



 本文指导如何在Ubuntu20.04上安装TVM,配置CUDA环境,并部署ONNX模型进行推理,包括CMAKE和LLVM的安装步骤。
本文指导如何在Ubuntu20.04上安装TVM,配置CUDA环境,并部署ONNX模型进行推理,包括CMAKE和LLVM的安装步骤。
跑深度学习实验需要用到tvm框架进行推理加速,而tvm安装过程比较繁琐,成功在ubuntu22.04系统跑通后这次又在ubuntu20.04上面成功安装了,把整个流程记录一下方便后面安装。
需要注意的是,该教程仅针对linux系统,windows系统还没有装过,后续踩坑之后再出新的教程。另外如果要在gpu上面运行需要提前编译并安装好cuda
tvm安装及基于cuda进行onnx模型部署推理
一、安装CMAKE
首先tvm编译需要cmake 3.18以上,通过cmake --version查看版本号,如果在3.18以下需要卸载重装
1. 卸载
sudo apt remove --purge cmake
hash -r
2. 安装
首先去官网下载源码,上传到服务器

解压,并安装
tar -zxvf cmake-3.28.0.tar.gz
cd cmake-3.28.0
./bootstrap
make
sudo make install
cmake --version #验证安装版本
3. 安装时可能遇到的问题
(1) ./bootstrap的时候报错
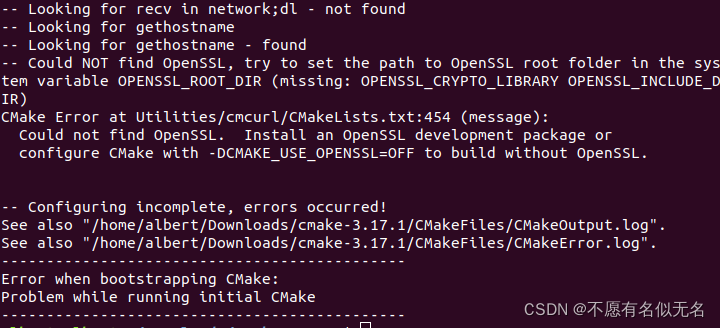
解决办法: 执行下面命令
sudo apt-get install libssl-dev
(2) 执行cmake --version报错 -bash: /usr/bin/cmake: No such file or directory
这个可能是由于我之前的cmake版本没卸载干净所以遇到的问题,首先查看cmake是否安装成功
which cmake
# /usr/local/bin/cmake
已经安装成功,只是在/usr/bin下面找不到cmake,于是添加软连接
sudo ln -s /usr/local/bin/cmake /usr/bin/cmake
此时再执行cmake --version

不报错就说明安装成功了,如果安装中出现其他问题可以再百度查查
二、安装llvm
tvm官方文档中提到,推荐使用 LLVM 进行构建,而且llvm的安装也比较简单,只需要下载和系统对应的版本的源码并且添加到环境变量就可以了。
1.下载源码
首先查看系统版本号
uname -a


我的两台服务器分别是ubuntu 22.04和20.04,根据系统版本号去llvm官网下载对应的源码。


官网有很多下载版本,每个版本有什么区别我也不太清楚,我用的是下面这个
clang+llvm-13.0.0-x86_64-linux-gnu-ubuntu-20.04.tar.xz
2.解压
把源码上传到服务器上,解压,我习惯放到/usr/local下面
# 先解压第一层压缩,执行命令后生成.tar文件
xz -d clang+llvm-13.0.0-x86_64-linux-gnu-ubuntu-20.04.tar.xz
# 解压tar文件
tar -xvf clang+llvm-13.0.0-x86_64-linux-gnu-ubuntu-20.04.tar
# 修改文件名
mv clang+llvm-13.0.0-x86_64-linux-gnu-ubuntu-20.04 /usr/local/llvm13
3.配置环境变量
sudo vim /etc/profile
把这两行添加到文件末尾
export LLVM_HOME=/usr/local/llvm13/bin # 根据自己的源码路径修改
export PATH=$LLVM_HOME:$PATH
验证是否安装成功
llvm-as --version
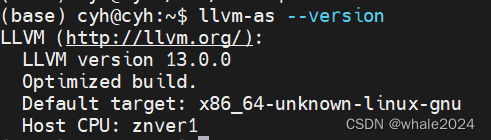
如果没有出现版本号的话重启或者source /etc/profile重新激活环境变量,我好像没有重启也可以。
另外这个环境配置到~/.bashrc里面应该也可以,因为我想让服务器上面的所有用户都能使用llvm所以就配置成全局环境变量了,通过echo $PATH也可以查看当前环境变量。
三、编译tvm
安装好llvm之后,tvm的编译也不算复杂,根据官方文档操作就可以了,下面是详细步骤
1. 从 Github 获取源代码
git clone --recursive https://github.com/apache/tvm tvm
这里一定要使用–recursive,因为tvm源码中包含了第三方库,直接在github网站download的话是不包含这些外链的第三方库的,我看有的教程里面写可以自己手动下载这些第三方库,但是一个是比较麻烦,另一个有点费劲,所以最方便的办法就是直接git clone --recursive,会自动下载好这些外链的库。
如果GitHub被墙了,下载不成功的话也可以用我之前下载的版本,亲测可以用。
百度网盘链接:https://pan.baidu.com/s/1ts-c5nyKX4n6kva0s7LV7Q?pwd=3E47
提取码:3E47
2.安装一些必须的包
sudo apt-get update
sudo apt-get install -y python3 python3-dev python3-setuptools gcc libtinfo-dev zlib1g-dev build-essential cmake libedit-dev libxml2-dev
更新apt的时候可能会报错,可以看一下这篇文章,通过换源的方式来解决
3.编辑config.cmake配置文件
官方的tvm下面没有build文件夹,需要创建一个build,然后把config文件拷贝到build下面
mkdir build
cp cmake/config.cmake build
然后需要对这个config.make文件进行修改
set(USE_LLVM OFF)
改为:
set(USE_LLVM ON) 或者 SET(USE_LLVM /usr/local/llvm13/bin/llvm-config)
set(USE_CUDA OFF)
改为:
set(USE_CUDA ON) 或者 SET(USE_CUDA /cuda的路径)
set(USE_CUDNN OFF) 改为:set(USE_CUDNN ON)
set(USE_GRAPH_EXECUTOR OFF) 改为:set(USE_GRAPH_EXECUTOR ON)
set(USE_PROFILER OFF) 改为:set(USE_PROFILER ON)
如果有其他要修改的可以参考官方文档,我上传到百度云的文件夹中已经包含了build和修改后的config文件,只需要改一下llvm路径即可。
4.编译tvm
进入build路径,执行下面命令
cd build
cmake ..
make -j4
没有报错就说明编译成功
5.配置环境变量
vim ~/.bashrc
# 文件末尾添加这几行
export TVM_HOME=/home/cyh/package/tvm
export PYTHONPATH=$TVM_HOME/python:$TVM_HOME/python/tvm:$TVM_HOME/build:$TVM_HOME/python/tvm/runtime:$[PYTHONPATH]
保存后,执行python,检查tvm是否安装成功
import tvm
tvm.__version__

6.可能需要的操作
把build下面的libtvm.so 和 libtvm_runtime.so拷贝到/usr/local/sbin/下面,不过好像不拷贝也不影响
sudo cp build/libtvm.so /usr/local/sbin/
sudo cp libtvm_runtime.so /usr/local/sbin/
四、基于tvm对onnx模型进行部署(python代码)
之所以安装tvm,主要是因为pytorch训练好的模型转换成onnx格式之后,用tvm进行推理加速,附上对转换后的onnx代码进行推理的python代码
用Relay编译模型
切换到不同服务器都需要对onnx文件进行重新编译,编译完成后会在该onnx同级路径下生成.so .params .json文件
import onnx
import tvm
import tvm.relay as relay
def model_info(model_path):
model = onnx.load(model_path)
input_names = []
output_names = []
for output in model.graph.output:
output_names.append(output.name)
weight_name = []
for weight in model.graph.initializer:
weight_name.append(weight.name)
for i, input in enumerate(model.graph.input):
if input.name in weight_name:
continue
input_names.append(input.name)
return input_names, output_names
def build_models(model_path, input_names, input_shapes, target, target_host):
lib_file = model_path.replace('.onnx', '.so')
json_file = model_path.replace('.onnx', '.json')
params_file = model_path.replace('.onnx', '.params')
print(input_names)
onnx_model = onnx.load(model_path)
shapes = {i: d for i, d in zip(input_names, input_shapes)}
mod, params = relay.frontend.from_onnx(
onnx_model, shape=shapes)
print("relay.frontend.from_onnx is sunccess")
with relay.build_config(opt_level=3):
graph, lib, params = relay.build(mod,
target=target,
#target_host=target_host,
params=params)
print("relay.build is sunccess")
lib.export_library(lib_file)
with open(json_file, "w") as fo:
fo.write(graph)
with open(params_file, "wb") as fo:
fo.write(tvm.runtime.save_param_dict(params))
return graph, lib, params
if __name__ == '__main__':
# 模型存放路径,编译完成后会在该onnx同级路径下生成.so .params .json文件
model_path = 'onnx/best.onnx'
# onnx图片输入大小,可以在这个网站看https://netron.app/
input_shape = [1, 3, 640, 640]
print("model path: ", model_path)
input_names, output_names = model_info(model_path)
#target = f'xpu -libs=xdnn -split-device-funcs -device-type=xpu{os.environ.get("XPUSIM_DEVICE_MODEL", "KUNLUN2")[-1]}'
target = tvm.target.cuda(0)
target_host = 'llvm'
check_ret = []
perf_ret = []
print("------------- ", input_shape, " --------------")
graph, lib, params = build_models(model_path, input_names, [input_shape], target, target_host)
在tvm执行模型推理
import tvm
from tvm import relay
import onnx
import time
import cv2
import numpy as np
# onnx路径,需要在同级路径下保存.so .json .params文件,即编译过的onnx文件
model_path = 'onnx/pose.onnx'
# 任意图片,用于测试模型是否编译成功
img_path = 'img.jpg'
# onnx输入图片尺寸
resized = (256, 256)
lib_file = model_path.replace('.onnx', '.so')
json_file = model_path.replace('.onnx', '.json')
params_file = model_path.replace('.onnx', '.params')
lib = tvm.runtime.load_module(lib_file)
graph = open(json_file).read()
file_data = bytearray(open(params_file, "rb").read())
params = tvm.runtime.load_param_dict(file_data)
target = 'cuda'
#target = tvm.target.cuda()
ctx = tvm.device(target, 0) #0对应第0号显卡
module = tvm.contrib.graph_executor.create(graph, lib, ctx)
module.load_params(relay.save_param_dict(params))
model = onnx.load(model_path)
input_names = []
output_names = []
for output in model.graph.output:
output_names.append(output.name)
weight_name = []
for weight in model.graph.initializer:
weight_name.append(weight.name)
for i, input in enumerate(model.graph.input):
if input.name in weight_name:
continue
input_names.append(input.name)
img = cv2.imread(img_path)
input_height, input_width = resized
img_bgr_640 = cv2.resize(img, [input_height, input_width])
img_rgb_640 = img_bgr_640[:,:,::-1]
# 预处理-归一化
input_tensor = img_rgb_640 / 255
# 预处理-构造输入 Tensor
input_tensor = np.expand_dims(input_tensor, axis=0) # 加 batch 维度
input_tensor = input_tensor.transpose((0, 3, 1, 2)) # N, C, H, W
input_tensor = np.ascontiguousarray(input_tensor).astype(np.float32)
module.set_input(input_names[0], input_tensor)
print('===========')
start = time.time()
module.run()
end = time.time()
output = []
for j in range(module.get_num_outputs()):
output.append(module.get_output(j).asnumpy())
print(output)
print(end - start)
如果能够打印结果说明tvm安装成功并且能够执行推理


















 2494
2494





 到【灌水乐园】发言
到【灌水乐园】发言







