
apiVersion: autoscaling/v2beta2
kind: HorizontalPodAutoscaler
metadata:
name: my-hpa
namespace: my-namespace
spec:
scaleTargetRef:
apiVersion: apps/v1
kind: Deployment
name: my-deployment
minReplicas: 1
maxReplicas: 10
metrics:
- type: Resource
resource:
name: cpu
target:
type: Utilization
averageUtilization: 80(5)HPA 自动扩/缩容
1、cpu、内存指标监控
实现 cpu 或内存的监控,首先有个前提条件是该对象必须配置了 resources.requests.cpu 或 resources.requests.memory 才可以,可以配置当 cpu/memory 达到上述配置的百分比后进行扩容或缩容
创建一个 HPA:
先准备一个好一个有做资源限制的 deployment
执行命令 kubectl autoscale deploy nginx-deploy --cpu-percent=20 --min=2 --max=5
通过 kubectl get hpa 可以获取 HPA 信息
测试:找到对应服务的 service,编写循环测试脚本提升内存与 cpu 负载
while true; do wget -q -O- http://<ip:port> > /dev/null ; done
可以通过多台机器执行上述命令,增加负载,当超过负载后可以查看 pods 的扩容情况 kubectl get pods
查看 pods 资源使用情况
kubectl top pods
扩容测试完成后,再关闭循环执行的指令,让 cpu 占用率降下来,然后过 5 分钟后查看自动缩容情况
# 编辑配置文件
[root@k8s-master deployments]# vim nginx-deploy.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
labels:
app: nginx-deploy
name: nginx-deploy
namespace: default
spec:
replicas: 1 # 指定了Pod的副本数量
revisionHistoryLimit: 10 # 指定了保留的旧ReplicaSet的数量,这里是10。当进行滚动更新时,旧的ReplicaSet会被保留以便回滚
selector: # 用于选择哪些Pod由这个Deployment管理
matchLabels:
app: nginx-deploy
strategy:
rollingUpdate: # 滚动更新的配置
maxSurge: 25% # 定义了滚动更新过程中可以超过期望副本数的最大Pod数,这里是25%。这意味着在更新过程中,最多可以有原始副本数的125%的Pod在运行
maxUnavailable: 25% # 定义了滚动更新过程中允许的最大不可用Pod数
type: RollingUpdate # 指定了更新策略的类型,这里是RollingUpdate
template: # 定义了Pod的模板
metadata: # Pod模板的元数据
labels: # 为Pod模板定义了标签,这里有一个标签app: nginx-deploy
app: nginx-deploy
spec: # Pod模板的规格
containers: # 定义了Pod中的容器列表
- image: nginx
imagePullPolicy: IfNotPresent
name: nginx
resources:
limits:
cpu: 200m
memory: 128Mi
requests:
cpu: 100m
memory: 128Mi:
restartPolicy: Always
terminationGracePeriodSeconds: 30
[root@k8s-master deployments]# kubectl create -f nginx-deploy.yaml
[root@k8s-master deployments]# kubectl autoscale deploy nginx-deploy --cpu-percent=20 --min=2 --max=5
horizontalpodautoscaler.autoscaling/nginx-deploy autoscaled
(6)开启指标服务
# 下载 metrics-server 组件配置文件
wget https://github.com/kubernetes-sigs/metrics-server/releases/latest/download/components.yaml -O metrics-server-components.yaml
# 如果下载不了,可以先下载之后,再上转到虚拟机中
# 我使用的方法是,临时开个代理,修改/etc/profile文件,文件最后添加如下配置
http_proxy=http://192.168.1.5:7890
https_proxy=http://192.168.1.5:7890
export http_proxy
export https_proxy
# 然后保存,执行source /etc/profile
至于地址为什么是192.168.1.5:7890,这是通过查看本机所开的代理的地址(即window电脑的ip地址和端口)
# 修改镜像地址为国内的地址
sed -i 's/k8s.gcr.io\/metrics-server/registry.cn-hangzhou.aliyuncs.com\/google_containers/g' metrics-server-components.yaml
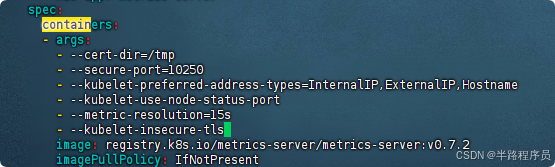
# 修改容器的 tls 配置,不验证 tls,在 containers 的 args 参数中增加 --kubelet-insecure-tls 参数,参考下面的截图内容
# 安装组件
[root@k8s-master components]# kubectl apply -f metrics-server-components.yaml
serviceaccount/metrics-server created
clusterrole.rbac.authorization.k8s.io/system:aggregated-metrics-reader created
clusterrole.rbac.authorization.k8s.io/system:metrics-server created
rolebinding.rbac.authorization.k8s.io/metrics-server-auth-reader created
clusterrolebinding.rbac.authorization.k8s.io/metrics-server:system:auth-delegator created
clusterrolebinding.rbac.authorization.k8s.io/system:metrics-server created
service/metrics-server created
deployment.apps/metrics-server created
apiservice.apiregistration.k8s.io/v1beta1.metrics.k8s.io created
# 查看 pod 状态
[root@k8s-master components]# kubectl get po --all-namespaces | grep metrics
kube-system metrics-server-596474b58-khrms 0/1 ContainerCreating 0 61s
# 查看pods状态
[root@k8s-master deployments]# kubectl top pods
NAME CPU(cores) MEMORY(bytes)
nginx-deploy-86c5776ccd-grc2c 0m 3Mi
nginx-deploy-86c5776ccd-kplgd 0m 3Mi
# 查看ip和标签
[root@k8s-master deployments]# kubectl get po -o wide --show-labels
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES LABELS
nginx-deploy-86c5776ccd-grc2c 1/1 Running 0 19m 10.109.131.1 k8s-node2 <none> <none> app=nginx-deploy,pod-template-hash=86c5776ccd
nginx-deploy-86c5776ccd-kplgd 1/1 Running 0 19m 10.111.156.65 k8s-node1 <none> <none> app=nginx-deploy,pod-template-hash=86c5776ccd
# 可以看到都有一个标签为app=nginx-deploy
# 创建一个service
[root@k8s-master deployments]# vim nginx-svc.yaml
apiVersion: v1
kind: Service
metadata:
name: nginx-svc
labels:
app: nginx
spec:
selector:
app: nginx-deploy
ports:
- port: 80
targetPort: 80
name: web
type: NodePort
[root@k8s-master deployments]# kubectl create -f nginx-svc.yaml
service/nginx-svc created
# 查看创建的service
[root@k8s-master deployments]# kubectl get svc
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
kubernetes ClusterIP 10.96.0.1 <none> 443/TCP 68m
nginx-svc NodePort 10.98.220.155 <none> 80:31662/TCP 21s
# 通过两种方式,可以访问nginx
# 上面的80:31662两个端口:80是指的svc的端口,是和10.98.220.155对应的,31662是指宿主机的端口,也就是虚拟机的端口
[root@k8s-master deployments]# curl 10.98.220.155
[root@k8s-master deployments]# curl 192.168.129.136:31662
# 在k8s-node1节点,创建死循环,进行访问测试
[root@192 yum.repos.d]# while true; do wget -q -O- http://<10.98.220.155> > /dev/null ; done
# 在master节点,查看详细信息
[root@k8s-master deployments]# kubectl get hpa
NAME REFERENCE TARGETS MINPODS MAXPODS REPLICAS AGE
nginx-deploy Deployment/nginx-deploy 0%/20% 2 5 2 28m
[root@k8s-master deployments]# kubectl get hpa
NAME REFERENCE TARGETS MINPODS MAXPODS REPLICAS AGE
nginx-deploy Deployment/nginx-deploy 40%/20% 2 5 5 29m
[root@k8s-master deployments]# kubectl top pods
NAME CPU(cores) MEMORY(bytes)
nginx-deploy-86c5776ccd-grc2c 0m 3Mi
nginx-deploy-86c5776ccd-kplgd 0m 3Mi
[root@k8s-master deployments]# kubectl top pods
NAME CPU(cores) MEMORY(bytes)
nginx-deploy-86c5776ccd-grc2c 19m 3Mi
nginx-deploy-86c5776ccd-kplgd 36m 3Mi
[root@k8s-master deployments]# kubectl top pods
NAME CPU(cores) MEMORY(bytes)
nginx-deploy-86c5776ccd-grc2c 50m 3Mi
nginx-deploy-86c5776ccd-kplgd 48m 3Mi
[root@k8s-master deployments]# kubectl top pods
NAME CPU(cores) MEMORY(bytes)
nginx-deploy-86c5776ccd-grc2c 22m 3Mi
nginx-deploy-86c5776ccd-jh4gl 24m 3Mi
nginx-deploy-86c5776ccd-jsjgm 26m 3Mi
nginx-deploy-86c5776ccd-kplgd 26m 3Mi
nginx-deploy-86c5776ccd-wk2nv 22m 3Mi
[root@k8s-master deployments]# kubectl get deploy
NAME READY UP-TO-DATE AVAILABLE AGE
nginx-deploy 5/5 5 5 33m
可以看到hpa的百分比慢慢增加了,并且pod节点自动完成了扩容,以应对压力的上涨,nginx-deploy也完成了自动扩容,当循环请求停止之后,pod的数量会自动缩回去
















 868
868

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









