使用BeautifulSoup 以抓取彩票往期数据为例
导入模块
安装模块 pip install bs4
导入 from bs4 import BeautifulSoup
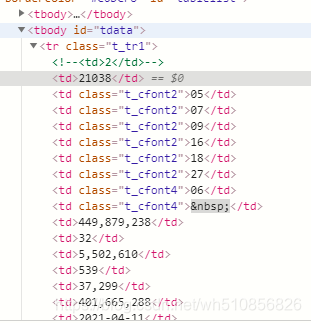
data = requests.get('http://datachart.500.com/ssq/history/newinc/history.php?limit=200&sort=0')
html = BeautifulSoup(data.text,'html.parser')
list =[]
for tag in html.find_all('tr',class_='t_tr1'):
qihao = tag.find('td').get_text()
honqiu = ''
for haoma in tag.find_all('td',class_='t_cfont2'):
honqiu += haoma.get_text()+','
honqiu = honqiu[0:-1:]
lanqiu = tag.find('td',class_='t_cfont4').get_text()
list.append(Haoma(qihao=qihao,number=honqiu,lan=lanqiu))
Haoma.objects.bulk_create(list)
数据量大的时候,两种写入方式较为明显








 该博客介绍了如何利用BeautifulSoup库从指定网址抓取彩票历史数据,包括期号、红球号码和篮球号码,并将数据存储到数据库中。通过批量插入的方式提高了数据处理效率,适合大数据量的情况。
该博客介绍了如何利用BeautifulSoup库从指定网址抓取彩票历史数据,包括期号、红球号码和篮球号码,并将数据存储到数据库中。通过批量插入的方式提高了数据处理效率,适合大数据量的情况。

















 1307
1307

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









