






 本文详细介绍了Elasticsearch的Java低级和高级REST客户端,包括它们的功能、特性及Maven依赖配置。同时,提供了配置示例和代码参考,帮助开发者更好地理解和使用这些客户端。
本文详细介绍了Elasticsearch的Java低级和高级REST客户端,包括它们的功能、特性及Maven依赖配置。同时,提供了配置示例和代码参考,帮助开发者更好地理解和使用这些客户端。
介绍
ElasticSearch 是一个分布式、高扩展、高实时的搜索与数据分析引擎。它能很方便的使大量数据具有搜索、分析和探索的能力。充分利用ElasticSearch的水平伸缩性,能使数据在生产环境变得更有价值。ElasticSearch 的实现原理主要分为以下几个步骤,首先用户将数据提交到Elastic Search 数据库中,再通过分词控制器去将对应的语句分词,将其权重和分词结果一并存入数据,当用户搜索数据时候,再根据权重将结果排名,打分,再将返回结果呈现给用户。
Elasticsearch是与名为Logstash的数据收集和日志解析引擎以及名为Kibana的分析和可视化平台一起开发的。这三个产品被设计成一个集成解决方案,称为“Elastic Stack”(以前称为“ELK stack”)。
Elasticsearch可以用于搜索各种文档。它提供可扩展的搜索,具有接近实时的搜索,并支持多租户。”Elasticsearch是分布式的,这意味着索引可以被分成分片,每个分片可以有0个或多个副本。每个节点托管一个或多个分片,并充当协调器将操作委托给正确的分片。再平衡和路由是自动完成的。“相关数据通常存储在同一个索引中,该索引由一个或多个主分片和零个或多个复制分片组成。一旦创建了索引,就不能更改主分片的数量。
Elasticsearch使用Lucene,并试图通过JSON和Java API提供其所有特性。它支持facetting和percolating,如果新文档与注册查询匹配,这对于通知非常有用。另一个特性称为“网关”,处理索引的长期持久性;例如,在服务器崩溃的情况下,可以从网关恢复索引。Elasticsearch支持实时GET请求,适合作为NoSQL数据存储,但缺少分布式事务。
ES 2.x版本
优点:
- Java技术栈, spring-boot-starter-data-elasticsearch 支持in-memory方式启动,单元测试开箱即用
- 当前线上运行的主流版本, 比较稳定
缺点: - 版本较老,无法体验新功能,且性能不如5.x
- 后期升级数据迁移比较麻烦
- 周边工具版本比较混乱;Kinbana等工具的对应版本需要自己查
ES 5.x版本
优点
6. 版本相对较新,性能较好官方宣称索引吞吐量提升在25%到80%之间,新的数据结构用于存储数值和地理位置字段,性能大幅提升;5.x版本搜索进行了重构,搜索聚合能力大幅提高
7. 周边工具比较全,版本号比较友好。 ES官方在5.x时代统一了 ELK体系的版本号
8. 升级到6.x也比较方便
缺点:
9. 官方宣布已不支持In-Memory模式和Node Client已失效, 如果需要使用in-memory方式单测,需要自己手动配置ES版本、spring-data-elasticsearch版本、打开http访问开关等配置,并行使用REST API访问
ES与Lucene
lucene,最先进、功能最强大的搜索库,直接基于lucene开发,非常复杂,api复杂(实现一些简单的功能,写大量的java代码),需要深入理解原理(各种索引结构)
elasticsearch,基于lucene,隐藏复杂性,提供简单易用的restful api接口、java api
总结
1、Solr 利用 Zookeeper 进行分布式管理,而Elasticsearch 自身带有分布式协调管理功能。
2、Solr 支持更多格式的数据,比如JSON、XML、CSV,而 Elasticsearch 仅支持json文件格式。
3、Solr 在传统的搜索应用中表现好于 Elasticsearch,但在处理实时搜索应用时效率明显低于 Elasticsearch。
4、Solr 是传统搜索应用的有力解决方案,但 Elasticsearch更适用于新兴的实时搜索应用
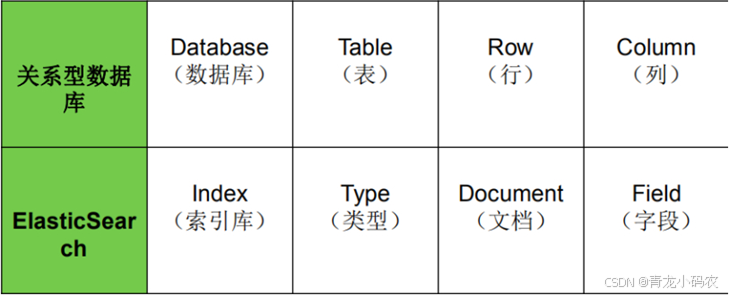
ES与关系型数据库
-------------------------------以下采用es6.x------------------------------------
集群配置
elasticsearch.yml 【更目录下的 config目录下】
核心配置项
#集群名称
cluster.name: my-application
#集群中节点名称 (3个节点以此为:node-1,node-2,node-3 )
node.name: node-1
#服务接口(本实例采用单机部署,每个节点端口都不一样)
http.port: 9201
transport.tcp.port: 9301
#节点信息
discovery.zen.ping.unicast.hosts: ["127.0.0.1:9301","127.0.0.1:9302","127.0.0.1:9303"]
# 安装head插件
【es5以上版本安装head需要安装node和grunt 】
在https://github.com/mobz/elasticsearch-head中下载head插件 解压到Elasticsearch根目录
进入head目录(建议:如果多节部署每个节点都安装,这样任意一个节点够可以访问,本本文是单机多实例,只在节点1上配置):
npm install -g grunt-cli
npm install
【修改配置 Gruntfile.js hostname 指定端口】

elasticsearch.yml 中配置跨域(如果不配置head插件无法正常访问):
#allow origin
http.cors.enabled: true
http.cors.allow-origin: "*"
安装完成后执行grunt server 或者npm run start 运行head插件(windows上启动脚本如下head.bat)
D:
cd D:\ToolsDev\elk\elasticsearch-6.5.4-1\elasticsearch-head-5.0.0
grunt server
以此启动各节点和head插件(访问 http://localhost:9100/)

集群健康值:
green
所有的主分片和副本分片都正常运行。
yellow
所有的主分片都正常运行,但不是所有的副本分片都正常运行。
red
有主分片没能正常运行。


# es授权用户访问 x-pack
一般情况下es只会放在内网使用,xpack意义不是很重要,如果在某些情况下需要放在内网使用时需要使用x-pack了, x-pack是收费产品,不建议使用,尽量吧es放在内网使用(理论上不应该放在外网)
【安装】
elasticsearch-plugin install x-pack
kibana-plugin install x-pack
logstash-plugin install x-pack
【删除】
----kibana-plugin remove x-pack
【配置】
默认情况下,所有X-Pack功能都被启用。
您可以启用或禁用特定的X-Pack功能elasticsearch.yml,kibana.yml以及logstash.yml 配置文件。
xpack.graph.enabled #设置为false禁用X-Pack图形功能。
xpack.ml.enabled #设置为false禁用X-Pack机器学习功能。
xpack.monitoring.enabled #设置为false禁用X-Pack监视功能。
xpack.reporting.enabled #设置为false禁用X-Pack报告功能。
xpack.security.enabled #设置为false禁用X-Pack安全功能。
xpack.watcher.enabled #设置false为禁用观察器。
{or}
action.auto_create_index: .security,.monitoring*,.watches,.triggered_watches,.watcher-history*,.ml*
# xpack head
http.cors.allow-headers: Authorization,X-Requested-With,Content-Length,Content-Type
【访问的时候需要加上: http://127.0.0.1:9100/?auth_user=elastic&auth_password=changeme 】
配置kibana
下载kibana解压,找到根目录下的 config 文件夹下的 kibana.yml ,修改配置如下

- **到目前为止(官方目前最新版本是6.4),官方的意思是:暂不支持连接多个es节点,也就是上面的配置文件中,只能填写一个地址。**官网提供的另外的解决方案:https://www.elastic.co/guide/en/kibana/6.4/production.html#load-balancing
大致意思是:
搭建一个只用来“协调”的es节点,让这个节点加入到es集群中,然后kibana连接这个“协调”节点,这个“协调”节点,不参加主节点选举,也不存储数据,只是用来处理传入的HTTP请求,并将操作重定向到集群中的其他es节点,然后收集并返回结果。这个“协调”节点本质上也起了一个负载均衡的作用。
安装xpack插件后,可以开启登录验证,如果密码配置如下:

配置完成可就可以启动,访问了:http://localhost:5601
基本概念
_index 文档在哪存放
_type 文档表示的对象类别
_id 文档唯一标识
Index API
# 创建索引(插入数据,没有索引会创建)
PUT twitter/_doc/1
{
"user" : "kimchy",
"post_date" : "2009-11-15T14:12:12",
"message" : "trying out Elasticsearch"
}

total-指示索引操作应在多个碎片副本(主碎片和副本碎片)上执行。
successful-指示索引操作成功执行的碎片复制数。
failed-如果索引操作在副本碎片上失败,则包含与复制相关错误的数组
# 允许创建 叫twitter,index10 没有其他的折射率匹配index1*,以及任何其他折射率匹配ind*。模式按照给定的顺序进行匹配
PUT _cluster/settings
{
"persistent": {
"action.auto_create_index": "twitter,index10,-index1*,+ind*"
}
}
# 不允许 自动创建索引
PUT _cluster/settings
{
"persistent": {
"action.auto_create_index": "false"
}
}
# 允许创建所有类型索引
PUT _cluster/settings
{
"persistent": {
"action.auto_create_index": "true"
}
}
Get API
# 根据id查询
GET twitter/_doc/1

Delete API
# 根据id删除
DELETE /twitter/_doc/1
# 根据查询条件删除
POST twitter/_delete_by_query
{
"query": {
"match": {
"user": "kimchy"
}
}
}

Bulk API
#多条命令一起执行
POST _bulk
{ "index" : { "_index" : "test", "_type" : "_doc", "_id" : "1" } }
{ "field1" : "value1" }
{ "delete" : { "_index" : "test", "_type" : "_doc", "_id" : "2" } }
{ "create" : { "_index" : "test", "_type" : "_doc", "_id" : "3" } }
{ "field1" : "value3" }
{ "update" : {"_id" : "1", "_type" : "_doc", "_index" : "test"} }
{ "doc" : {"field2" : "value2"} }
Update API
POST twitter/_doc/3/_update
{
"doc" : {
"user" : "liuli-new"
}
}

Reindex API
POST _reindex
{
"source": {
"index": "twitter"
},
"dest": {
"index": "new_twitter"
}
}
本文只是简单列举了几个例子,es的api文档很多,可根据自己的需要参考官方文档学习

参考文档:
https://www.elastic.co/guide/en/elasticsearch/reference/6.5/docs.html
客户端连接
Java API
在ES 7.0之前最常采用的API,基于TransportClient客户端。网上大部分ES 客户端的资料基本都是基于它的。这种方式在ES 7.x后已经不被官方推荐,且在8.0版本中完全移除它。
Java REST Client(推荐)
Java Low Level REST Client
官方提供的低级客户端。该客户端通过http来连接Elasticsearch集群。用户在使用该客户端时需要将请求数据手动拼接成Elasticsearch所需JSON格式进行发送,收到响应时同样也需要将返回的JSON数据手动封装成对象。虽然麻烦,但是客户端兼容所有的Elasticsearch版本。低级客户端包含如下特性:
1.极少的依赖包
2.负载均衡访问所有可用节点
3.故障转移。当发生节点故障时会返回特定的状态码
4.连接失败处罚策略。(客户端是否会去重连一个连接失败的节点取决于该节点连续连接失败的次数,连接该节点失败次数越多,客户端下次重连它的时间就越长)
5.持久连接
6.跟踪记录请求和响应日志
7.可选的集群节点自动发现
Java High Level REST Client
官方提供的高级客户端。该客户端基于低级客户端实现,它提供了很多便捷的API来解决低级客户端需要手动转换数据格式的问题(也就是说高级客户端,无需关系请求和响应数据转换的问题)

















 1873
1873



 到【灌水乐园】发言
到【灌水乐园】发言








