






"nnU-Net: Self-adapting Framework for U-Net-Based Medical Image Segmentation" 即 nnU-Net:基于U-Net的自适应医学图像分割框架。
论文链接:https://arxiv.org/abs/1809.10486
代码链接:https://github.com/MIC-DKFZ/nnUNet
目录
1、nnU-Net 是什么?
nnU-Net是由德国癌症研究中心、海德堡大学以及海德堡大学医院研究人员(Fabian Isensee, Jens Petersen, Andre Klein)提出来的一个自适应任何新数据集的医学影像分割框架,该框架能根据给定数据集的属性自动调整所有超参数,整个过程无需人工干预。仅仅依赖于朴素的U-Net结构(就是原始U-Net)和鲁棒的训练方案,nnU-Net在六个得到公认的分割挑战中实现了最先进的性能。
(可以将nnUNet用于医学图像分割用的原因是大部分的医学图像分割论文的实验对比中都用nnU-Net测试一下。看一下该任务的大致效果。所以要么使用的模型效果超过它,要么基于nnUNet改进。)
2、介绍
通常的分割模型都是针对某一特定任务(如 心脏分割)进行研究的,需要特定的网络架构设计以及训练方法的设定,它只能解决特定问题而无法解决一系列问题。而这个医学分割十项全能赛就是希望参赛者能开发一个适应多种分割任务的算法-nnUNet。
3、nnUNet的框架
nnU-Net (”no-new-Net”)框架。它驻留在一组三个相对简单的U-Net模型上,只包含对原始U-Net的微小修改。省略了最近提出的扩展,例如使用残差连接、密集连接或注意机制。nnU-Net会自动根据给定的图像几何结构调整其结构。更重要的是,nnU-Net框架彻底定义了围绕它们的所有其他步骤。
预处理(例如重采样和标准化)、训练(例如损失、优化器设置和数据扩充),推理(例如,基于补丁的策略和通过跨测试时扩展模型的集成)和潜在的后处理(例如,强制执行单个连通成分分析,如果适用)。
(其中,nnUNet对不同数据的处理方法是关键。)
4、nnUNet详细结构
主要包括三种Unet: 2D U-Net, 3D U-Net and U-Net Cascade(U-Net级联)。2D U-Net, 3D U-Net都是输入的全分辨率图像。级联U-Net 首先使用低分辨率的图像做一个粗分割,再使用全分辨图像做细分割。与U-Net的原始公式相比,我们的架构修改几乎可以忽略不计,相反,我们致力于为这些模型设计一个自动训练管道。
5、UNet的优点:
U-Net是近年来备受关注的一种成功的编解码网络。其编码器部分的工作原理与传统的分类CNN相似,它以减少空间信息为代价,连续地聚集语义信息。由于在分割过程中,语义和空间信息对网络的成功都至关重要,因此必须以某种方式恢复丢失的空间信息。U-Net通过解码器来实现这一点,解码器接收来自“U”底部的语义信息,并将其与通过跳过连接直接从编码器获得的更高分辨率特征图进行重新组合。与其他分割网络(如FCN[和以前的DeepLab迭代)不同,这使得U-Net能够很好地分割精细结构。
6、3D UNet
2D UNet在3D医学图像上无法汇总和考虑沿z轴的有价值的信息。3D U-Net是选择3D图像数据的适当方法。在理想情况下,我们将在整个患者的图像上训练。但是实际上,我们受到可用GPU内存量的限制,这使我们只能在图像块(image patches)上训练此体系结构。对于由较小图像组成的数据集(按每个患者的体素数量而言)基于 patch 的训练并不是问题(例如脑肿瘤,海马和前列腺等挑战的数据集)。
但普遍医学三维图像是很大的,不可能整个图像输入到网络中,因此就会把图像切成patch。而像肝这种大结构,切了之后就会损失很多上下文信息,即遮挡视野,不能将足够的上下文信息收集到例如计算机网络中,正确地区分肝脏和其他器官。
7、U-Net Cascade
为了解决3D U-Net在具有大图像尺寸的数据集上的实际缺陷,我们另外提出了一个级联模型。因此,首先要对降采样的图像进行3D U-Net训练(阶段1)。然后,将此U-Net的分割结果上采样到原始体素间距,并作为附加(一个热编码)输入通道传递到第二个3D U-Net,第二个3D U-Net在上以全分辨率进行训练(第2阶段)
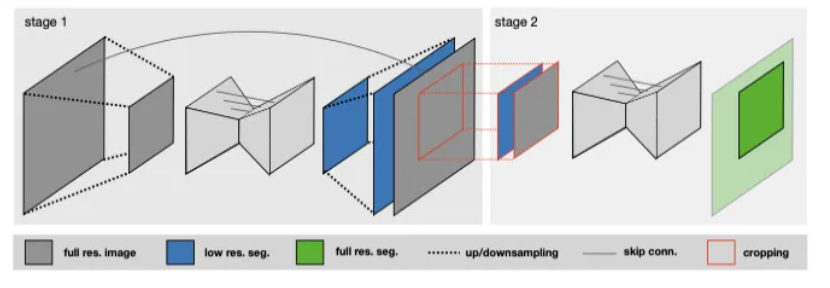
(省略了2D UNet,简单介绍了3D UNet和U-Net Cascade,当输入不同的数据集时,可根据自己的任务,选择其中一个模型(算法),或者3个都跑一边看哪个结果好)
........中间的具体训练内容省略了......
8、讨论
在本文中,提出了医学领域的nnU-Net分割框架,该框架直接围绕原始U-Net架构构建,并动态地使其自身适应于任何给定数据集的细节。基于我们的假设,即非架构修改可能比最近提出的某些架构修改功能强大得多,该框架的本质是对自适应预处理,训练方案和推理的全面设计。
适应新的分割任务所需的所有设计选择均以全自动方式完成,无需人工干预。对于每个任务,nnU-Net会针对三个不同的自动配置的U-Net模型自动运行五倍交叉验证,然后选择具有最高平均前景骰子得分的模型(或整体)进行最终提交。
训练三个模型并为每个数据集独立选择最佳模型并不是最干净的解决方案。给定一个较大的时间尺度,可以在训练之前研究适当的启发式方法,以确定给定数据集的最佳模型。当前的趋势倾向于U-Net级联(如果无法应用级联,则倾向于3D U-Net), 唯一的例外是前列腺和肝脏任务。此外,我们许多设计选择的额外好处,例如使用Leaky ReLUs 而不是常规ReLU,但数据扩充参数不合适。

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









