







cpp-tbox项目链接 https://gitee.com/cpp-master/cpp-tbox
更多精彩内容欢迎关注微信公众号:码农练功房
往期精彩内容:
Linux应用框架cpp-tbox之弱定义
Linux应用框架cpp-tbox之日志系统设计
Linux应用框架cpp-tbox之事件驱动EventLoop
Linux应用框架cpp-tbox之事件驱动Event
Linux应用框架cpp-tbox之线程池
Linux应用框架cpp-tbox之应用层缓冲
Linux应用框架cpp-tbox之串口通信
Linux应用框架cpp-tbox之TCP通信(上篇)
Linux应用框架cpp-tbox之TCP通信(下篇)
Linux应用框架cpp-tbox之UDP通信
TCP是基于字节流的传输层通信协议,它将数据视为无结构的连续字节流,这意味着TCP并不会为应用层数据包设置边界标记。
当数据从发送方传输到接收方时,TCP并不保证数据会以特定的包形式到达,而是作为连续的字节流交付。
所以对于应用程序来说,就需要事先定义好通信协议,处理数据的分隔和重组问题,以此来识别消息的边界。
HTTP 协议是超文本传输协议,也就是HyperText Transfer Protocol,通过如下方式来解决消息边界问题:
- 通过设置回车符、换行符作为 HTTP header 的边界。
- 通过 Content-Length 字段作为 HTTP body 的边界。
以最常用的RESTfull API接口为例,前面的部分为HTTP header,json部分为HTTP body ,他们之间通过回车、换行分开:
POST /decoder/heartbeat HTTP/1.1
Host:10.22.211.129:8080
Content-Type:application/json
Content-Length:48
Authentication:Basic
Connection:keep-alive
{
"SessionID": "1",
"TimeStamp": "377340934"
}
通过Connection字段可以控制长短连接。
如果值为close,则在响应完成后会关闭连接。
如果值为keep-alive则为长连接,在这种模式下,客户端和服务器在完成一次请求-响应交互后不会立即关闭连接,而是保持TCP连接打开,以便后续的请求可以复用这个连接。这减少了连接建立和关闭的开销,提高了效率,尤其是在处理多个请求时。
cpp-tbox中实现了HTTP服务器,今天通过梳理代码,一究如何实现。
使用示例
std::string bind_addr = "0.0.0.0:12345";
auto sp_loop = Loop::New();
Server srv(sp_loop);
if (!srv.initialize(network::SockAddr::FromString(bind_addr), 1)) {
LogErr("init srv fail");
return 0;
}
srv.start();
srv.setContextLogEnable(true);
//! 添加请求处理
srv.use(
[&](ContextSptr ctx, const NextFunc &next) {
if (ctx->req().url.path == "/") {
ctx->res().status_code = StatusCode::k200_OK;
ctx->res().body = \
R"(
<head>
</head>
<body>
<p> <a href="/1" target="_blank">delay</a> </p>
<p> <a href="/2" target="_blank">now</a> </p>
</body>
)";
} else if (ctx->req().url.path == "/1") {
timers.doAfter(std::chrono::seconds(10), [ctx] {
ctx->res().status_code = StatusCode::k200_OK;
ctx->res().body = ctx->req().url.path;
});
} else if (ctx->req().url.path == "/2") {
ctx->res().status_code = StatusCode::k200_OK;
ctx->res().body = ctx->req().url.path;
}
}
);
srv.cleanup();
使用时,只需要关核心业务逻辑即可,不用再关心通信细节。
整体结构图
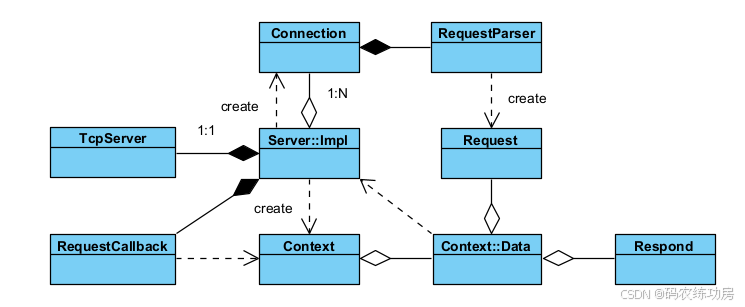
- Server::Impl是HTTP服务器的实现类,组合了TcpServer,通信功能委托给TcpServer实现。
- Server::Impl组合了多个RequestCallback,其中保存的是处理请求的具体方法(抽象出了中间件的概念)。
- Server::Impl创建Connection,保存各个连接的信息。
- Connection包含RequestParser,实现TCP字节流到HTTP消息的转换。
建立连接
这一步十分简单,连接建立后,IO线程回调 Server::Impl::onTcpConnected方法:
void Server::Impl::onTcpConnected(const TcpServer::ConnToken &ct)
{
auto conn = new Connection;
tcp_server_.setContext(ct, conn);
conns_.insert(conn);
}
为对应的连接创建Connection对象,为解析这条连接上的HTTP消息做准备。
同时把conn变量作为上下文保存起来,方便后面资源释放。
解析请求
当收到数据后,IO线程回调Server::Impl::onTcpReceived方法:
void Server::Impl::onTcpReceived(const TcpServer::ConnToken &ct, Buffer &buff)
{
// ......
while (buff.readableSize() > 0) {
size_t rsize = conn->req_parser.parse(buff.readableBegin(), buff.readableSize());
buff.hasRead(rsize);
if (conn->req_parser.state() == RequestParser::State::kFinishedAll) {
// ......
} else if (conn->req_parser.state() == RequestParser::State::kFail) {
// ......
} else {
break;
}
}
}
调用该连接建立时对应的Connection对象,委托其RequestParser成员对TCP字节流进行解析:
size_t RequestParser::parse(const void *data_ptr, size_t data_size)
{
// ......
}
RequestParser::parse内部实现是一个状态机,主要涉及到的是字符串操作和状态切换,限于篇幅,不贴具体代码。
完成解析后,若成功则状态置为State::kFinishedAll,失败为kFail。
解析成功的数据会放入到Request对象中,通过该对象,我们可以得到以下信息:
struct Request {
Method method = Method::kUnset;
HttpVer http_ver = HttpVer::kUnset;
Url::Path url;
// using Headers = std::map<std::string, std::string>;
Headers headers;
std::string body;
bool isValid() const;
std::string toString() const;
};
处理请求
当每得到一个完整的HTTP请求后(RequestParser状态为State::kFinishedAll),Server::Impl为该请求创建一个上下文Context对象:
void Server::Impl::onTcpReceived(const TcpServer::ConnToken &ct, Buffer &buff)
{
// ......
if (conn->req_parser.state() == RequestParser::State::kFinishedAll) {
Request *req = conn->req_parser.getRequest();
// ......
auto sp_ctx = make_shared<Context>(wp_parent_, ct, conn->req_index++, req);
handle(sp_ctx, 0);
}
}
在Context对象中会存放请求数据和处理后的响应,HTTP请求会在Server::Impl::handle中实际处理:
void Server::Impl::handle(ContextSptr sp_ctx, size_t cb_index)
{
if (cb_index >= req_cb_.size())
return;
auto func = req_cb_.at(cb_index);
++cb_level_;
if (func)
func(sp_ctx, std::bind(&Impl::handle, this, sp_ctx, cb_index + 1));
--cb_level_;
}
req_cb_中保存的是RequestCallback,是通过Server::Impl::use接口预先设置的:
void Server::Impl::use(const RequestCallback &cb)
{
req_cb_.push_back(cb);
}
void Server::Impl::use(Middleware *wp_middleware)
{
req_cb_.push_back(bind(&Middleware::handle, wp_middleware, _1, _2));
}
Server::Impl::use接口中涉及到的代码元素定义如下:
using NextFunc = std::function<void()>;
using RequestCallback = std::function<void(ContextSptr, const NextFunc &)>;
class Middleware {
public:
~Middleware() { }
public:
virtual void handle(ContextSptr sp_ctx, const NextFunc &next) = 0;
};
class Router : public Middleware {
public:
Router();
~Router();
// ......
public:
virtual void handle(ContextSptr sp_ctx, const NextFunc &next) override;
// ......
};
这里借鉴了node.js中Express的中间件设计思想。
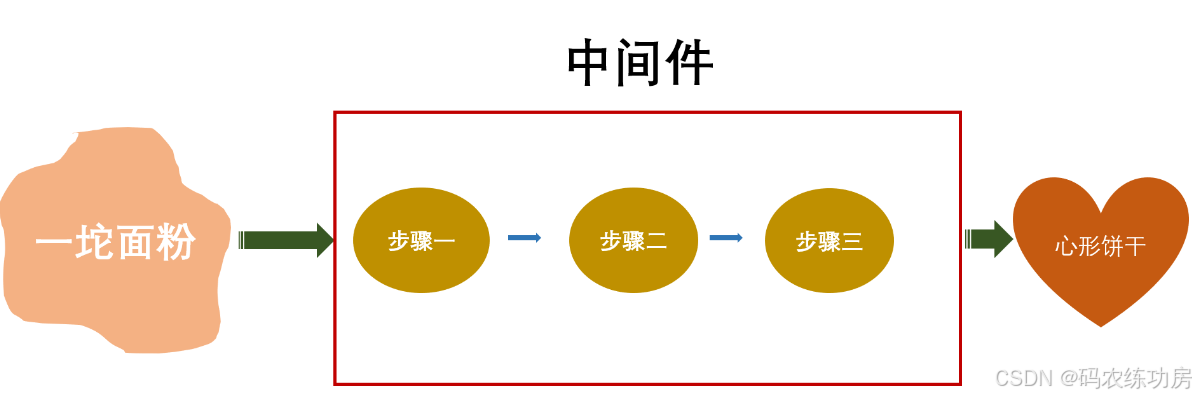
中间件
中间件(Middleware)是一个概念,用来特指业务流程的中间处理环节:
在Express服务器中,也是这样的道理,当客户端请求到达Express服务器后,调用多个中间件来对这次请求进行预处理,处理完毕之后,才会将处理完成的结果给到路由来完成响应,每一个的中间件后面都有一个next()函数,next()函数是实现多个中间件连续调用的关键,它表示把流转关系转交给下一个中间件,或者转交给路由。next()是必须要写的,并且要写在中间件处理程序的最后 。
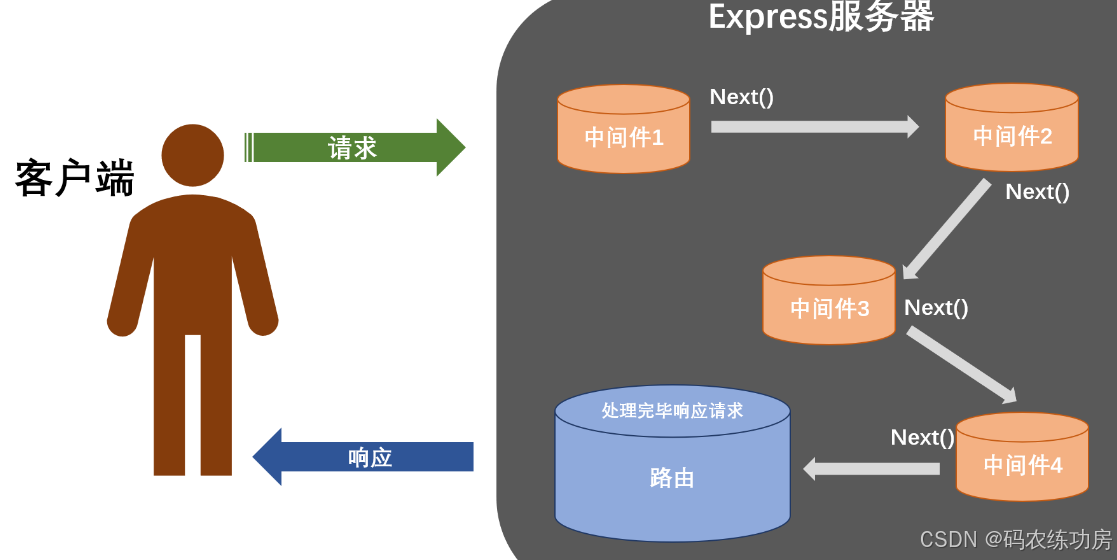
为了更好理解中间件的调用逻辑,对代码做了简化,但不失一般性:
#include <iostream>
#include <vector>
#include <functional>
using NextFunc = std::function<void()>;
using RequestCallback = std::function<void(void*, const NextFunc&)>;
class Server
{
public:
void use(const RequestCallback& cb)
{
req_cb_.push_back(cb);
}
void handle(void *data, size_t cb_index)
{
if (cb_index >= req_cb_.size())
return;
auto func = req_cb_.at(cb_index);
if (func)
func(nullptr, std::bind(&Server::handle, this, nullptr, cb_index + 1));
}
private:
std::vector<RequestCallback> req_cb_;
};
int main()
{
Server ser;
ser.use([](void*, const NextFunc&next) {
std::cout << "Hello World1\n";
next();// 如果不写next则后续的中间件不会被调用
});
ser.use([](void*, const NextFunc&next) {
std::cout << "Hello World2\n";
next();
});
ser.handle(nullptr, 0);
system("pause");
return 0;
}
我们使用use来定义中间件,可以看到中间件的调用逻辑实现的十分简洁、漂亮。
当客户端请求到达服务器后,会按照中间件定义的先后顺序来依次进行调用 。这段代码执行的结果是:
Hello World1
Hello World2
回复响应
Context对象由智能指针管理,std::shared_ptr为值语义,在bind时会拷贝std::shared_ptr,所以延长了对象的生命周期:
void Server::Impl::handle(ContextSptr sp_ctx, size_t cb_index)
{
if (cb_index >= req_cb_.size())
return;
auto func = req_cb_.at(cb_index);
++cb_level_;
if (func)
func(sp_ctx, std::bind(&Impl::handle, this, sp_ctx, cb_index + 1));// 延长了对象的生命周期
--cb_level_;
}
当所有中间件被调用后(即处理完毕),Server::Impl::handle提前返回(判断条件为cb_index >= req_cb_.size()),Context对象引用计数为0,该对象析构:
Context::~Context()
{
d_->wp_server->commitRespond(d_->conn_token, d_->req_index, d_->sp_res);
CHECK_DELETE_RESET_OBJ(d_->sp_req);
CHECK_DELETE_RESET_OBJ(d_);
}
在析构函数中向客户端提交响应结果。
然而在长连接场景下,如何保证Respond与Request的顺序一致性?(即客户端发送了3个请求:req1、req2、req3,服务器按照rsp1、rsp2、rsp3的顺序回复。)
这里通过Connection对象中的索引来实现:
struct Connection {
RequestParser req_parser;
int req_index = 0; //!< 下一个请求的index
int res_index = 0; //!< 下一个要求回复的index,用于实现按顺序回复
int close_index = numeric_limits<int>::max(); //!< 需要关闭连接的index
map<int, Respond*> res_buff; //!< 暂存器
~Connection();
};
- req_index用来标记Context包含的请求是这个TCP连接上的第几个HTTP请求。
- res_index用来标记此次应该回复给客户端的是哪个请求对应的响应。
- close_index用来标记当前TCP连接上最后一个HTTP请求。
具体实现移步Server::Impl::commitRespond,限于篇幅,不展开。
资源释放
我们现在回过头来看看,对于HTTP服务器,我们具体分配了哪些资源,这些资源又在何时释放的:
- Server::Impl贯穿整个程序生命周期,不释放
- Connection随着TCP建立而创建,TCP断开而销毁
- Context随着一条HTTP消息的到来而建立,这条HTTP消息处理完毕而销毁
- Request随着一条HTTP消息的到来而建立,这条HTTP消息处理完毕而销毁
- Respond随着一条HTTP消息的到来而建立,这条HTTP消息实际发送给客户端而销毁
总结
- TCP是基于字节流的传输层通信协议,在实际使用过程中需要设计好消息边界。
- 中间件的思想有借鉴意义,C++的实现简洁、漂亮。

















 2669
2669

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









