




 本文介绍了如何在PyCharm中创建Scrapy爬虫项目。首先确保安装了Scrapy,然后在PyCharm的Terminal中通过`scrapy startproject crawlPro`创建项目。接着,创建爬虫源文件,使用命令`scrapy genspider 文件名 原始url`,这会在`spiders`目录下生成一个Python文件。最后,运行爬虫项目,通过`scrapy crawl 文件名`执行爬虫。
本文介绍了如何在PyCharm中创建Scrapy爬虫项目。首先确保安装了Scrapy,然后在PyCharm的Terminal中通过`scrapy startproject crawlPro`创建项目。接着,创建爬虫源文件,使用命令`scrapy genspider 文件名 原始url`,这会在`spiders`目录下生成一个Python文件。最后,运行爬虫项目,通过`scrapy crawl 文件名`执行爬虫。
一、在安装好scrapy框架后,就开始迫不及待要创建scrapy项目了,我用的是pycharm进行创建的,打开pycharm,在下方找到Terminal

二、点击Terminal,然后输入scrapy startproject crawlPro。 crawlPro未工程的名字
scrapy startproject crawlPro #最后一个为工程名称

三、输入后,会自动创建一个目录,并在下方提示要再创建一个爬虫源文件
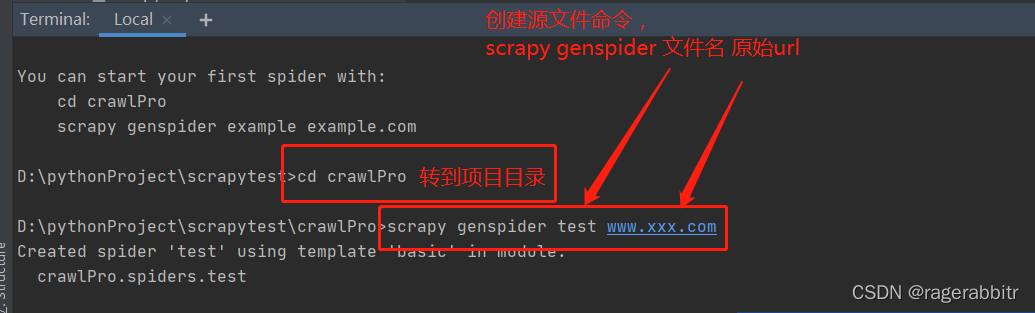
 然后转到项目下, 创建源文件,命令为scrapy genspider 文件名 原始url,原始url可以随意先编写一个
然后转到项目下, 创建源文件,命令为scrapy genspider 文件名 原始url,原始url可以随意先编写一个
scrapy genspider test www.xxx.com #最后两项为文件名和原始url,原始url后期进入程序后可以修改
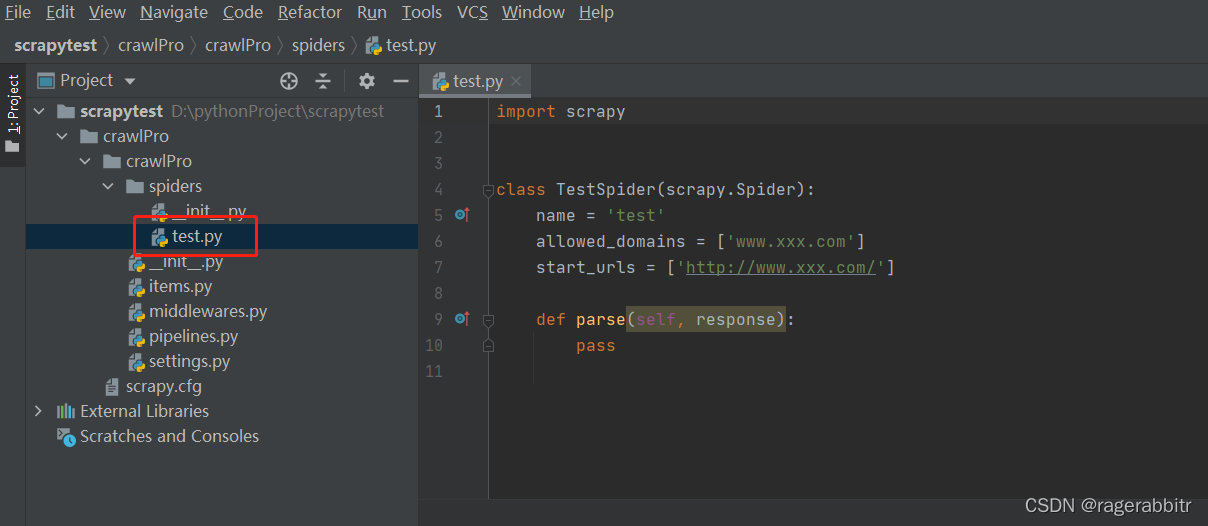
 这个时候,在spiders文件夹下,会多一个test.py的文件,这样源文件就建立好了,整个项目建立完毕。
这个时候,在spiders文件夹下,会多一个test.py的文件,这样源文件就建立好了,整个项目建立完毕。
四、下面可以执行一下,在Terminal中执行语句scrapy crawl 文件名,即可执行工程。
scrapy crawl test # 最后一项是文件名,而不是工程名称,这样便可执行整个工程


















 2344
2344

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









