




作为开源分布式事件流处理平台,Kafka分布式软件环境的安装相对比较复杂,不利于Kafka软件的入门学习和练习。所以我们这里先搭建相对比较简单的windows单机环境,让初学者快速掌握软件的基本原理和用法,后面的课程中,我们再深入学习Kafka软件在生产环境中的安装和使用。
1.2.1.1安装Java8(略)
当前Java软件开发中,主流的版本就是Java 8,而Kafka 3.X官方建议Java版本更新至Java11,但是Java8依然可用。未来Kafka 4.X版本会完全弃用Java8,不过,咱们当前学习的Kafka版本为3.6.1版本,所以使用Java8即可,无需升级。
Kafka的绝大数代码都是Scala语言编写的,而Scala语言本身就是基于Java语言开发的,并且由于Kafka内置了Scala语言包,所以Kafka是可以直接运行在JVM上的,无需安装其他软件。你能看到这个课件,相信你肯定已经安装Java8了,基本的环境变量也应该配置好了,所以此处安装过程省略。
1.2.1.2安装Kafka
- 下载软件安装包:kafka_2.12-3.6.1.tgz,下载地址:Apache Kafka
- 这里的3.6.1,是Kafka软件的版本。截至到2023年12月24日,Kafka最新版本为3.6.1。
- 2.12是对应的Scala开发语言版本。Scala2.12和Java8是兼容的,所以可以直接使用。
- tgz是一种linux系统中常见的压缩文件格式,类似与windows系统的zip和rar格式。所以Windows环境中可以直接使用压缩工具进行解压缩。

- 解压文件:kafka_2.12-3.6.1.tgz,解压目录为非系统盘的根目录,比如e:/

为了访问方便,可以将解压后的文件目录改为kafka, 更改后的文件目录结构如下:
| bin | linux系统下可执行脚本文件 |
| bin/windows | windows系统下可执行脚本文件 |
| config | 配置文件 |
| libs | 依赖类库 |
| licenses | 许可信息 |
| site-docs | 文档 |
| logs | 服务日志 |
1.2.1.3启动ZooKeeper
当前版本Kafka软件内部依然依赖ZooKeeper进行多节点协调调度,所以启动Kafka软件之前,需要先启动ZooKeeper软件。不过因为Kafka软件本身内置了ZooKeeper软件,所以无需额外安装ZooKeeper软件,直接调用脚本命令启动即可。具体操作步骤如下:
- 进入Kafka解压缩文件夹的config目录,修改zookeeper.properties配置文件
# the directory where the snapshot is stored.
# 修改dataDir配置,用于设置ZooKeeper数据存储位置,该路径如果不存在会自动创建。
dataDir=E:/kafka_2.12-3.6.1/data/zk
- 打开DOS窗口,进入e:/kafka_2.12-3.6.1/bin/windows目录

- 因为本章节演示的是Windows环境下Kafka软件的安装和使用,所以启动 ZooKeeper软件的指令为Windows环境下的bat批处理文件。调用启动指令时, 需要传递配置文件的路径
# 因为当前目录为windows,所以需要通过相对路径找到zookeeper的配置文件。
zookeeper-server-start.bat ../../config/zookeeper.properties

- 出现如下界面,ZooKeeper启动成功。
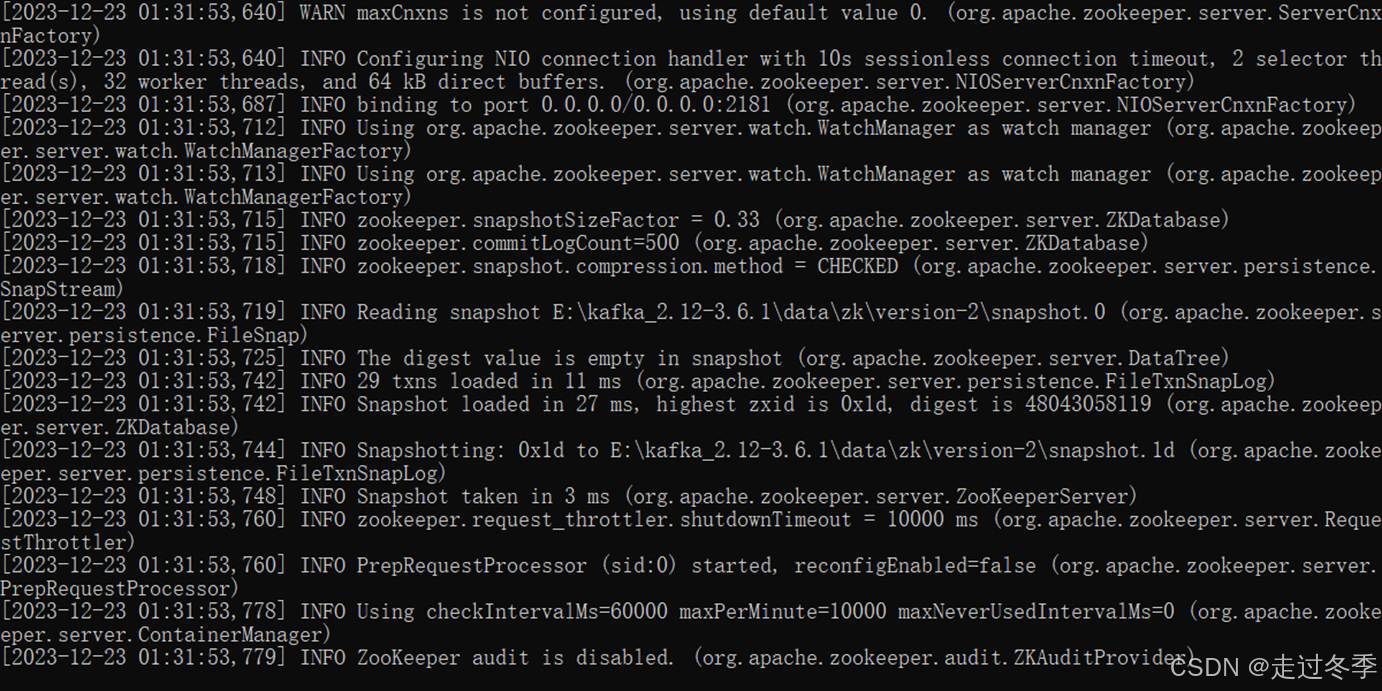
- 为了操作方便,也可以在kafka解压缩后的目录中,创建脚本文件zk.cmd。
# 调用启动命令,且同时指定配置文件。
call bin/windows/zookeeper-server-start.bat config/zookeeper.properties
1.2.1.4启动Kafka
- 进入Kafka解压缩文件夹的config目录,修改server.properties配置文件
# Listener name, hostname and port the broker will advertise to clients.
# If not set, it uses the value for "listeners".
# 客户端访问Kafka服务器时,默认连接的服务为本机的端口9092,如果想要改变,可以修改如下配置
# 此处我们不做任何改变,默认即可
#advertised.listeners=PLAINTEXT://your.host.name:9092
# A comma separated list of directories under which to store log files
# 配置Kafka数据的存放位置,如果文件目录不存在,会自动生成。
log.dirs=E:/kafka_2.12-3.6.1/data/kafka
- 打开DOS窗口,进入e:/kafka_2.12-3.6.1/bin/windows目录

- 调用启动指令,传递配置文件的路径
# 因为当前目录为windows,所以需要通过相对路径找到kafka的配置文件。
kafka-server-start.bat ../../config/server.properties

- 出现如下界面,Kafka启动成功。
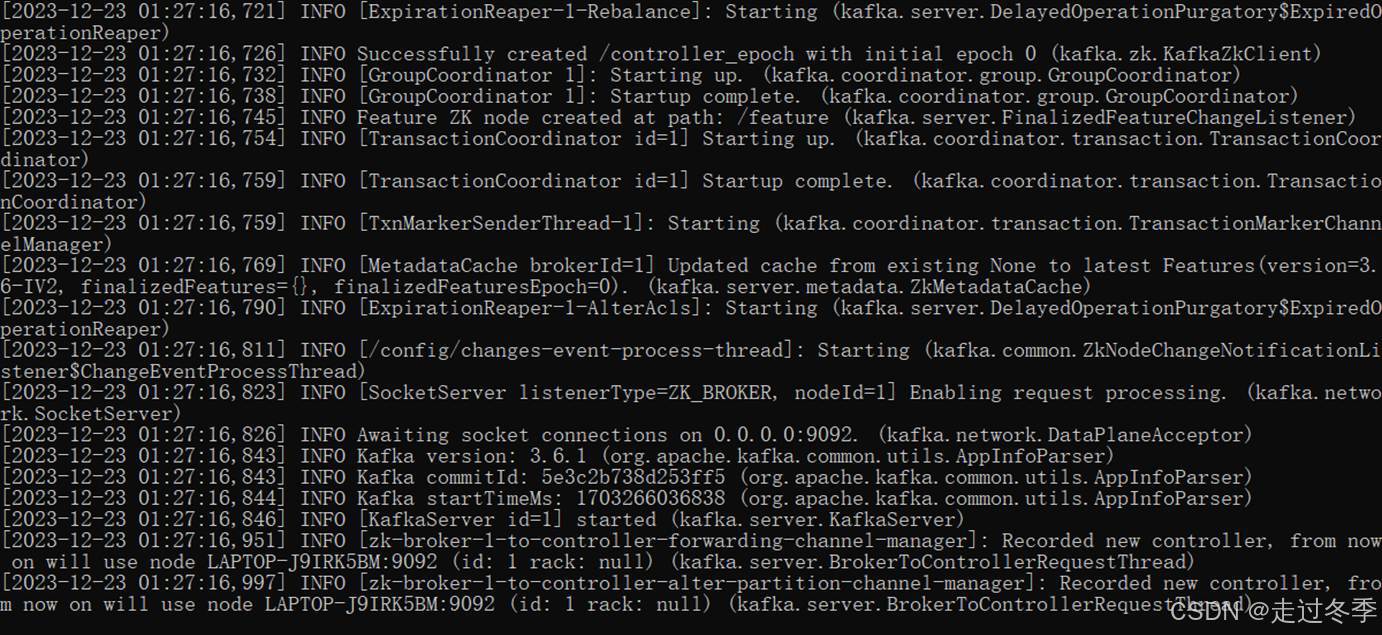
- 为了操作方便,也可以在kafka解压缩后的目录中,创建脚本文件kfk.cmd。
# 调用启动命令,且同时指定配置文件。
call bin/windows/kafka-server-start.bat config/server.properties
- DOS窗口中,输入jps指令,查看当前启动的软件进程

这里名称为QuorumPeerMain的就是ZooKeeper软件进程,名称为Kafka的就是Kafka系统进程。此时,说明Kafka已经可以正常使用了。
-
-
- 消息主题
-
在消息发布/订阅(Publish/Subscribe)模型中,为了可以让消费者对感兴趣的消息进行消费,而不是对所有的数据进行消费,包括那些不感兴趣的消息,所以定义了主题(Topic)的概念,也就是说将不同的消息进行分类,分成不同的主题(Topic),然后消息生产者在生成消息时,就会向指定的主题(Topic)中发送。而消息消费者也可以订阅自己感兴趣的主题(Topic)并从中获取消息。
有很多种方式都可以操作Kafka消息中的主题(Topic):命令行、第三方工具、Java API、自动创建。而对于初学者来讲,掌握基本的命令行操作是必要的。所以接下来,我们采用命令行进行操作。
1.2.2.1创建主题
- 启动ZooKeeper,Kafka服务进程(略)
- 打开DOS窗口,进入e:/kafka_2.12-3.6.1/bin/windows目录

- DOS窗口输入指令,创建主题
# Kafka是通过kafka-topics.bat指令文件进行消息主题操作的。其中包含了对主题的查询,创建,删除等功能。
# 调用指令创建主题时,需要传递多个参数,而且参数的前缀为两个横线。因为参数比较多,为了演示方便,这里我们只说明必须传递的参数,其他参数后面课程中会进行讲解
# --bootstrap-server : 把当前的DOS窗口当成Kafka的客户端,那么进行操作前,就需要连接服务器,这里的参数就表示服务器的连接方式,因为我们在本机启动Kafka服务进程,且Kafka默认端口为9092,所以此处,后面接的参数值为localhost:9092,用空格隔开
# --create : 表示对主题的创建操作,是个操作参数,后面无需增加参数值
# --topic : 主题的名称,后面接的参数值一般就是见名知意的字符串名称,类似于java中的字符串类型标识符名称,当然也可以使用数字,只不过最后还是当成数字字符串使用。
# 指令
kafka-topics.bat --bootstrap-server localhost:9092 --create --topic test

1.2.2.2查询主题
- DOS窗口输入指令,查看所有主题
# Kafka是通过kafka-topics.bat文件进行消息主题操作的。其中包含了对主题的查询,创建,删除等功能。
# --bootstrap-server : 把当前的DOS窗口当成Kafka的客户端,那么进行操作前,就需要连接服务器,这里的参数就表示服务器的连接方式,因为我们在本机启动Kafka服务进程,且Kafka默认端口为9092,所以此处,后面接的参数值为localhost:9092,用空格隔开
# --list : 表示对所有主题的查询操作,是个操作参数,后面无需增加参数值
# 指令
kafka-topics.bat --bootstrap-server localhost:9092 --list

- DOS窗口输入指令,查看指定主题信息
# --bootstrap-server : 把当前的DOS窗口当成Kafka的客户端,那么进行操作前,就需要连接服务器,这里的参数就表示服务器的连接方式,因为我们在本机启动Kafka服务进程,且Kafka默认端口为9092,所以此处,后面接的参数值为localhost:9092,用空格隔开
# --describe : 查看主题的详细信息
# --topic : 查询的主题名称
# 指令
kafka-topics.bat --bootstrap-server localhost:9092 --describe --topic test

1.2.2.3修改主题
创建主题后,可能需要对某些参数进行修改,那么就需要使用指令进行操作。
- DOS窗口输入指令,修改指定主题的参数
# Kafka是通过kafka-topics.bat文件进行消息主题操作的。其中包含了对主题的查询,创建,删除等功能。
# --bootstrap-server : 把当前的DOS窗口当成Kafka的客户端,那么进行操作前,就需要连接服务器,这里的参数就表示服务器的连接方式,因为我们在本机启动Kafka服务进程,且Kafka默认端口为9092,所以此处,后面接的参数值为localhost:9092,用空格隔开
# --alter : 表示对所有主题的查询操作,是个操作参数,后面无需增加参数值
# --topic : 修改的主题名称
# --partitions : 修改的配置参数:分区数量
# 指令
kafka-topics.bat --bootstrap-server localhost:9092 --topic test --alter --partitions 2

1.2.2.4删除主题
如果主题创建后不需要了,或创建的主题有问题,那么我们可以通过相应的指令删除主题。
- DOS窗口输入指令,删除指定名称的主题
# Kafka是通过kafka-topics.bat文件进行消息主题操作的。其中包含了对主题的查询,创建,删除等功能。
# --bootstrap-server : 把当前的DOS窗口当成Kafka的客户端,那么进行操作前,就需要连接服务器,这里的参数就表示服务器的连接方式,因为我们在本机启动Kafka服务进程,且Kafka默认端口为9092,所以此处,后面接的参数值为localhost:9092,用空格隔开
# --delete: 表示对主题的删除操作,是个操作参数,后面无需增加参数值。默认情况下,删除操作是逻辑删除,也就是说数据存储的文件依然存在,但是通过指令查询不出来。如果想要直接删除,需要在server.properties文件中设置参数delete.topic.enable=true
# --topic : 删除的主题名称
# 指令
kafka-topics.bat --bootstrap-server localhost:9092 --topic test --delete

注意:windows系统中由于权限或进程锁定的问题,删除topic会导致kafka服务节点异常关闭。

请在后续的linux系统下演示此操作。
-
-
- 生产数据
-
消息主题创建好了,就可以通过Kafka客户端向Kafka服务器的主题中发送消息了。Kafka生产者客户端并不是一个独立的软件系统,而是一套API接口,只要通过接口能连接Kafka并发送数据的组件我们都可以称之为Kafka生产者。下面我们就演示几种不同的方式:
1.2.3.1命令行操作
- 打开DOS窗口,进入e:/kafka_2.12-3.6.1/bin/windows目录

- DOS窗口输入指令,进入生产者控制台
# Kafka是通过kafka-console-producer.bat文件进行消息生产者操作的。
# 调用指令时,需要传递多个参数,而且参数的前缀为两个横线,因为参数比较多。为了演示方便,这里我们只说明必须传递的参数,其他参数后面课程中会进行讲解
# --bootstrap-server : 把当前的DOS窗口当成Kafka的客户端,那么进行操作前,就需要连接服务器,这里的参数就表示服务器的连接方式,因为我们在本机启动Kafka服务进程,且Kafka默认端口为9092,所以此处,后面接的参数值为localhost:9092,用空格隔开。早期版本的Kafka也可以通过 --broker-list参数进行连接,当前版本已经不推荐使用了。
# --topic : 主题的名称,后面接的参数值就是之前已经创建好的主题名称。
# 指令
kafka-console-producer.bat --bootstrap-server localhost:9092 --topic test

- 控制台生产数据

注意:这里的数据需要回车后,才能真正将数据发送到Kafka服务器。
1.2.3.2工具操作
有的时候,使用命令行进行操作还是有一些麻烦,并且操作起来也不是很直观,所以我们一般会采用一些小工具进行快速访问。这里我们介绍一个kafkatool_64bit.exe工具软件。软件的安装过程比较简单,根据提示默认安装即可,这里就不进行介绍了。
- 安装好以后,我们打开工具
- 点击左上角按钮File -> Add New Connection...建立连接
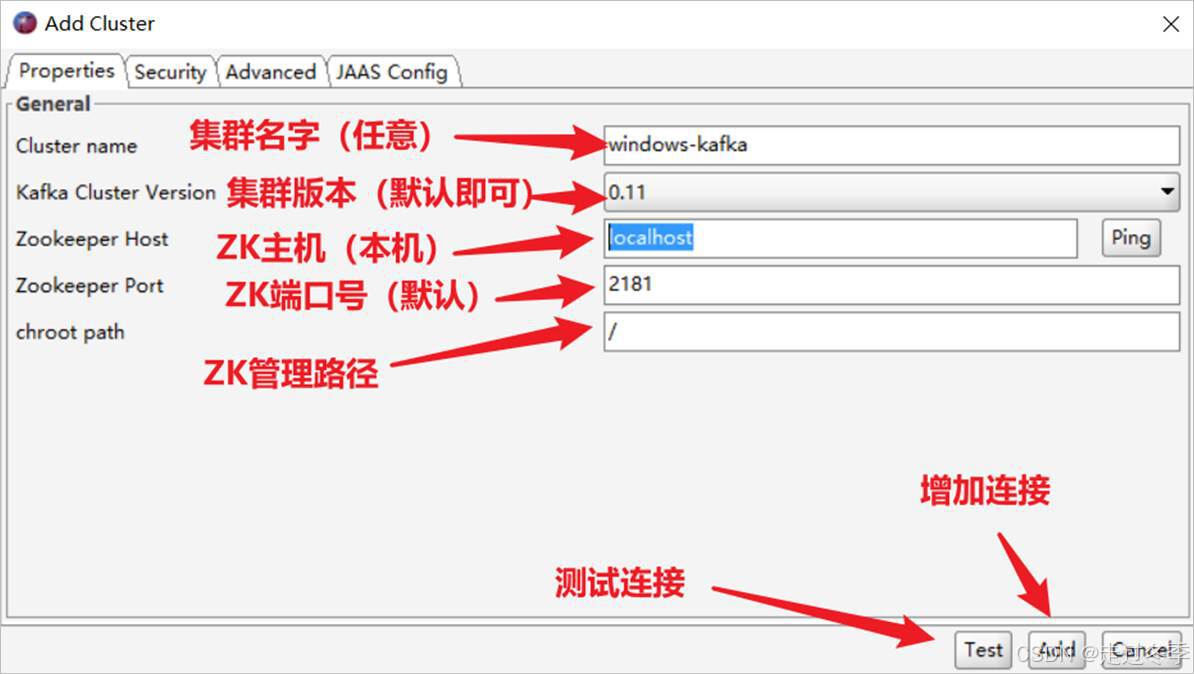
- 点击Test按钮测试
- 增加连接
- 按照下面的步骤,生产数据
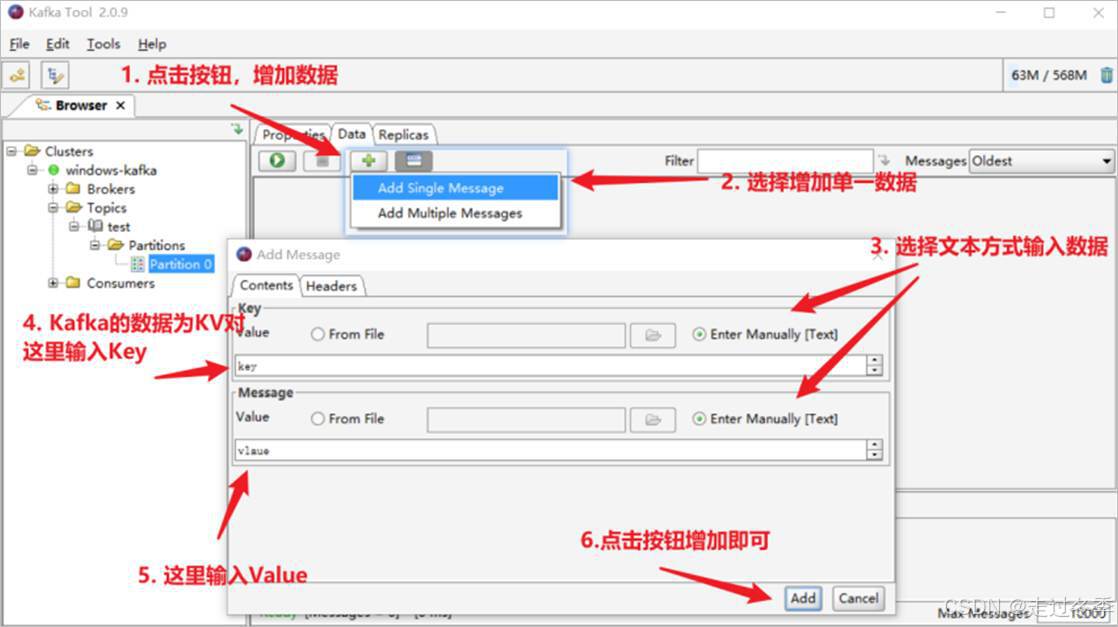
- 增加成功后,点击绿色箭头按钮进行查询,工具会显示当前数据
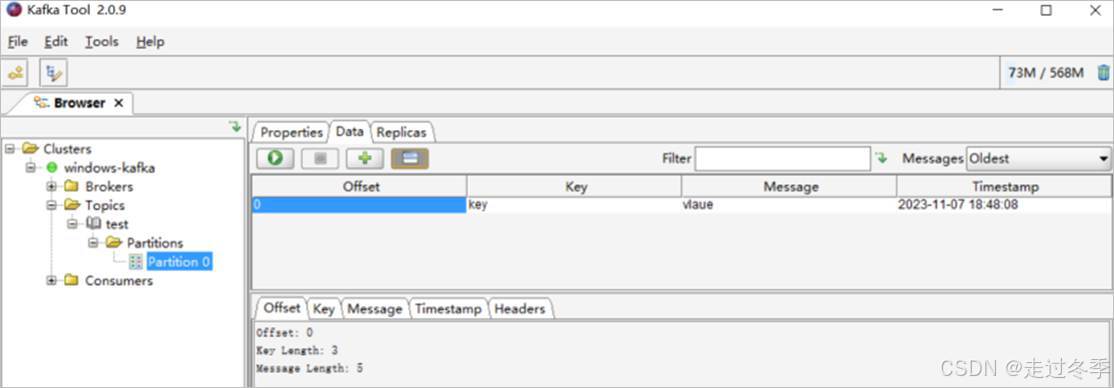
1.2.3.3 Java API
一般情况下,我们也可以通过Java程序来生产数据,所以接下来,我们就演示一下IDEA中使用Kafka Java API来生产数据:
- 创建Kafka项目
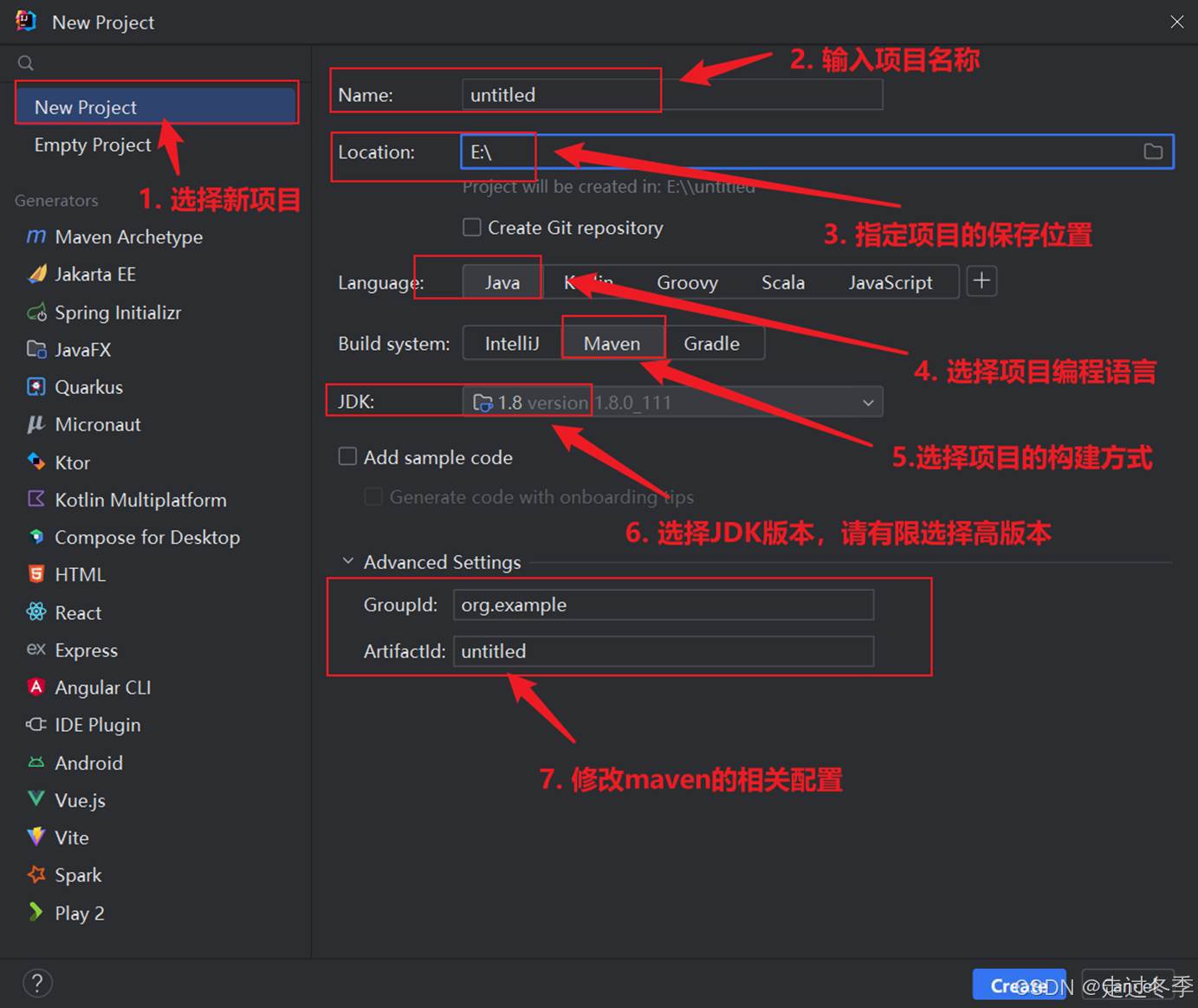
- 修改pom.xml文件,增加Maven依赖

<dependencies>
<dependency>
<groupId>org.apache.kafka</groupId>
<artifactId>kafka-clients</artifactId>
<version>3.6.1</version>
</dependency>
</dependencies>
- 创建 com.atguigu.kafka.test.KafkaProducerTest类
- 添加main方法,并增加生产者代码
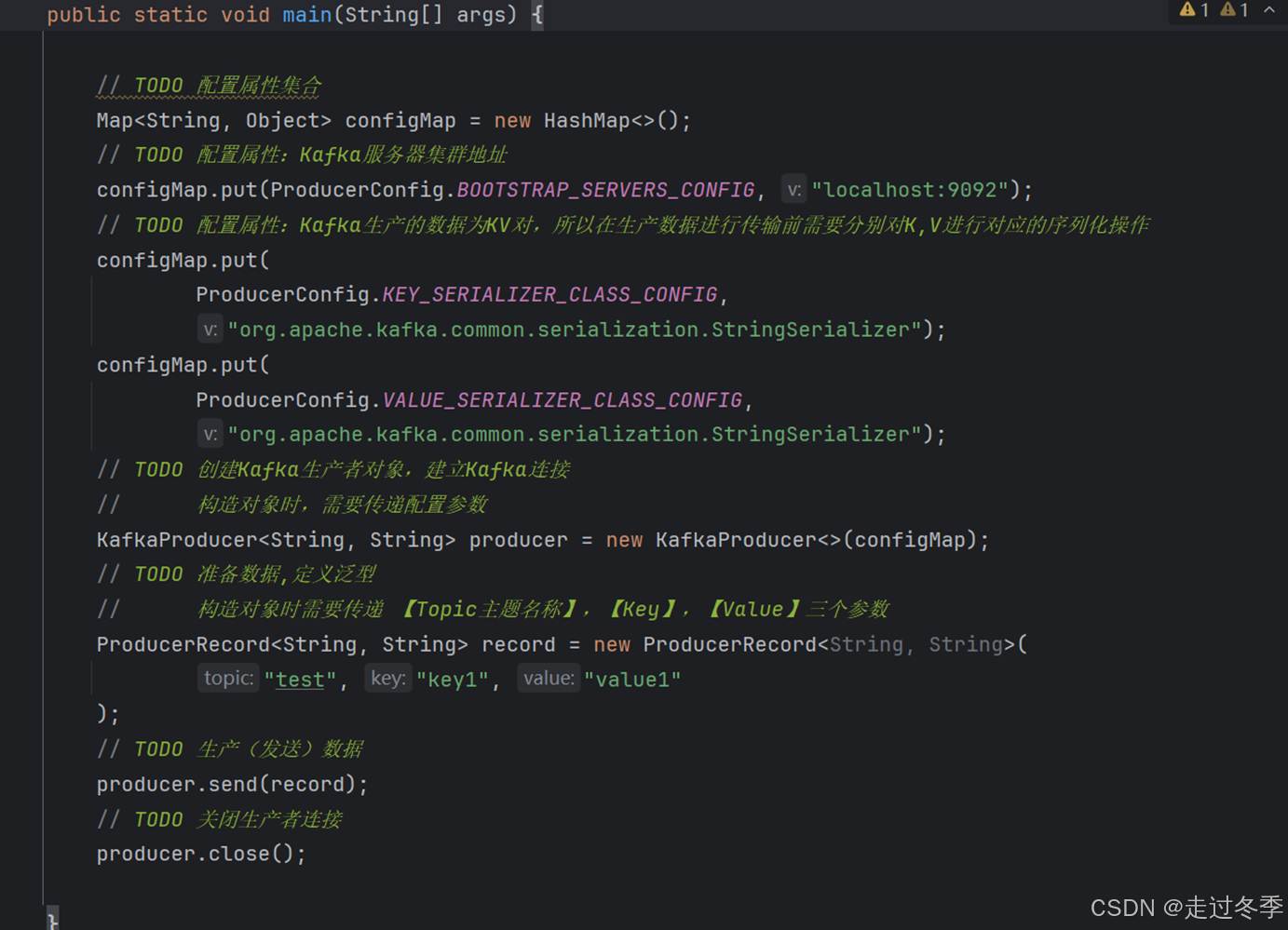
package com.atguigu.kafka.test;
import org.apache.kafka.clients.producer.KafkaProducer;
import org.apache.kafka.clients.producer.ProducerConfig;
import org.apache.kafka.clients.producer.ProducerRecord;
import java.util.HashMap;
import java.util.Map;
public class KafkaProducerTest {
public static void main(String[] args) {
// TODO 配置属性集合
Map<String, Object> configMap = new HashMap<>();
// TODO 配置属性:Kafka服务器集群地址
configMap.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, "localhost:9092");
// TODO 配置属性:Kafka生产的数据为KV对,所以在生产数据进行传输前需要分别对K,V进行对应的序列化操作
configMap.put(
ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG,
"org.apache.kafka.common.serialization.StringSerializer");
configMap.put(
ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG,
"org.apache.kafka.common.serialization.StringSerializer");
// TODO 创建Kafka生产者对象,建立Kafka连接
// 构造对象时,需要传递配置参数
KafkaProducer<String, String> producer = new KafkaProducer<>(configMap);
// TODO 准备数据,定义泛型
// 构造对象时需要传递 【Topic主题名称】,【Key】,【Value】三个参数
ProducerRecord<String, String> record = new ProducerRecord<String, String>(
"test", "key1", "value1"
);
// TODO 生产(发送)数据
producer.send(record);
// TODO 关闭生产者连接
producer.close();
}
}
-
-
- 消费数据
-
消息已经通过Kafka生产者客户端发送到Kafka服务器中了。那么此时,这个消息就会暂存在Kafka中,我们也就可以通过Kafka消费者客户端对服务器指定主题的消息进行消费了。
1.2.4.1命令行操作
- 打开DOS窗口,进入e:/kafka_2.12-3.6.1/bin/windows目录

- DOS窗口输入指令,进入消费者控制台
# Kafka是通过kafka-console-consumer.bat文件进行消息消费者操作的。
# 调用指令时,需要传递多个参数,而且参数的前缀为两个横线,因为参数比较多。为了演示方便,这里我们只说明必须传递的参数,其他参数后面课程中会进行讲解
# --bootstrap-server : 把当前的DOS窗口当成Kafka的客户端,那么进行操作前,就需要连接服务器,这里的参数就表示服务器的连接方式,因为我们在本机启动Kafka服务进程,且Kafka默认端口为9092,所以此处,后面接的参数值为localhost:9092,用空格隔开。早期版本的Kafka也可以通过 --broker-list参数进行连接,当前版本已经不推荐使用了。
# --topic : 主题的名称,后面接的参数值就是之前已经创建好的主题名称。其实这个参数并不是必须传递的参数,因为如果不传递这个参数的话,那么消费者会消费所有主题的消息。如果传递这个参数,那么消费者只能消费到指定主题的消息数据。
# --from-beginning : 从第一条数据开始消费,无参数值,是一个标记参数。默认情况下,消费者客户端连接上服务器后,是不会消费到连接之前所生产的数据的。也就意味着如果生产者客户端在消费者客户端连接前已经生产了数据,那么这部分数据消费者是无法正常消费到的。所以在实际环境中,应该是先启动消费者客户端,再启动生产者客户端,保证消费数据的完整性。增加参数后,Kafka就会从第一条数据开始消费,保证消息数据的完整性。
# 指令
kafka-console-consumer.bat --bootstrap-server localhost:9092 --topic test --from-beginning

1.2.4.2 Java API
一般情况下,我们可以通过Java程序来消费(获取)数据,所以接下来,我们就演示一下IDEA中Kafka Java API如何消费数据:
- 创建Maven项目并增加Kafka依赖
- 创建com.atguigu.kafka.test.KafkaConsumerTest类
- 添加main方法,并增加消费者代码

package com.atguigu.kafka.test;
import org.apache.kafka.clients.consumer.ConsumerConfig;
import org.apache.kafka.clients.consumer.ConsumerRecord;
import org.apache.kafka.clients.consumer.ConsumerRecords;
import org.apache.kafka.clients.consumer.KafkaConsumer;
import java.time.Duration;
import java.util.Arrays;
import java.util.Collections;
import java.util.HashMap;
import java.util.Map;
public class KafkaConsumerTest {
public static void main(String[] args) {
// TODO 配置属性集合
Map<String, Object> configMap = new HashMap<String, Object>();
// TODO 配置属性:Kafka集群地址
configMap.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, "localhost:9092");
// TODO 配置属性: Kafka传输的数据为KV对,所以需要对获取的数据分别进行反序列化
configMap.put(
ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG,
"org.apache.kafka.common.serialization.StringDeserializer");
configMap.put(
ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG,
"org.apache.kafka.common.serialization.StringDeserializer");
// TODO 配置属性: 读取数据的位置 ,取值为earliest(最早),latest(最晚)
configMap.put(ConsumerConfig.AUTO_OFFSET_RESET_CONFIG,"earliest");
// TODO 配置属性: 消费者组
configMap.put("group.id", "atguigu");
// TODO 配置属性: 自动提交偏移量
configMap.put("enable.auto.commit", "true");
KafkaConsumer<String, String> consumer = new KafkaConsumer<String, String>(configMap);
// TODO 消费者订阅指定主题的数据
consumer.subscribe(Collections.singletonList("test"));
while ( true ) {
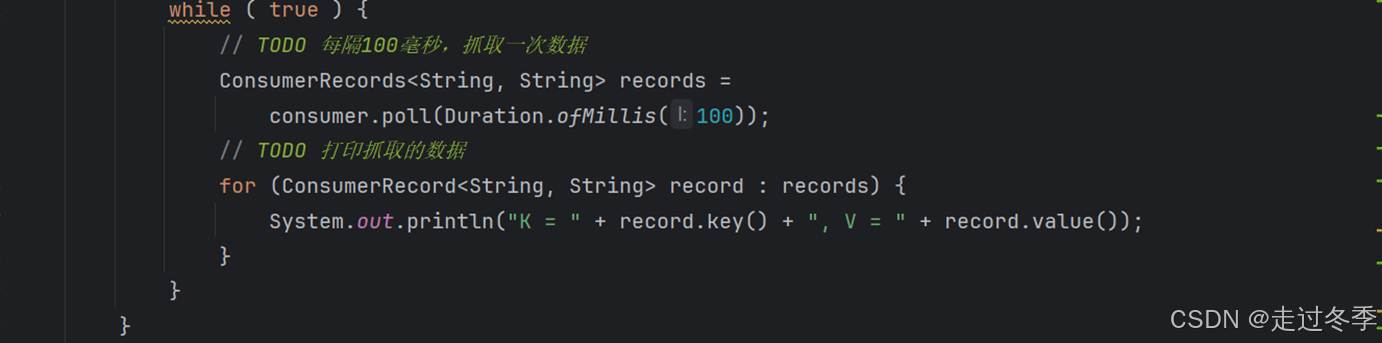
// TODO 每隔100毫秒,抓取一次数据
ConsumerRecords<String, String> records =
consumer.poll(Duration.ofMillis(100));
// TODO 打印抓取的数据
for (ConsumerRecord<String, String> record : records) {
System.out.println("K = " + record.key() + ", V = " + record.value());
}
}
}
}
-
-
- 源码关联(可选)
-
将源码压缩包kafka-3.6.1-src.tgz解压缩到指定位置

Kafka3.6.1的源码需要使用JDK17和Scala2.13进行编译才能查看,所以需要进行安装
1.2.5.1 安装Java17
- 再资料文件夹中双击安装包jdk-17_windows-x64_bin.exe

- 根据安装提示安装即可。
1.2.5.2 安装Scala
- 进入Scala官方网站https://www.scala-lang.org/下载Scala压缩包scala-2.13.12.zip。
- 在IDEA中安装Scala插件
- 项目配置中关联Scala就可以了
1.2.5.3 安装Gradle
- 进入Gradle官方网站https://gradle.org/releases/下载Gradle安装包,根据自己需要选择不同版本进行下载。下载后将Gradle文件解压到相应目录
- 新增系统环境GRADLE_HOME,指定gradle安装路径,并将%GRADLE_HOME%\bin添加到path中
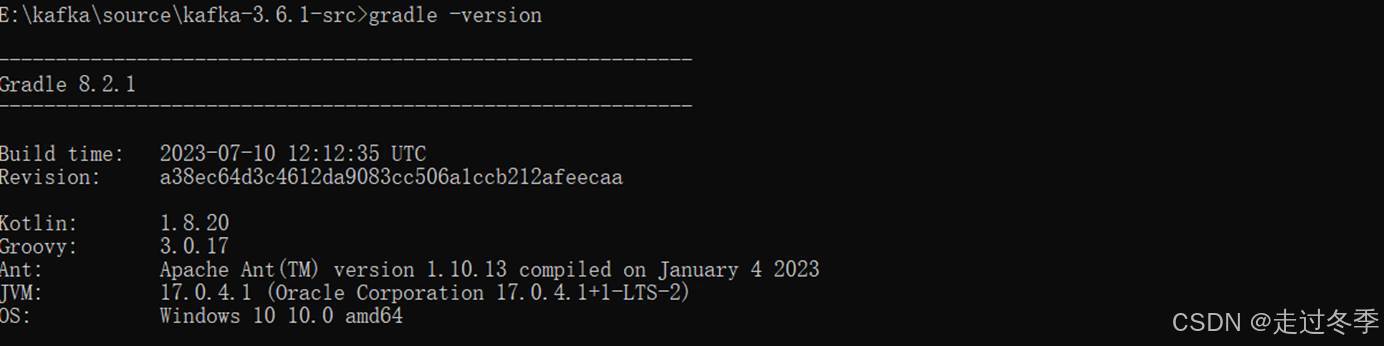
- Gradle安装及环境变量配置完成之后,打开Windows的cmd命令窗口,输入gradle –version
- 在解压缩目录中打开命令行,依次执行gradle idea命令
- 在命令行中执行gradle build --exclude-task test命令

- 使用IDE工具IDEA打开该项目目录
-
-
- 总结
-
本章作为Kafka软件的入门章节,介绍了一些消息传输系统中的基本概念以及单机版Windows系统中Kafka软件的基本操作。如果仅从操作上,感觉Kafka和数据库的功能还是有点像的。比如:
- 数据库可以创建表保存数据,kafka可以创建主题保存消息。
- Java客户端程序可以通过JDBC访问数据库:保存数据、修改数据、查询数据,kafka可以通过生产者客户端生产数据,通过消费者客户端消费数据。
从这几点来看,确实有相像的地方,但其实两者的本质并不一样:
- 数据库的本质是为了更好的组织和管理数据,所以关注点是如何设计更好的数据模型用于保存数据,保证核心的业务数据不丢失,这样才能准确地对数据进行操作。
- Kafka的本质是为了高效地传输数据。所以软件的侧重点是如何优化传输的过程,让数据更快,更安全地进行系统间的传输。
通过以上的介绍,你会发现,两者的区别还是很大的,不能混为一谈。接下来的章节我们会给大家详细讲解Kafka在分布式环境中是如何高效地传输数据的。


















 4628
4628

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











