



我们将创建一个 Scrapy 项目,定义一个 Spider 来抓取 https://quotes.toscrape.com/ 网站上的名言数据,并将结果保存为 JSON 文件。
步骤1:安装 Scrapy
首先,在命令行或终端中执行以下命令安装 Scrapy:
pip install scrapy
步骤2:创建一个新的 Scrapy 项目
在命令行或终端中进入到你想要保存项目的目录,然后执行以下命令创建一个新的 Scrapy 项目:
scrapy startproject quotes_crawler

这将会在当前目录下创建一个名为 quotes_crawler 的文件夹,其中包含了一个 Scrapy 项目的基本结构。
步骤3:定义 Spider
进入到 quotes_crawler 文件夹中,然后进入到 spiders 文件夹。打开 spiders 文件夹,然后创建一个名为 quotes_spider.py 的 Python 文件,并在其中编写以下代码:
import scrapy
class QuotesSpider(scrapy.Spider):
name = 'quotes'
start_urls = ['http://quotes.toscrape.com/']
def parse(self, response):
for quote in response.css('div.quote'):
yield {
'text': quote.css('span.text::text').get(),
'author': quote.css('span small.author::text').get(),
'tags': quote.css('div.tags a.tag::text').getall(),
}
next_page = response.css('li.next a::attr(href)').get()
if next_page is not None:
yield response.follow(next_page, self.parse)
步骤4:运行 Spider
在命令行或终端中进入到 quotes_crawler 文件夹下,执行以下命令来运行 Spider 并将结果保存为 JSON 文件:
scrapy crawl quotes -o quotes.json
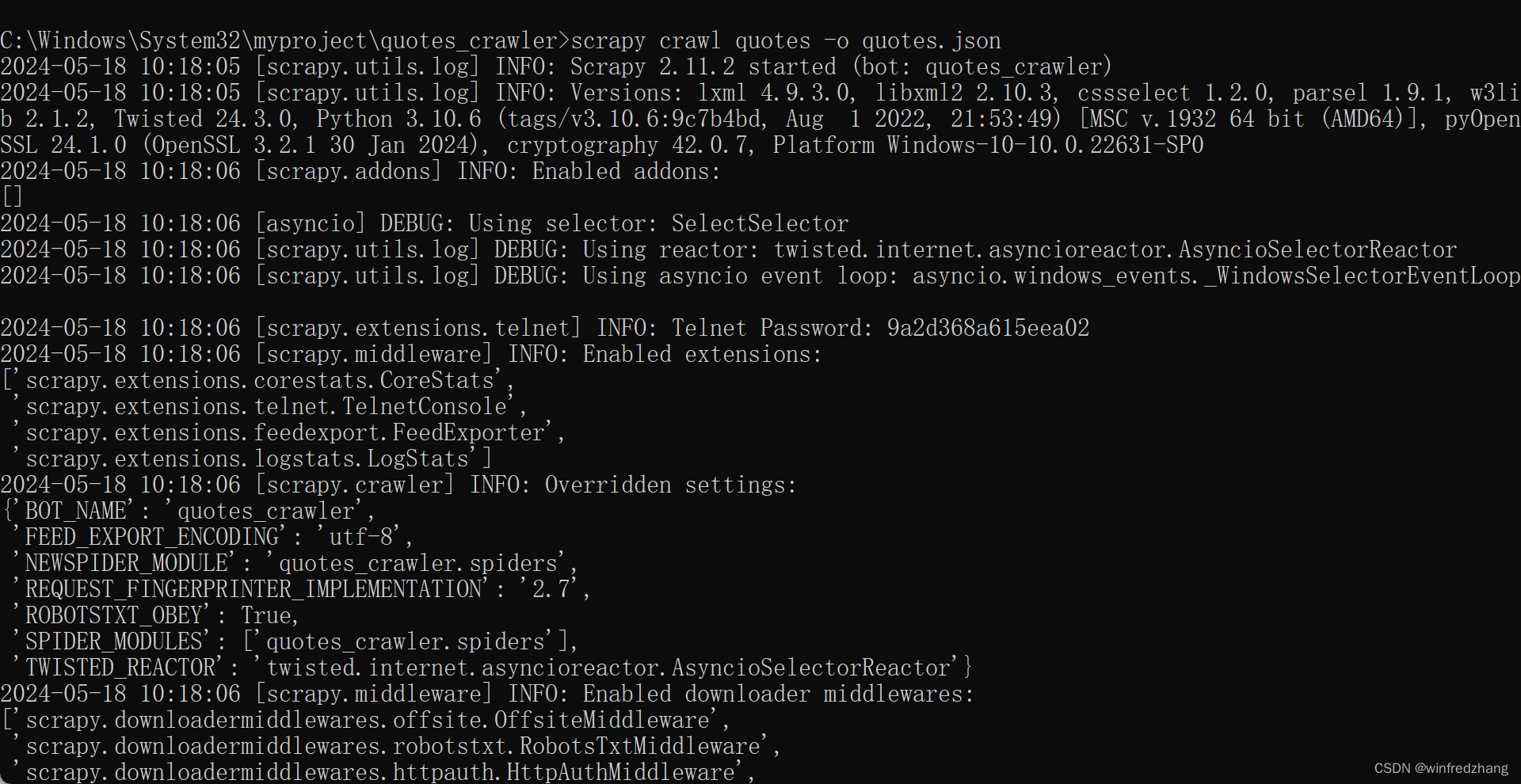
这将会启动 Spider 并抓取 https://quotes.toscrape.com/ 网站上的名言数据,并将结果保存为名为 quotes.json 的 JSON 文件。
结果
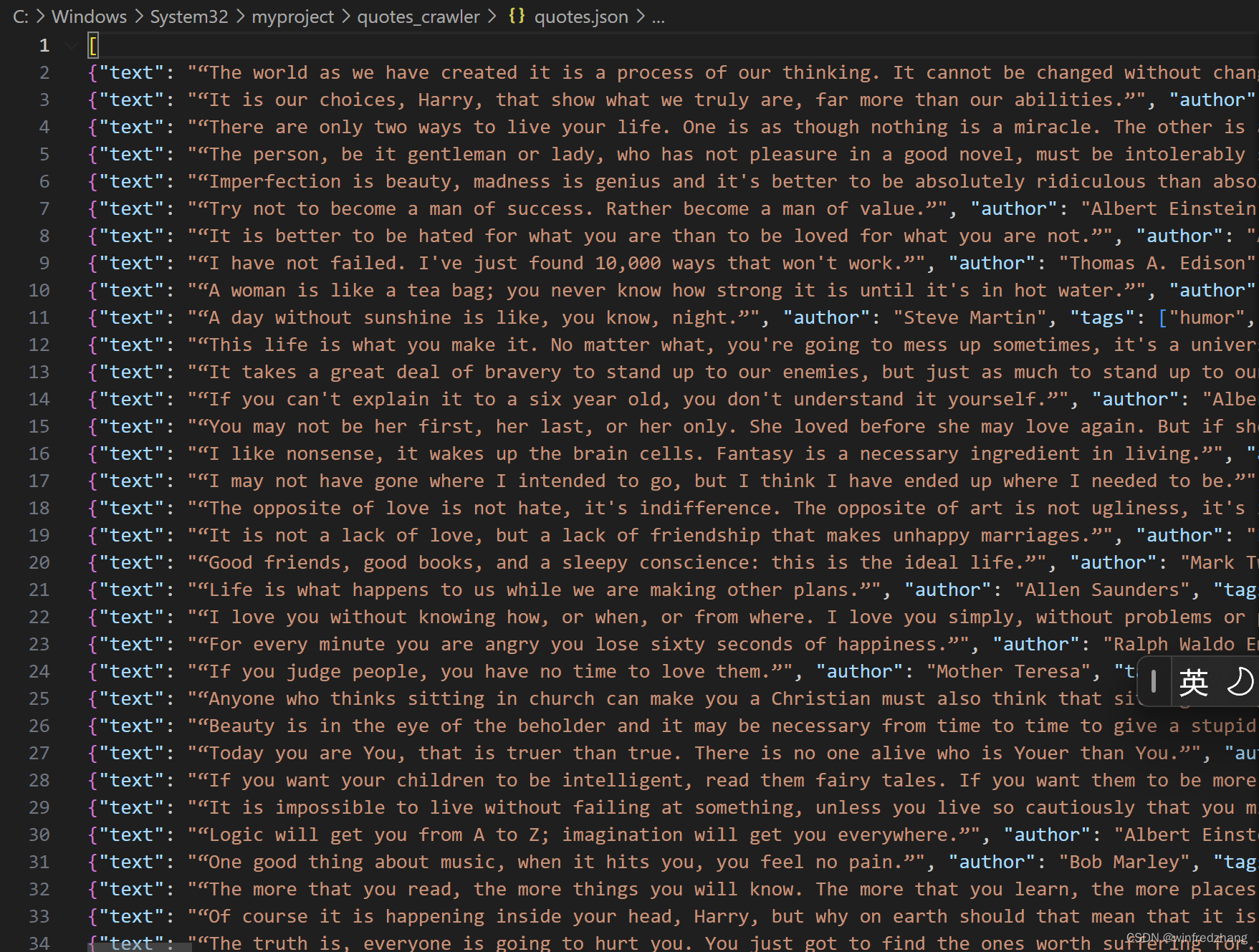
运行成功后,你将得到一个名为 quotes.json 的文件,其中包含了抓取到的名言数据,格式类似于:
[
{"text": "The world as we have created it is a process of our thinking. It cannot be changed without changing our thinking.", "author": "Albert Einstein", "tags": ["change", "deep-thoughts", "thinking", "world"]},
{"text": "It is our choices, Harry, that show what we truly are, far more than our abilities.", "author": "J.K. Rowling", "tags": ["abilities", "choices"]},
...
]
这就是使用 Scrapy 抓取网站数据并保存的一个简单例子。通过这个例子,你可以了解到如何创建一个 Scrapy 项目,定义 Spider,并将抓取到的数据保存到文件中。

















 412
412

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









