



1.生成数据

数据可视化显示
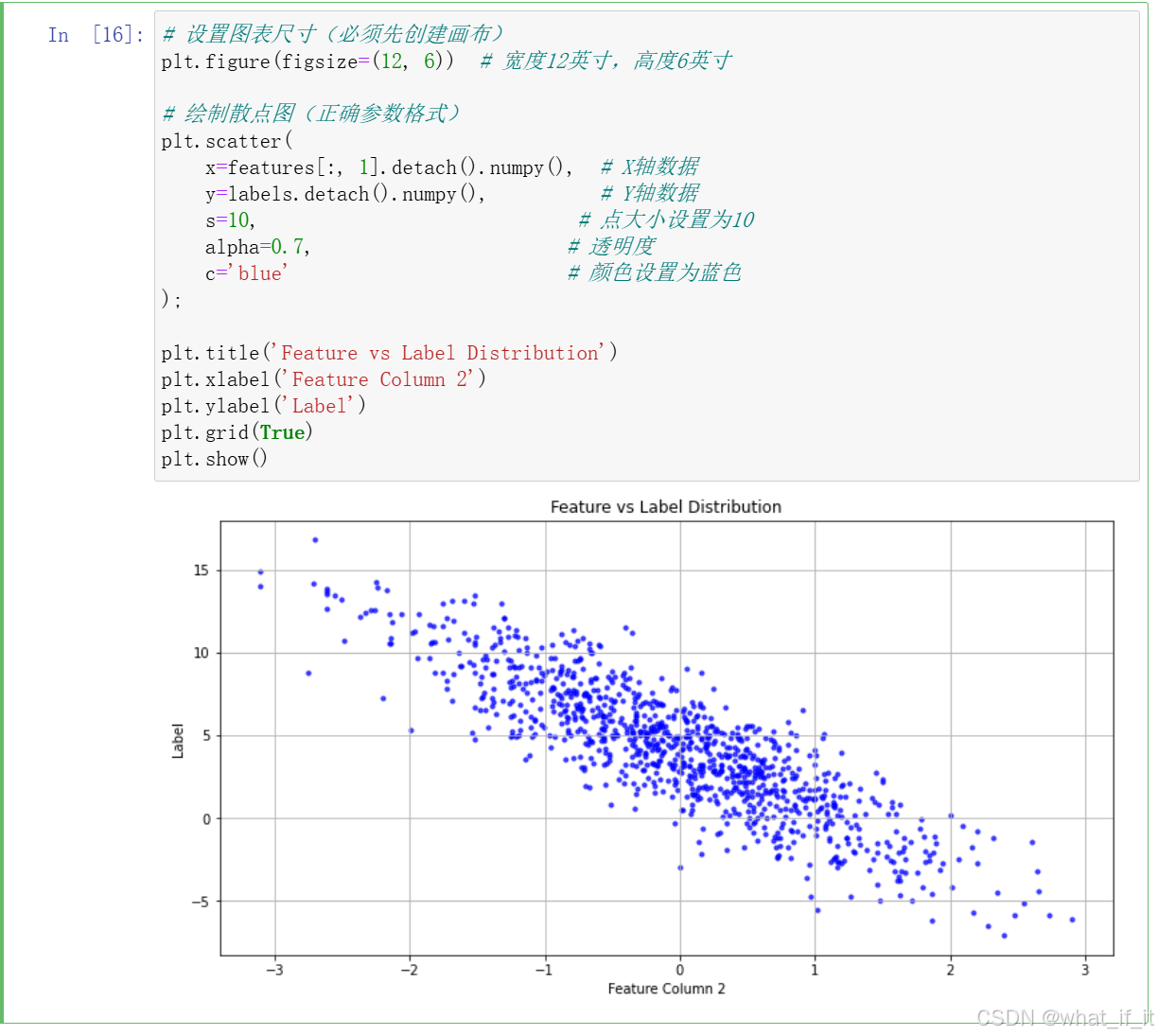
x=features[:, 1].detach().numpy()
features是一个形状为(样本数, 特征数)的 Tensor。按行取是因为,我们想取每个样本特征值[:, 1]表示选择所有行的第2列(因为索引从0开始)。 取第二列特征-
.detach():
- 如果
features是在训练过程中生成的 Tensor(带有梯度跟踪),.detach()会创建一个不依赖计算图的新 Tensor,防止梯度计算占用内存。- 如果是推理阶段的数据,这一步可以省略,但加上更安全。
.numpy():
- 将 PyTorch Tensor 转换为 NumPy 数组,因为 Matplotlib 的
scatter()函数需要 NumPy 格式的数据。
选取小批量数据

yield是 Python 中非常强大的关键字,用于定义生成器函数(Generator Function)。它的核心作用是按需生成数据并保持函数状态,而无需一次性计算所有结果。这里yield用于分批次返回数据
2.定义模型
模型初始化

定义参数 w,b
torch.zeros(1)生成一个形状为(1,)的张量,所有元素初始值为0。
初始化模型

定义损失函数和优化算法
3.训练模型
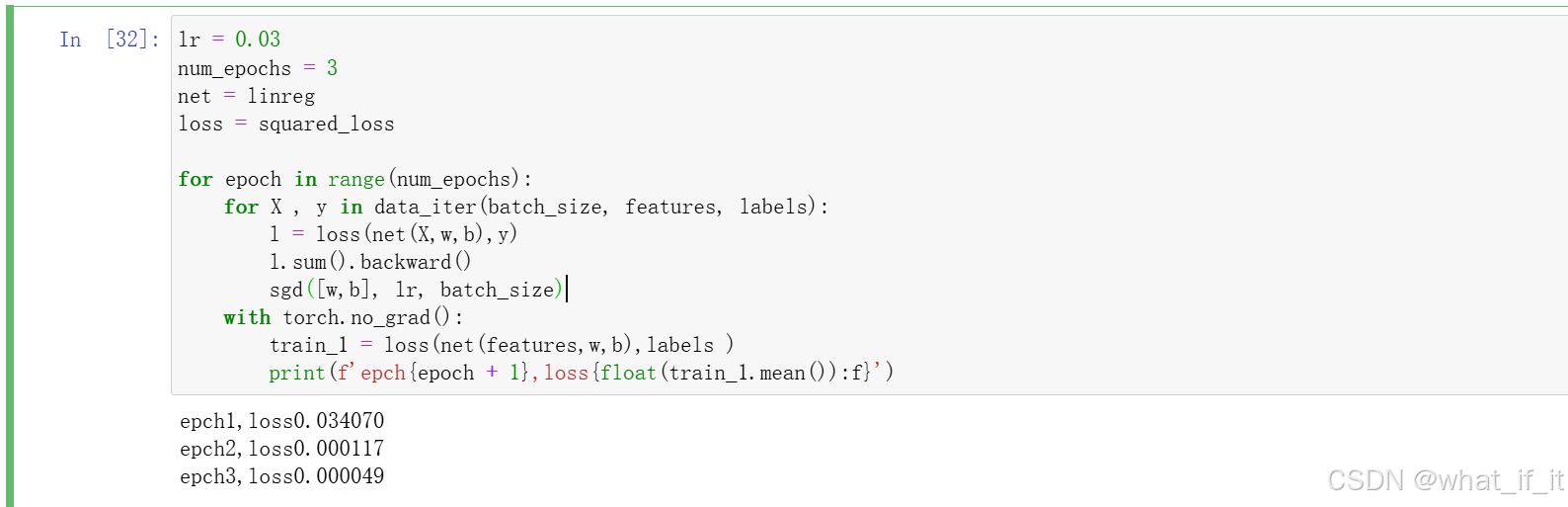
调用api快速实现线性回归
1.生成数据集

2.构造数据迭代器
也就是小批量取数据

3.使用神经网络的线性层

(nn.Linear(2,1)) : 输入2维,输出1维
4.初始化模型参数

5.调用损失函数与随机梯度下降优化方法

6.训练模型



















 436
436

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









