




 本文解析Python中的字符串驻留(interning)机制,包括小整数池、自动驻留规则、场景分析、常量折叠与AST优化,以及实战示例,帮助理解内存节省与比较效率提升背后的原理。
本文解析Python中的字符串驻留(interning)机制,包括小整数池、自动驻留规则、场景分析、常量折叠与AST优化,以及实战示例,帮助理解内存节省与比较效率提升背后的原理。
本人Python能力有限,介意请直接看参考文档,所以我把参考文档(筛选后的)写在了前面。本文主要是根据自己在学习intern机制时参看一些文档和相关Python的理解总结而成,因为网上不同的文档内容参差不齐,避免大家走弯路。
参考文档:
1、https://medium.com/techtofreedom/string-interning-in-python-a-hidden-gem-that-makes-your-code-faster-9be71c7a5f3e
2、https://medium.com/@bdov_/https-medium-com-bdov-python-objects-part-iii-string-interning-625d3c7319de
3、https://segmentfault.com/a/1190000017217606
4、https://blog.youkuaiyun.com/qq_39478403/article/details/106201512
5、https://stackabuse.com/guide-to-string-interning-in-python/
6、https://zhuanlan.zhihu.com/p/351244769
7、https://www.code05.com/question/detail/55643933.html
intern,直接翻译是驻留等意思。在Python中比较为大家所熟知的是字符串驻留机制,也就是string interning.其实一般常见的小整数池也可以看成Interger interning.
1、小整数池/整数驻留
为避免因创建相同的值而频繁申请和回收内存空间带来的效率问题,Python 解释器会在启动时创建一个范围为 [-5, 256] 的 小整数池,该范围内预定义的“小”整数对象将在全局解释器范围内被重复使用,而不会被垃圾回收机制回收。
x = 256
y = 256
print(x is y)
x = -5
y = -5
print(x is y)
x = 257
y = 257
print(x is y)
----------------
True
True
False
2、字符串驻留/String Intern
怎么理解字符串驻留?直白的意思就是,有一部分字符串在内存中只会存一份,其他的相同值的字符串都是对它的引用。
怎么理解这种技术的产生?
众所周知,Python 字符串是不可变对象。当一个字符串被声明生成时,就无法在修改或者更新这个字符串了,那么在编码过程中经常会遇到多个变量赋予相同字符串值的情况,难道每次赋予一次都创建一个相同的字符串在内存中?显然不合适,于是就有了字符串驻留机制。
这样做有两个好处:
- 节省内存空间;
- 降低比较字符串的时间复杂度。
这两点都比较好理解,当相同的值的字符串都只有一份时,明显会降低空间。而在比较两个字符串是否相等的时候,如果两个字符串变量指向的是同一个内存地址,明显就是相等的。
当然,对应的就有缺点:
- 要实现字符串驻留,就得长时间保存这些字符串在内存中,因此会有一个字符串驻留池来保存这些字符串。
因此,为了降低字符串驻留的成本和开销,Python并不是把所有的字符串都自动驻留在内存里了。
2.1、自动驻留
自动驻留,就是字面意思,解释器自动驻留这些字符串在内存中。
哪些字符串会被自动驻留在内存着呢?
自动驻留的场景:
- 场景1:字符串必须是编译时就确定的常量,不能是运行时才计算出来的。常见的表达式、函数等都是运行时计算。
- 场景2:在Python 3.7为止,长度超过20个字符的字符串不会被驻留,之后得Python版本,通过语法解释器优化,可以支持最长4096字符长度的字符串驻留。这一点也是会引起困惑的地方,很多博客要么直接写的超过20个字符,有的要么写没有长度限制。
- 场景3:所有的ascll码字符、数字和下划线组成的字符串。
- 场景4:除了显式的自己命名的变量外,函数名、类名、变量、参数名等都会被驻留。(其实这些变量名的规范都符合场景3)。
- 场景5:所有字典的键,不仅包含显式定义的字典,还有类、模块还有实例变量属性等相关的字典。
- 场景6:特例:所有的空字符串。
其实场景(条件)很多,但是我觉得记住了解主要的几点就行,参考下面判断是否驻留的逻辑流程来理解我觉得不错:
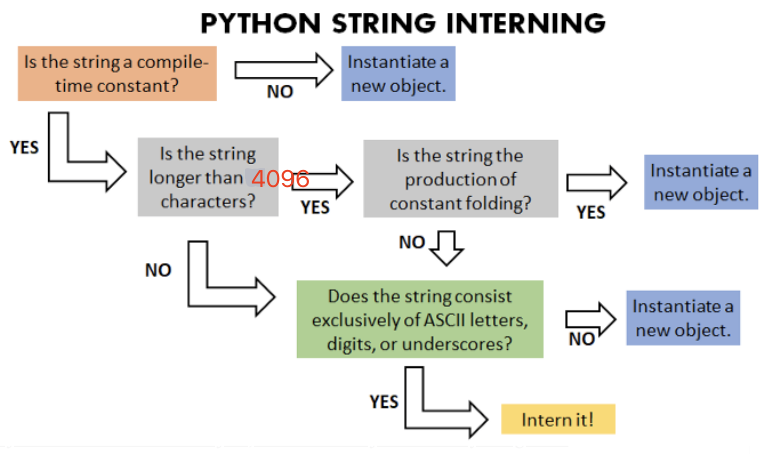
了解这个流程后,我们再来用几个实例来强化理解一下,看看和认知是否有差异。
# 场景1、运行时和编译时字符串
x = "a"*21
y = "a"*21
print(x is y)
# True
x = "Holberton" + "Holberton" + "Holberton"
y = "Holberton" + "Holberton" + "Holberton"
print(x is y)
# True
x = "a"*5
y = "".join("aaaaa")
print(x is y)
# False
# 场景2、4096的长度约束是否正确
x = "a"*4096
y = "a"*4096
print(x is y)
# True
x = "a"*4097
y = "a"*4097
print(x is y)
# False
# 其他
x = "abc!"
y = "abc!"
print(x is y)
# False
2.2、手动驻留
可以通过显式使用intern函数来驻留字符串。
import sys
x = sys.intern("abc!")
y = sys.intern("abc!")
print( x is y)
# True
3、几点例子的思考
3.1、常量折叠(Constant Folding)和字符串驻留
在上文自动触发字符串驻留的场景2中,对驻留的字符串长度扩展到4096,是因为解释器在编译的时候进行了AST optimizer (抽象语法树分析优化)。在这个优化中使用了一种常量折叠的技术:在编译期间,编译器会设法识别出常量表达式,对其进行求值,然后用求值的结果来替换表达式,从而使得运行时更精简。
在例子中代码即’a’*4096被编译时,interning发生。 通常,在编译时,这将导致以下字节码:
0 LOAD_CONST 1 ('a')
2 LOAD_CONST 2 (4096)
4 BINARY_MULTIPLY
但是,因为两者都是常量,所以在编译时可以通过peephole-optimizer为BINARY_MULTIPLY执行常量折叠,这发生在fold_binop:
static int
fold_binop(expr_ty node, PyArena *arena, int optimize)
{
...
PyObject *newval;
switch (node->v.BinOp.op) {
...
case Mult:
newval = safe_multiply(lv, rv);
break;
case Div:
...
}
return make_const(node, newval, arena);
}
如果可以计算safe_multiply,则结果被添加到make_const中的常量列表中,如果safe_multiply返回NULL,则不会发生任何事情-无法执行优化。
safe_multiply仅在生成的字符串不大于4096个字符时执行:
#define MAX_STR_SIZE 4096 /* characters */
static PyObject *
safe_multiply(PyObject *v, PyObject *w)
{
...
else if (PyLong_Check(v) && (PyUnicode_Check(w) || PyBytes_Check(w))) {
Py_ssize_t size = PyUnicode_Check(w) ? PyUnicode_GET_LENGTH(w) :
PyBytes_GET_SIZE(w);
if (size) {
long n = PyLong_AsLong(v);
if (n < 0 || n > MAX_STR_SIZE / size) { //HERE IS THE CHECK!
return NULL;
}
}
}
...
}
因此’a’*4096成为interned,‘a’*4097不是,对于第一种情况,优化的字节代码现在是:
0 LOAD_CONST 3 ('aaaaaaaaa...aaaaaaaaaaa')
整个优化代码可以查看CPython的源码中的ast_opt.c文件。
https://github.com/python/cpython/blob/3.7/Python/ast_opt.c
Python3.7之前的20的限制参看https://github.com/python/cpython/blob/0f21fe6155227d11dc02bd3ef3b061de4ecea445/Python/peephole.c。
3.2、查看下面代码和返回结果
a = 'asd!'
b = 'asd!'
print(a is b)
# False
def foo():
a = 'asd!'
b = 'asd!'
print(a is b)
foo()
# True
根据上面代码的输出,是否会觉得intern机制是不是有问题了?这里面其实涉及到一个问题:python交互式逐行解释和整体解释(脚本或者函数、类等)是否有啥不一样?
这个和CPython解释器中设定的编译单元相关。
整体解释中的函数、模块都会算一个编译单元,每个函数独编译,得到的结果是一个PyFunctionObject对象,其中带有字节码、常量池等各种信息。
dis(foo)
7 0 LOAD_CONST 1 ('asd!')
2 STORE_FAST 0 (a)
8 4 LOAD_CONST 1 ('asd!')
6 STORE_FAST 1 (b)
9 8 LOAD_GLOBAL 0 (print)
10 LOAD_FAST 0 (a)
12 LOAD_FAST 1 (b)
14 COMPARE_OP 8 (is)
16 CALL_FUNCTION 1
18 POP_TOP
20 LOAD_CONST 0 (None)
22 RETURN_VALUE
查看上面foo函数的字节码,会发现变量a和b都是从常量池里获得LOAD_CONST 1。
每个PyFunctionObject有一个独立的常量池;换句话说,每个PyFunctionObject的co_const字段都指向自己专有的一个常量池对象,而里面的常量池项也是自己专有的。在同一个编译单元(PyFunctionObject)里出现的值相同的常量,只会在常量池里出现一份,一定会对应到运行时的同一个对象。所以在foo()的例子里,a和b都从同一个常量池项获取值;
在不同的编译单元里,值相同的常量不一定会对应到运行时的同一个对象,要看具体的类型是否自带了某种interning / caching机制。
而逐行解释实际上每行都是一个编译单元,因此会应用实际的intern机制来判断。
4、总结与思考
intern机制时Python解释器的一个设计的巧思。在学习的过程中,会发现单纯简单的从intern来解释其实很多地方是解释不通的。
例如为啥之前是限定20个字符,现在变成了4096,实际上是AST optimizer在起作用。
很多时候看到的一个结果,可能是多个机制或者优化手段达成的,这也为我们学习Python提高了难度,也是学习的乐趣所在。由于本人C语言能力有限,很多底层的原理和机制都是参考学习。

















 8万+
8万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









