






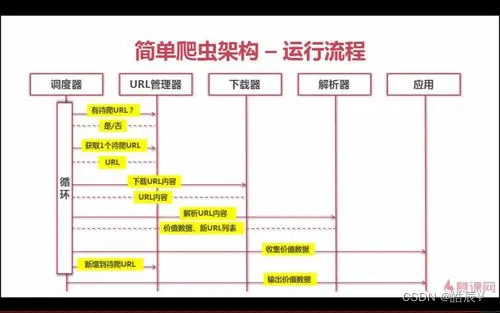
基本思路
爬虫是模拟成浏览器,批量的获取数据的过程。
可见即可爬,你能听得歌才能爬
爬虫思路:模拟 浏览器 发送网络请求
爬虫常用知识点
字符串数据类型
1.基本数据类型 字符串使用定义
2.数据容器 list(列表) dict(字典)
3.for循环使用
4.requests的简单使用
5.解析方法的使用
列表切片
列表[ ] 数据容器 存储数据内容
a = [1,2,3,4,5,6,7,8,9]
切片
切片的方法可取出一个列表中的一部分并且生成一个新的列表
通过:变量名[索引值 : 索引值 : 步长] ———— 进行切片
(步长不能为0)
取部分元素:
a [ 0 : 3 ] ———— 取出列表中 0 - 2 的元素 组成一个新列表
a = [ 1 , 2 , 3 ] (左闭右开原则)
a [ 2 : ] ———— 取列表索引值为2及以后的元素 组成一个新列表
a = [ 4 , 5 , 6 , 7 , 8 , 9 ]
a [ : 3 ] ———— 取列表从开始到索引值为3之前的元素 组成一个新列表
a = [ 1 , 2 , 3 ]
间隔取元素:
a [ 0 : 3 : 2 ] ———— 在范围里每隔一个取一个元素 组成一个新列表
a = [ 1 , 3 ]
选取整个列表:
a [ : ] ———— 取出所有元素
a = [ 1 , 2 , 3 , 4 , 5 , 6 , 7 , 8 , 9 ]
单章小说爬取
import requests
import parsel
url="https://www.biqg8.com/0_1/1.html"
response=requests.get(url)
response.encoding='gbk'#中文编码
print(response.text)
selector=parsel.Selector(response.text)
title=selector.css('html body div#wrapper div.content_read div.box_con div.bookname h1::text').get()
print(title)
"""
解析数据:
css xpath 当得到数据,有标签的时候
re 当你没办法使用标签提取数据的时候用正则,可以直接对于字符串数据进行提取
"""
得到小说的标题

import requests
import parsel
# 设置要爬取的网页 URL
url = "https://www.biqg8.com/0_1/1.html"
# 发送 GET 请求获取网页内容
response = requests.get(url)
# 设置网页内容的编码格式为 gbk
response.encoding = 'gbk'
# 使用 parsel 构建选择器对象
selector = parsel.Selector(response.text)
# 使用选择器提取标题信息
title = selector.css('html body div#wrapper div.content_read div.box_con div.bookname h1::text').get()
print(title)
# 使用选择器提取正文内容列表
content_list = selector.css('#content::text').getall()
# 将内容列表转换为字符串
content = ''.join(content_list)
print(content)
# 将标题和内容写入文件
f = open(title + '.txt', mode='w', encoding='utf-8')
f.write(title)
f.write('\n')
f.write(content)
f.close()
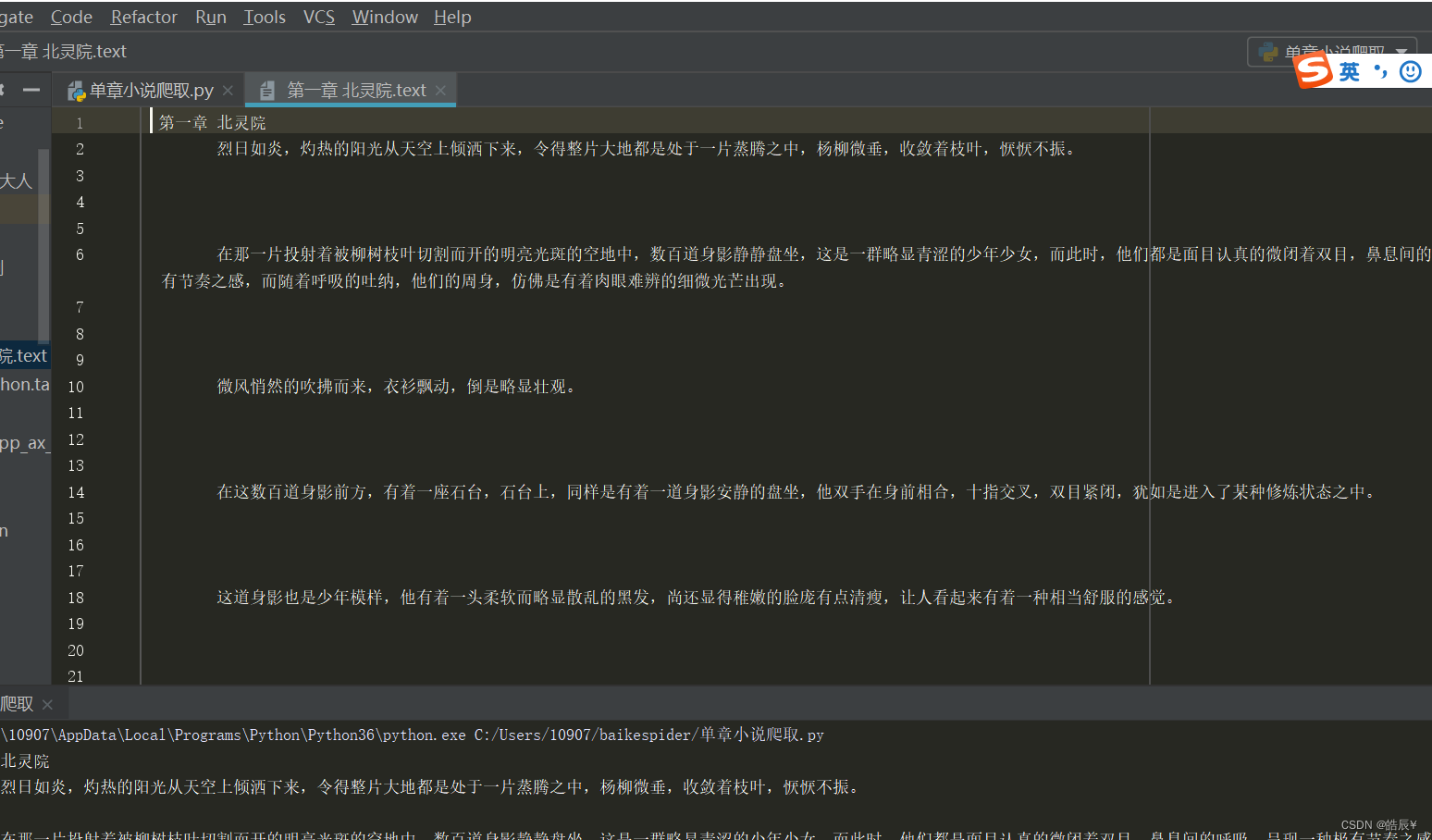
成功获取小说文字如下图

















 1057
1057

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









