







 本文介绍了强化学习的基本概念,包括其在机器学习中的位置,与监督学习、非监督学习的区别。通过强化学习的建模,阐述了环境状态、个体动作、奖励、策略、价值函数、奖励衰减因子等要素,并提供了一个简单的Tic-Tac-Toe游戏实例作为强化学习应用的展示。
本文介绍了强化学习的基本概念,包括其在机器学习中的位置,与监督学习、非监督学习的区别。通过强化学习的建模,阐述了环境状态、个体动作、奖励、策略、价值函数、奖励衰减因子等要素,并提供了一个简单的Tic-Tac-Toe游戏实例作为强化学习应用的展示。
从今天开始整理强化学习领域的知识,主要参考的资料是Sutton的强化学习书和UCL强化学习的课程。这个系列大概准备写10到20篇,希望写完后自己的强化学习碎片化知识可以得到融会贯通,也希望可以帮到更多的人,毕竟目前系统的讲解强化学习的中文资料不太多。
第一篇会从强化学习的基本概念讲起,对应Sutton书的第一章和UCL课程的第一讲。
1. 强化学习在机器学习中的位置
强化学习的学习思路和人比较类似,是在实践中学习,比如学习走路,如果摔倒了,那么我们大脑后面会给一个负面的奖励值,说明走的姿势不好。然后我们从摔倒状态中爬起来,如果后面正常走了一步,那么大脑会给一个正面的奖励值,我们会知道这是一个好的走路姿势。那么这个过程和之前讲的机器学习方法有什么区别呢?
强化学习是和监督学习,非监督学习并列的第三种机器学习方法,从下图我们可以看出来。
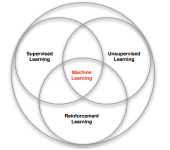
强化学习来和监督学习最大的区别是它是没有监督学习已经准备好的训练数据输出值的。强化学习只有奖励值,但是这个奖励值和监督学习的输出值不一样,它不是事先给出的,而是延后给出的,比如上面的例子里走路摔倒了才得到大脑的奖励值。同时,强化学习的每一步与时间顺序前后关系紧密。而监督学习的训练数据之间一般都是独立的,没有这种前后的依赖关系。
再来看看强化学习和非监督学习的区别。也还是在奖励值这个地方。非监督学习是没有输出值也没

 订阅专栏 解锁全文
订阅专栏 解锁全文


















 4178
4178

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











