










 本文介绍了人脸检测与对齐的多种算法,包括基于CNN的2D和3D对齐方法,如MTCNN、DCNN及PRNet等。重点讨论了这些方法如何通过级联CNN框架实现实时高效的人脸检测与对齐,并介绍了它们在网络结构、特征提取及应用方面的特点。
本文介绍了人脸检测与对齐的多种算法,包括基于CNN的2D和3D对齐方法,如MTCNN、DCNN及PRNet等。重点讨论了这些方法如何通过级联CNN框架实现实时高效的人脸检测与对齐,并介绍了它们在网络结构、特征提取及应用方面的特点。
参考,人脸pose检测算法:https://blog.youkuaiyun.com/wishchin/article/details/51554036。
人脸的Pose检测需要一个 SolvePNP 的过程,对于固定三维点集模型,找出二维点集对应的位姿。此外,在track时使用点集寻找一个最优的位姿起始,应该给出一个好的起始点。或者,人脸pose检测只需要人脸对齐,同时找到二维人脸的平面即可。
参考总结:https://www.jianshu.com/p/e4b9317a817f。MTCNN的广泛应用,提出了一种新的联合人脸检测和对齐的级联CNN框架,相对于DPM传统方法是一个更为稀疏的模型,为实时性能精心设计了轻量级的网络结构,在移动设备上也可以达到实时的效果。github:https://github.com/imistyrain/MTCNN 。MTCNN默认提供五个关键点的检测和对齐过程。三维恢复需要更多的点的对齐过程。
基于CNN的稠密2d对齐:人脸的关键点具有显著性,利用CNN方法可以提取类似角点的显著性,通过增大网络结构,可以提高特征点的提取个数,并对特征进行描述匹配,进而可应用于Align。DCNN(Deep Convolutional Network Cascade for Facial Point Detection),CVPR2013 香港中文大学汤晓欧,SunYi等人作品,首次将CNN用于人脸关键点检测。总体思想是由粗到细,实现5个人脸关键点的精确定位。网络结构分为3层:level 1、level 2、level 3。每层都包含多个独立的CNN模型,负责预测部分或全部关键点位置,在此基础上平均来得到该层最终的预测结果。
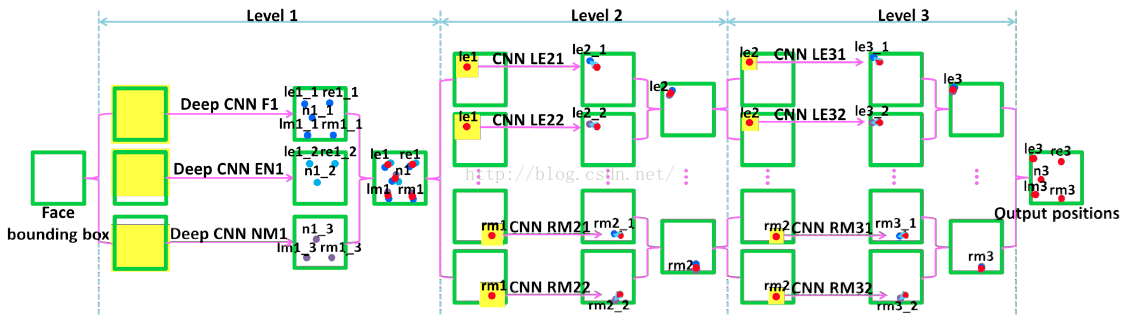 此外,可以使用更为普通的,从底向上的特征点提取CNN方法。
此外,可以使用更为普通的,从底向上的特征点提取CNN方法。
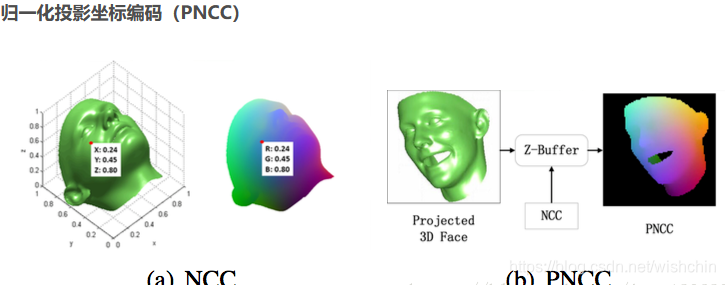
基于CNN的稠密3d对齐:Face Alignment Across Large Poses: A 3D Solution(3DDFA2015),解决大姿态下人脸特征点不可见的问题,本文提出了将3D稠密人脸模型而不是稀疏的特征点形状拟合到人脸图片上。通过加入3D信息,可以解决由3D变换导致的外观变化和自遮挡问题。2).为了解决3DDFA拟合过程,本文使用一个基于回归的级联卷积神经网络,CNN可以从大姿态变化的图片中抽取有用的信息。另外本文为了CNN更好的拟合3D人脸模型,专门设计了PNCC特征(Projected Normalized Coordinate Code)和WPDC(Weighted Parameter Distance Cost)代价函数。3).为了更好的训练3DDFA,文章会构建了一个包含成对的2D人脸形状和3D人脸模型。
 一份Pytorch版本复现的3DDFA:https://github.com/cleardusk/3DDFA。
一份Pytorch版本复现的3DDFA:https://github.com/cleardusk/3DDFA。
基于CNN的稠密重建:人脸对齐算法PRNet-(Joint 3D Face Reconstruction and Dense Alignment with Position Map Regression Network),代码链接:https://github.com/YadiraF/PRNet 。主要思想:提出了一个简单的方法,同时重建三维面部结构,并提供密集的对齐。为了实现这一目标,设计了一种称为UV位置图的二维表示方法,该方法在UV空间中记录完整人脸的3D形状,然后训练一个简单的卷积神经网络将其从单个2D图像中回归。在训练过程中,还将一个权重掩码集成到损失函数中,以提高网络的性能。本文的方法不依赖于任何先验人脸模型,可以在语义的同时重建完整的人脸几何。同时,网络本身很轻,处理图像的时间只有9.8毫秒,这比以前的作品要快得多。在多个具有挑战性的数据集上的实验表明,论文提出的方法在重建和对齐任务上都大大超过了其它最先进的方法。
主要贡献:1、 第一次以端到端的方式解决了人脸对齐和三维人脸的问题,使其一起完成,而且不受低维解空间的限制。2、 为了直接回归三维面部结构和密集排列,开发了一种新的表示方法,称为UV位置图,它记录了三维人脸的位置信息,并与UV空间上每个点的语义紧密对应。3、 为了训练,提出了一个权重掩码,它将不同的权重分配给位置图上的每个点并计算加权损失。论文展示这个设计有助于提高网络的性能。4、 最终提供了一个运行速度超过100FPS的轻量级框架直接从单个二维图像中获得三维人脸重建和对齐结果面部图像。
UVmap

主要结构:


实验结果:构建:基于TensorFlow
![]()

![]()



















 429
429

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









