







介绍
Zookeeper 是一个开源的分布式协调服务【Google Chubby的开源实现】,提供了一个类型linux文件系统的树形结构,同时提供对每个节点的监控与通知机制。【是一个用于存储少量数据的基于内存的数据库,主要有如下两个核心的概念:文件系统数据结构+监听通知机制】。ZooKeeper 可以用于实现分布式系统中常见的发布/订阅、负载均衡、命令服务、分布式协调/通知、集群管理、Master 选举、分布式锁和分布式队列等功能。
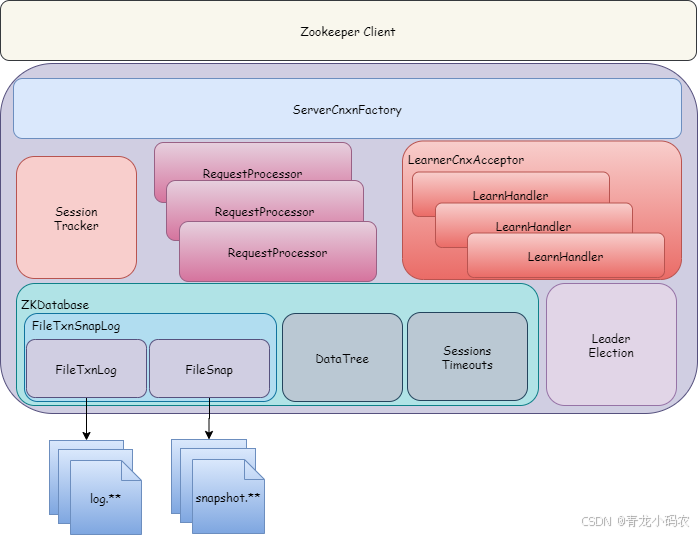
- ServerCnxnFactory
向外暴露TCP长链接,维护双向链接通道,分发请求。
- LearnerCnxAcceptor
Leader服务Socket服务端,接收Follower、Observer服务的创建链接请求,创建LearnerHandler,用于内部数据交互。
- FastLeaderElection
Leader内部选举,为避免双方重复创建链接,由myid大的向myid小的创建链接
- SessionTracker
会话管理及独立线程会话超时清理
- ZKDatabase
ZooKeeper的内存数据库,负责管理DataTree、事务日志,启动时从事务日志和快照中恢复到该内存数据库,运行期,将接收到的事务请求写入事务日志,当触发快照操作时,提供数据。
数据模型
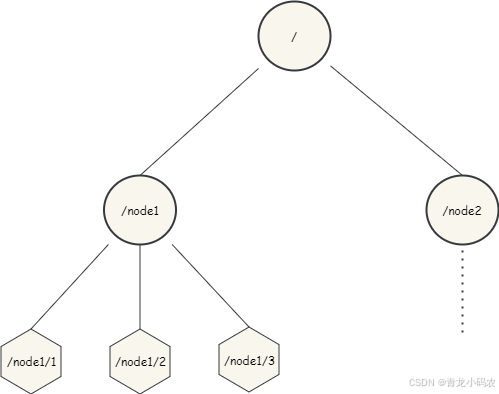
ZooKeeper 的数据节点可以视为树状结构,树中的各节点被称为 Znode,一个 Znode 可以有多个子节点,ZooKeeper 中的所有存储的数据是由 znode 组成,并以 key/value 形式存储数据。整体结构类似于 linux 文件系统的模式以树形结构存储,其中根路径以 / 开头
数据节点类型
- 持久节点【PERSISTENT】
数据节点被创建后,就会一直存在ZooKeeper服务器上,直到有删除操作主动清除节点数据。(默认创建)
- 持久顺序节点【PERSISTENT_SEQUENTIAL】
在持久性的基础上,又具有了顺序性特性。每个父节点都会为它的第一级子节点维护一份顺序,用于记录每个子节点的先后顺序。在创建子节点过程中,ZooKeeper会自动为给定的节点名加上一个数字后缀。适用于分布式锁、分部署选择等场景
- 临时节点【EPHEMERAL】
临时节点的生命周期和客户端的会话绑定在一起,如果客户端会话失效,该会话对应的临时节点就会被自动清理。临时节点不能创建子节点。
- 临时顺序节点【EPHEMERAL_SEQUENTIAL】
在临时节点的特性上,添加了顺序性特点。适用于心跳、服务发现等场景
- Container 节点
3 .5.3 版本新增,如果Container节点下面没有子节点,则Container节点在未来会被Zookeeper自动清除,定时任务默认60s 检查一次
集群安装
Zookeeper 3.5.0 以前,Zookeeper集群角色要发生改变的话,只能通过停掉所有的Zookeeper服务,修改集群配置,重启服务来完成,这样集群服务将有一段不可用的状态,为了应对高可用需求,Zookeeper 3.5.0 提供了支持动态扩容/缩容的 新特性。但是通过客户端API可以变更服务端集群状态是件很危险的事情,所以在zookeeper 3.5.3 版本要用动态配置,需要开启超级管理员身份验证模式 ACLs。如果是在一个安全的环境也可以通过配置 系统参数 -Dzookeeper.skipACL=yes 来避免配置维护acl 权限配置。
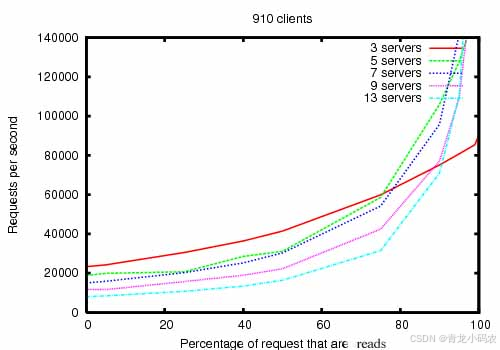
竖轴是每秒请求量,横轴是读请求的占比,不同颜色的曲线代表了不同数量的zookeeper节点,分别是3个节点,5个节点,7个节点,9个节点,13个节点。
随着读请求所占的比例越来越多,zookeeper所能处理的请求数量是指数级得提升。除了三个节点的zookeeper集群外,当读请求占比达到100%时,从曲线上看其他数量的集群能够处理的请求几乎无穷大。
当读请求达到80%时,由于follower数量的增大导致写请求的耗时增长,节点数量越多的zookeeper吞吐量越小(三个节点的集群是个例外)。吞吐量排序是:5>7>3>9>13。
正常情况下所有的请求都是读请求是不可能的,肯定含有写请求。所以建议zookeeper集群的读写比例为7:3或8:2最好,机器数量为5或者7台,不仅成本低也有良好的性能表现。
下载
http://mirror.bit.edu.cn/apache/zookeeper/
1.修改conf目录下的 zoo_sample.cfg --》zoo.cfg 修改配置(如下):

2.在上面规划的dataDir目录下创建名为myid的文件(备注:无扩展名)里面写入server.id值

按上述步骤,修改节点2、3 【clientPort 也要修改】
3. 执行 bin\zkServer.cmd 依次启动三个节点
4. 通过管理工具管理(zktools)zk,【类似的管理工具很多…】

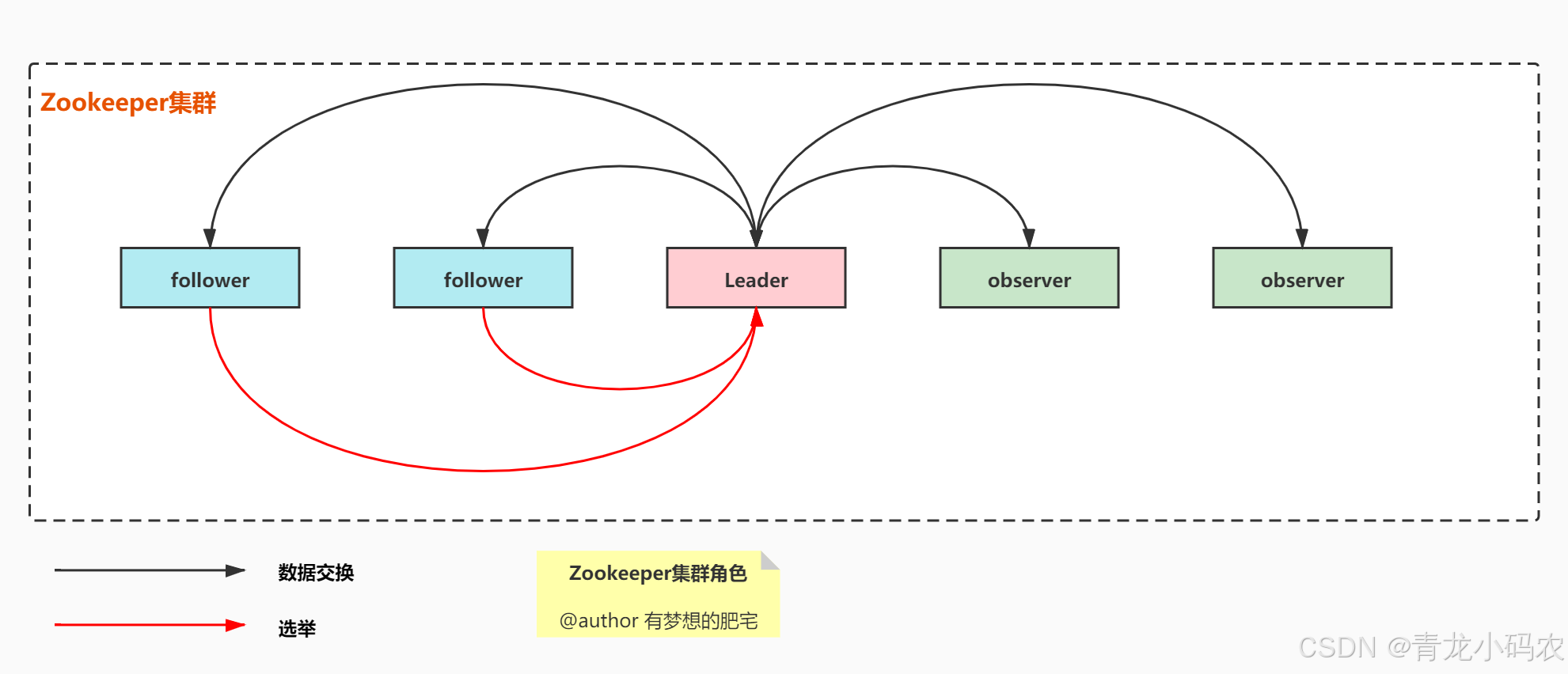
集群角色
#participant 可以不用写,默认就是participant
server.1=127.0.0.1:2001:3001:participant
#observer配置:只要在集群配置中加上observer后缀即可,示例如下:
server.3=127.0.0.1:2889:3889:observer
| 角色 | 描述 |
|---|---|
| Leader 领导者 | 集群中最重要的角色。负责响应集群的所有对Zookeeper数据状态变更的请求。它会将每个状态更新请求进行顺序管理,以便保证整个集群内部消息处理的 FIFO,遵循了顺序一致性(Sequential Consistency) |
| Follower 跟随者 | 具有选举权。负责提供给客户端读写服务,需要响应leader的提议 |
| Observer观察者 | 没有选举权。主要提供给客户端读服务,不提供写服务,也不需要响应leader的提议。也不需要日志文件,因为没有写服务,没有持久化的需要。 |
选举流程
第一次启动
(1)服务器1启动并发起一次选举。服务器1投自己一票,此时服务器1票数一票,不够半数以上(3票),则选举无法完成,服务器1状态保持为LOOKING。
(2)服务器2启动,再发起一次选举。服务器1和2分别投自己一票并交换选票信息
服务器1发现服务器2的myid比自己目前投票推举的(服务器1) 大,更改选票为推举服务器2。
此时服务器1票数0票,服务器2票数2票,没有超过半数,选举无法完成,服务器1,2状态保持LOOKING。
(3)服务器3启动,发起一次选举。此时服务器1和2都会更改选票为服务器3。
服务器1为0票,服务器2为0票,服务器3为3票。此时服务器3的票数已经超过半数,服务器3当选Leader。
服务器1,2更改状态为FOLLOWING,服务器3更改状态为LEADING。
(4)服务器4启动,发起一次选举。此时服务器1,2,3已经不是LOOKING状态,不会更改选票信息。
服务器3为3票,服务器4为1票。此时服务器4服从多数,更改选票信息为服务器3,并更改状态为FOLLOWING。
(5)服务器5启动,同4一样更新状态为FOLLOWING。
非第一次启动
(1)当ZooKeeper集群中的一台服务器出现以下两种情况之一时,就会开始进入Leader选举:
服务器初始化启动。
服务器运行期间无法和Leader保持连接。
(2)而当一台机器进入Leader选举流程时,当前集群也可能会处于以下两种状态:
集群中本来就已经存在一个Leader【由于网络波动导致的暂时失联,重选leader的场景】。
对于第一种已经存在Leader的情况,机器试图去选举Leader时,会被告知当前服务器的Leader信息,对于该机器来说,仅仅需要和Leader机器建立连接,并进行状态同步即可。
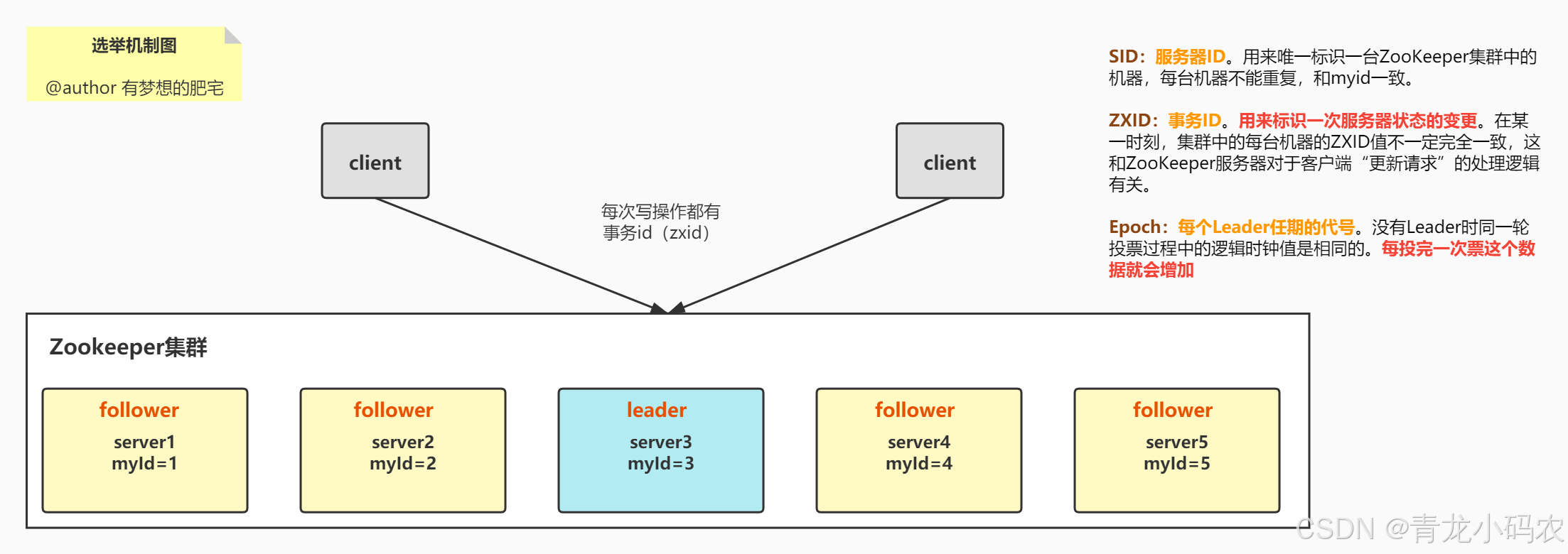
(3)集群中确实不存在Leader,则遵循以下原则进行选举:
1️⃣EPOCH大的直接胜出
2️⃣EPOCH相同,事务id大的胜出
3️⃣事务id相同,服务器id大的胜出
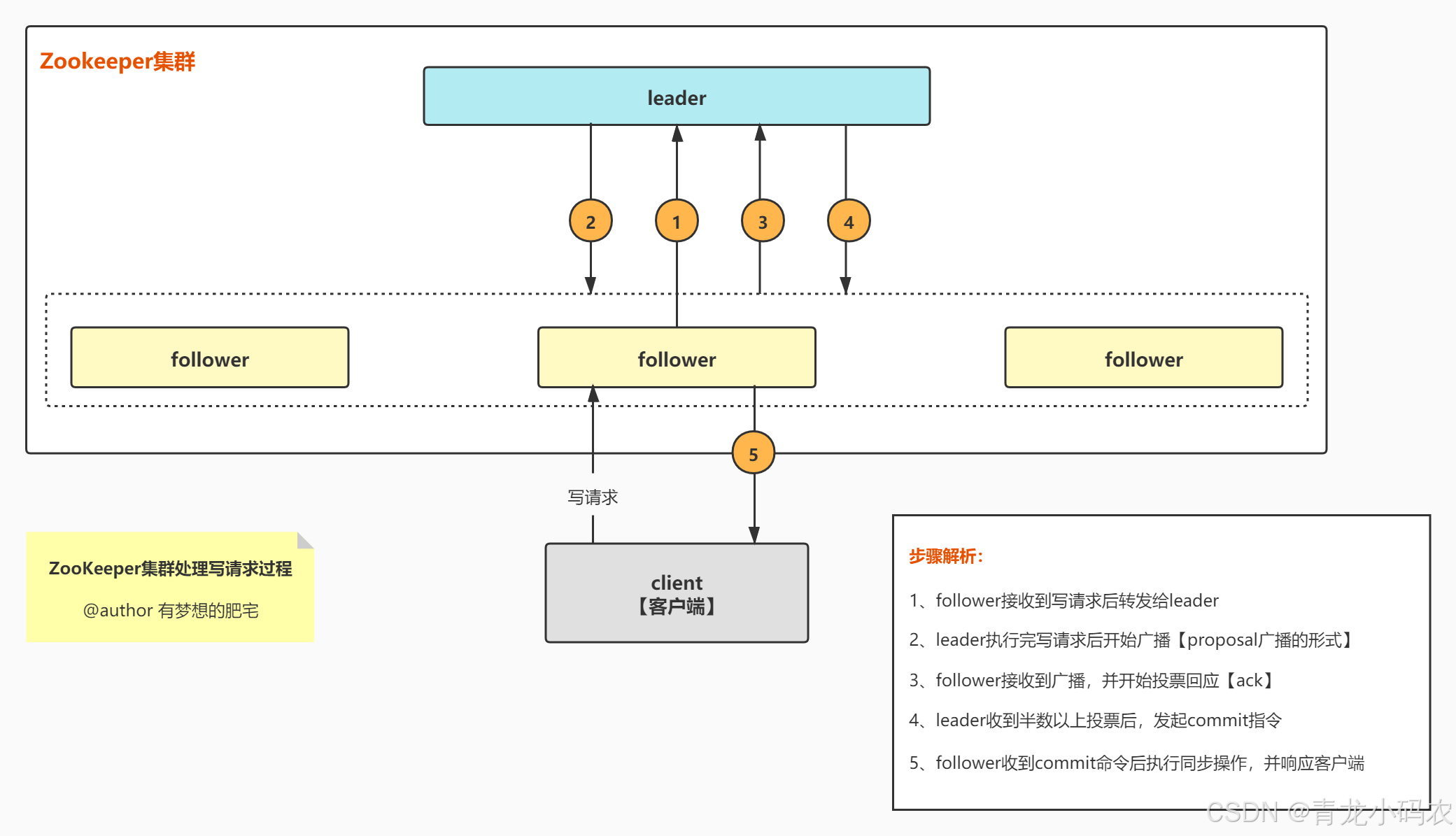
消息广播流程
1、收到写请求的follower,将写请求发送给leader。
2、leader收到来自follower(或observer)的写请求后,首先计算这次写操作之后的状态,然后将这个写请求转换成带有各种状态的事务(如版本号、zxid等等)。
3、leader将这个事务以提议的方式广播出去(即发送proposal)。
4、所有follower收到proposal后,对这个提议进行投票,投票完成后返回ack给leader。follower的投票只有两种方式:(1)确认这次提议表示同意(2)丢弃这次提议表示不同意。
5、leader收集投票结果,只要投票数量超过半数,这次提议就通过。
6、提议通过后,leader向所有server发送一个提交通知。
7、所有节点将这次事务写入事务日志,并进行提交。
8、提交后,收到写请求的那个server向客户端返回成功信息。
常用命令
help 显示所有操作命令
ls path 使用 ls 命令来查看当前 znode 的子节点 [可监听]
-w 监听子节点变化
-s 附加次级信息
create 普通创建
-s 含有序列
-e 临时(重启或者超时消失)
get path 获得节点的值 [可监听]
-w 监听节点内容变化
-s 附加次级信息
set 设置节点的具体值
stat 查看节点状态
-w 监听子节点变化
delete 删除节点
deleteall 递归删除节点
acl
权限模式种类
| 模式 | 描述 |
|---|---|
| world | 这种模式方法的授权对象只有一个anyone,代表登录到服务器的所有客户端都能对该节点执行某种权限 |
| ip | 对连接的客户端使用IP地址认证方式进行认证 |
| auth | 以添加认证的用户进行认证 |
| digest | 用户:密码方式验证 |
权限的类型
| 类型 | ACL简写 | 描述 |
|---|---|---|
| read | e | 读取节点及显示子节点列表的权限 |
| write | w | 设置节点数据的权限 |
| create | c | 创建子节点的权限 |
| delte | d | 删除子节点的权限 |
| admin | a | 设置该节点ACL权限的权限 |
授权的命令
| 命令 | 用法 | 描述 |
|---|---|---|
| getAcl | getAcl path | 读取节点的ACL |
| setAcl | setAcl path acl | 设置节点的ACL |
| create | create path data acl | 创建节点时设置acl |
| addAuth | addAuth scheme auth | 添加认证用户,类似于登录操作 |
使用场景
分布式配置管理
Zookeeper 提供了一个简单且强大的配置管理机制。在分布式系统中,多个服务可能需要共享一些配置参数(如数据库连接信息、文件路径等),Zookeeper 通过节点存储配置,并通过 Watcher 机制通知所有客户端当配置发生变更时及时更新。
实现步骤:
将配置存储在 Zookeeper 的某个 ZNode 下。
客户端使用 Watcher 监控配置节点的变化。
当配置发生变化时,客户端通过 Watcher 获取新配置并更新。
# 配置存储节点:
$ zkCli.sh
[zk: localhost:2181(CONNECTED) 0] create /config/db '{"host": "localhost", "port": 3306}'
#Java 客户端监控配置变化:
import org.apache.zookeeper.*;
public class ZookeeperConfigWatcher implements Watcher {
private static ZooKeeper zk;
private static String configPath = "/config/db";
public static void main(String[] args) throws Exception {
// 初始化Zookeeper客户端
zk = new ZooKeeper("localhost:2181", 3000, new ZookeeperConfigWatcher());
// 获取当前配置
String config = new String(zk.getData(configPath, true, null));
System.out.println("Current config: " + config);
// 在配置节点上设置Watcher监听配置变更
zk.exists(configPath, true);
// 保持程序运行,以便监听配置变化
Thread.sleep(Long.MAX_VALUE);
}
@Override
public void process(WatchedEvent event) {
if (event.getType() == Event.EventType.NodeDataChanged) {
try {
// 配置变更时读取新数据
String updatedConfig = new String(zk.getData(configPath, false, null));
System.out.println("Updated config: " + updatedConfig);
// 重新设置Watcher
zk.exists(configPath, true);
} catch (Exception e) {
e.printStackTrace();
}
}
}
}
使用说明:
上述代码会初始化一个 Zookeeper 客户端,连接到本地 Zookeeper 服务。
客户端读取 /config/db 路径下的配置信息,并设置 Watcher 监听该节点的变化。
当配置发生变化时,process 方法会被触发,客户端会自动获取新配置并更新。
分布式锁
Zookeeper 通过临时顺序节点可以实现分布式锁。临时顺序节点确保了在某个节点宕机后,其他节点能自动感知并重新争抢锁,避免了因节点宕机而导致的死锁情况。
实现步骤:
客户端创建一个临时顺序节点,节点名称中包含顺序编号。
客户端检查自己创建的节点是否是最小编号的节点。如果是,获取锁。
如果不是,客户端监视比自己编号小的节点,当它被删除时,客户端重新获取锁。
import org.apache.zookeeper.*;
import java.util.Collections;
import java.util.List;
public class ZookeeperDistributedLock {
private static ZooKeeper zk;
private static String lockPath = "/lock";
private static String currentNode;
public static void main(String[] args) throws Exception {
// 初始化Zookeeper客户端
zk = new ZooKeeper("localhost:2181", 3000, new Watcher() {
public void process(WatchedEvent event) {
// 处理Watcher事件
}
});
// 创建临时顺序节点
currentNode = zk.create(lockPath + "/lock-", new byte[0], ZooDefs.Ids.OPEN_ACL_UNSAFE, CreateMode.EPHEMERAL_SEQUENTIAL);
// 获取锁
getLock();
// 模拟持有锁的业务逻辑
Thread.sleep(5000);
// 释放锁
releaseLock();
}
private static void getLock() throws Exception {
// 获取锁路径下的所有子节点
List<String> children = zk.getChildren(lockPath, false);
Collections.sort(children); // 排序节点,最小的顺序节点获取锁
String firstNode = children.get(0);
if (currentNode.endsWith(firstNode)) {
System.out.println("Lock acquired!");
} else {
String prevNode = children.get(children.indexOf(currentNode.substring(lockPath.length())) - 1);
zk.exists(lockPath + "/" + prevNode, new Watcher() {
public void process(WatchedEvent event) {
if (event.getType() == Event.EventType.NodeDeleted) {
try {
getLock(); // 前一个节点被删除时,尝试重新获取锁
} catch (Exception e) {
e.printStackTrace();
}
}
}
});
}
}
private static void releaseLock() throws Exception {
zk.delete(currentNode, -1);
System.out.println("Lock released!");
}
}
使用说明:
客户端创建一个临时顺序节点,Zookeeper 会为每个客户端生成一个唯一的顺序节点名。
客户端获取锁时,会检查自己创建的节点是否是最小编号的节点。如果是,它就可以获取锁;如果不是,它将监视比自己顺序编号小的节点,等待其删除后尝试重新获取锁。
当任务完成后,客户端会删除自己创建的临时顺序节点,从而释放锁。
服务发现
Zookeeper 在分布式系统中广泛应用于服务发现机制。服务发现指的是在分布式环境中,动态地查询服务的可用实例并进行负载均衡。Zookeeper 可以通过其提供的节点存储和 Watcher 机制,动态管理服务实例。
实现步骤:
将所有服务实例注册到 Zookeeper 中,每个服务实例对应一个 ZNode。
客户端通过 Watcher 监控服务节点的变化,获取可用的服务实例列表。
当服务新增或删除时,客户端能够动态地发现新的服务。
$ zkCli.sh
#服务实例注册:
[zk: localhost:2181(CONNECTED) 0] create /services/myapp/service1 "Service 1"
[zk: localhost:2181(CONNECTED) 1] create /services/myapp/service2 "Service 2"
#Java 客户端获取服务实例:
import org.apache.zookeeper.*;
import java.util.List;
public class ZookeeperServiceDiscovery {
private static ZooKeeper zk;
private static String servicePath = "/services/myapp";
public static void main(String[] args) throws Exception {
zk = new ZooKeeper("localhost:2181", 3000, new Watcher() {
public void process(WatchedEvent event) {
// 监控服务实例变化
if (event.getType() == Event.EventType.NodeChildrenChanged) {
try {
getServiceInstances(); // 获取更新后的服务实例列表
} catch (Exception e) {
e.printStackTrace();
}
}
}
});
// 获取服务实例
getServiceInstances();
// 保持客户端运行
Thread.sleep(Long.MAX_VALUE);
}
private static void getServiceInstances() throws Exception {
List<String> serviceInstances = zk.getChildren(servicePath, true); // true 表示设置Watcher
System.out.println("Current available services: " + serviceInstances);
}
}
使用说明:
将服务实例(如 service1, service2)注册到 /services/myapp 路径下。
客户端通过 zk.getChildren() 获取该路径下所有的子节点,这些子节点代表了当前活跃的服务实例。
客户端通过设置 Watcher,当服务节点发生变化(如新增、删除)时,能够动态获取服务实例列表并更新。
分布式队列(高并发任务分发)
Zookeeper 还可以实现分布式队列。在这种场景下,多个消费者从队列中取任务并执行,Zookeeper 确保任务顺序和公平性。
实现步骤:
生产者将任务数据放入 Zookeeper 中,创建一个任务节点。
消费者获取最早的任务并处理,处理完成后删除该节点。
Zookeeper 保证任务的顺序性和节点的独占性。
import org.apache.zookeeper.*;
import java.util.List;
import java.util.Collections;
public class ZookeeperDistributedQueue {
private static ZooKeeper zk;
private static String queuePath = "/queue";
public static void main(String[] args) throws Exception {
zk = new ZooKeeper("localhost:2181", 3000, new Watcher() {
public void process(WatchedEvent event) {
// 处理事件
}
});
// 创建队列路径
createQueuePath();
// 生产者入队
enqueue("task1");
enqueue("task2");
// 消费者出队并处理
dequeue();
}
private static void createQueuePath() throws Exception {
if (zk.exists(queuePath, false) == null) {
zk.create(queuePath, new byte[0], ZooDefs.Ids.OPEN_ACL_UNSAFE, CreateMode.PERSISTENT);
}
}
private static void enqueue(String task) throws Exception {
String taskNode = zk.create(queuePath + "/task-", task.getBytes(), ZooDefs.Ids.OPEN_ACL_UNSAFE, CreateMode.PERSISTENT_SEQUENTIAL);
System.out.println("Enqueued task: " + taskNode);
}
private static void dequeue() throws Exception {
List<String> tasks = zk.getChildren(queuePath, false);
Collections.sort(tasks); // 确保任务顺序执行
if (!tasks.isEmpty()) {
String taskToProcess = tasks.get(0);
byte[] taskData = zk.getData(queuePath + "/" + taskToProcess, false, null);
System.out.println("Processing task: " + new String(taskData));
// 删除已处理的任务
zk.delete(queuePath + "/" + taskToProcess, -1);
System.out.println("Processed and removed task: " + taskToProcess);
}
}
}
通过创建顺序节点,每个任务都会在队列中有一个唯一的位置。消费者根据任务顺序(即节点的编号)获取任务。
任务处理完成后,消费者删除任务节点,确保任务不会被重复消费。
Leader 选举
Zookeeper 常用于实现分布式系统中的 Leader 选举。Leader 选举用于确保在分布式环境中某一时刻只有一个节点被选举为 Leader,通常用于保证对资源的独占访问。其他节点(Follower)则等待 Leader 的指示,通常在数据库或任务调度系统中会使用 Leader 选举来避免竞争条件
实现步骤:
节点尝试创建一个临时顺序节点。
节点检查自己是否是最小的顺序节点。
如果是,成为 Leader。如果不是,则监听比自己顺序编号小的节点,等待它被删除后重新参与选举。
import org.apache.zookeeper.*;
import java.util.Collections;
import java.util.List;
public class ZookeeperLeaderElection {
private static ZooKeeper zk;
private static String electPath = "/leader";
private static String currentNode;
public static void main(String[] args) throws Exception {
zk = new ZooKeeper("localhost:2181", 3000, new Watcher() {
public void process(WatchedEvent event) {
// 处理事件
}
});
// 创建临时顺序节点
currentNode = zk.create(electPath + "/node-", new byte[0], ZooDefs.Ids.OPEN_ACL_UNSAFE, CreateMode.EPHEMERAL_SEQUENTIAL);
// 选举Leader
electLeader();
// 模拟执行Leader任务
Thread.sleep(5000);
// 释放Leader
releaseLeader();
}
private static void electLeader() throws Exception {
List<String> children = zk.getChildren(electPath, false);
Collections.sort(children); // 排序节点,最小编号的节点成为Leader
String firstNode = children.get(0);
if (currentNode.endsWith(firstNode)) {
System.out.println("I am the Leader!");
} else {
String prevNode = children.get(children.indexOf(currentNode.substring(electPath.length())) - 1);
zk.exists(electPath + "/" + prevNode, new Watcher() {
public void process(WatchedEvent event) {
if (event.getType() == Event.EventType.NodeDeleted) {
try {
electLeader(); // 前一个节点被删除时,尝试重新选举Leader
} catch (Exception e) {
e.printStackTrace();
}
}
}
});
}
}
private static void releaseLeader() throws Exception {
zk.delete(currentNode, -1);
System.out.println("Released Leader role.");
}
}
这个例子中,通过创建临时顺序节点(/leader/node-)来进行选举,节点会在节点列表中排序,最小编号的节点被选为 Leader。
如果当前节点不是最小的编号,它会监听比自己编号小的节点,当该节点被删除时,当前节点会尝试重新成为 Leader。
分布式计数器
Zookeeper 还可以用来实现分布式计数器。这通常用于在多个节点间共享一个递增的计数值。Zookeeper 提供的 临时顺序节点 可以帮助实现计数器,保证计数的顺序性和一致性。
实现步骤:
每个增量操作创建一个临时顺序节点。
节点的顺序值表示当前的计数值。
import org.apache.zookeeper.*;
public class ZookeeperDistributedCounter {
private static ZooKeeper zk;
private static String counterPath = "/counter";
public static void main(String[] args) throws Exception {
zk = new ZooKeeper("localhost:2181", 3000, new Watcher() {
public void process(WatchedEvent event) {
// 处理事件
}
});
// 创建计数器
createCounter();
// 递增计数器
incrementCounter();
// 获取计数器值
getCounterValue();
}
private static void createCounter() throws Exception {
if (zk.exists(counterPath, false) == null) {
zk.create(counterPath, new byte[0], ZooDefs.Ids.OPEN_ACL_UNSAFE, CreateMode.PERSISTENT);
}
}
private static void incrementCounter() throws Exception {
String nodeName = zk.create(counterPath + "/node-", new byte[0], ZooDefs.Ids.OPEN_ACL_UNSAFE, CreateMode.EPHEMERAL_SEQUENTIAL);
System.out.println("Incremented Counter: " + nodeName);
}
private static void getCounterValue() throws Exception {
List<String> children = zk.getChildren(counterPath, false);
System.out.println("Current Counter Value: " + children.size());
}
}
该代码实现了一个分布式计数器,通过创建临时顺序节点 (/counter/node-) 来递增计数器。
每次创建新的临时顺序节点时,节点的顺序号自动递增。通过获取 /counter 路径下的所有子节点数量,获取当前计数器的值。
分布式任务调度
在分布式系统中,任务调度器常常需要协调不同节点的任务执行。Zookeeper 可用于任务的调度和管理,确保任务的分配是有序和高效的。例如,Zookeeper 可以用来确保每个任务只有一个节点在执行,从而避免重复执行。
实现步骤:
为每个任务创建一个 ZNode。
各个节点轮流获取任务并执行,确保任务的有序调度。
节点执行完任务后删除任务 ZNode,表示任务完成。
import org.apache.zookeeper.*;
public class ZookeeperTaskScheduler {
private static ZooKeeper zk;
private static String taskPath = "/tasks";
public static void main(String[] args) throws Exception {
zk = new ZooKeeper("localhost:2181", 3000, new Watcher() {
public void process(WatchedEvent event) {
// 处理事件
}
});
// 创建任务路径
createTaskPath();
// 调度任务
scheduleTask();
// 保持客户端运行
Thread.sleep(Long.MAX_VALUE);
}
private static void createTaskPath() throws Exception {
if (zk.exists(taskPath, false) == null) {
zk.create(taskPath, new byte[0], ZooDefs.Ids.OPEN_ACL_UNSAFE, CreateMode.PERSISTENT);
}
}
private static void scheduleTask() throws Exception {
// 创建任务节点
String taskNode = zk.create(taskPath + "/task-", new byte[0], ZooDefs.Ids.OPEN_ACL_UNSAFE, CreateMode.EPHEMERAL_SEQUENTIAL);
System.out.println("Task created: " + taskNode);
// 获取所有任务节点并排序
List<String> tasks = zk.getChildren(taskPath, false);
Collections.sort(tasks); // 确保任务按照顺序执行
String taskToExecute = taskPath + "/" + tasks.get(0);
System.out.println("Executing task: " + taskToExecute);
// 执行任务(这里只是打印任务信息,实际应用可以做更复杂的操作)
zk.delete(taskToExecute, -1);
System.out.println("Task completed and removed: " + taskToExecute);
}
}
任务调度过程中,每个任务都被创建为一个临时顺序节点,节点顺序决定任务的执行顺序。
节点在执行完任务后会被删除,确保任务不会被重复执行。
全局唯一ID生成
在分布式系统中,经常需要生成全局唯一的 ID。Zookeeper 提供的临时顺序节点可以帮助生成全局唯一的 ID,通过创建顺序节点来实现 ID 的递增。
实现步骤:
在某个路径下创建临时顺序节点。
通过顺序节点的编号来生成唯一 ID。
import org.apache.zookeeper.*;
public class ZookeeperUniqueIDGenerator {
private static ZooKeeper zk;
private static String idPath = "/unique_id";
public static void main(String[] args) throws Exception {
zk = new ZooKeeper("localhost:2181", 3000, new Watcher() {
public void process(WatchedEvent event) {
// 处理事件
}
});
// 创建唯一ID路径
createIDPath();
// 生成唯一ID
generateUniqueID();
}
private static void createIDPath() throws Exception {
if (zk.exists(idPath, false) == null) {
zk.create(idPath, new byte[0], ZooDefs.Ids.OPEN_ACL_UNSAFE, CreateMode.PERSISTENT);
}
}
private static void generateUniqueID() throws Exception {
String idNode = zk.create(idPath + "/id-", new byte[0], ZooDefs.Ids.OPEN_ACL_UNSAFE, CreateMode.EPHEMERAL_SEQUENTIAL);
System.out.println("Generated unique ID: " + idNode);
}
}
每次生成 ID 时,都会在 /unique_id/id- 路径下创建一个临时顺序节点。通过节点的顺序号来生成全局唯一的 ID。
服务协调与健康检查
Zookeeper 作为一个高可用的分布式系统协调服务,能够帮助进行 服务协调 和 健康检查。在微服务架构中,Zookeeper 可以用于管理各个服务实例的健康状态,自动将健康服务加入到负载均衡池中。
实现步骤:
各服务节点定期更新自己的健康状态到 Zookeeper 中。
如果某个服务失效,它的健康状态会被 Zookeeper 监控并移除。
客户端或负载均衡器通过 Zookeeper 查询健康的服务实例。
import org.apache.zookeeper.*;
import java.util.List;
public class ZookeeperServiceHealthCheck {
private static ZooKeeper zk;
private static String servicePath = "/services";
public static void main(String[] args) throws Exception {
zk = new ZooKeeper("localhost:2181", 3000, new Watcher() {
public void process(WatchedEvent event) {
// 处理事件
}
});
// 注册服务实例(健康检查)
registerService("service1");
registerService("service2");
// 定期检查健康状态
checkServiceHealth();
// 保持客户端运行
Thread.sleep(Long.MAX_VALUE);
}
private static void registerService(String serviceName) throws Exception {
String serviceNode = zk.create(servicePath + "/" + serviceName, "healthy".getBytes(), ZooDefs.Ids.OPEN_ACL_UNSAFE, CreateMode.EPHEMERAL);
System.out.println(serviceName + " registered with Zookeeper");
}
private static void checkServiceHealth() throws Exception {
List<String> services = zk.getChildren(servicePath, new Watcher() {
public void process(WatchedEvent event) {
// 重新检查健康状态
try {
checkServiceHealth();
} catch (Exception e) {
e.printStackTrace();
}
}
});
System.out.println("Currently available services: " + services);
for (String service : services) {
byte[] status = zk.getData(servicePath + "/" + service, false, null);
System.out.println(service + " status: " + new String(status));
}
}
}
服务实例通过 Zookeeper 注册,并设置为临时节点。
健康检查机制通过 getData 获取服务的健康状态数据,客户端实时监控服务状态变化。
如果某个服务挂掉,Zookeeper 会自动删除其临时节点,负载均衡器就可以检测到服务的失效。
分布式屏障(Barrier)
分布式屏障(Barrier)是一种同步原语,它可以确保所有参与者在达到某个条件后才能继续执行。例如,多个节点需要等待其他节点都准备好后才开始执行某个任务。Zookeeper 可以很好地实现这一功能,确保所有节点在同步点都达到一致,然后才能继续执行。
示例应用
Kafka集群管理:Kafka 使用 ZooKeeper 来管理其集群的元数据,如主题分区信息、集群成员信息等。
Hadoop生态系统:Hadoop的YARN资源管理器使用ZooKeeper来管理应用程序的生命周期和资源分配。
实现步骤:
每个节点在进入屏障时,会在 Zookeeper 中创建一个临时节点。
当所有节点都到达同步点(即所有临时节点都创建)后,才允许所有节点继续执行。
Zookeeper 会监控这些临时节点的数量,当数量达到预定值时,解除阻塞。
import org.apache.zookeeper.*;
import java.util.List;
public class ZookeeperDistributedBarrier {
private static ZooKeeper zk;
private static String barrierPath = "/barrier";
private static int totalParticipants = 3; // 假设有3个参与者
public static void main(String[] args) throws Exception {
zk = new ZooKeeper("localhost:2181", 3000, new Watcher() {
public void process(WatchedEvent event) {
// 处理事件
}
});
// 创建屏障路径
createBarrierPath();
// 节点加入屏障
joinBarrier("node1");
joinBarrier("node2");
joinBarrier("node3");
// 等待所有节点加入屏障
waitForAllNodes();
}
private static void createBarrierPath() throws Exception {
if (zk.exists(barrierPath, false) == null) {
zk.create(barrierPath, new byte[0], ZooDefs.Ids.OPEN_ACL_UNSAFE, CreateMode.PERSISTENT);
}
}
private static void joinBarrier(String nodeName) throws Exception {
zk.create(barrierPath + "/" + nodeName, new byte[0], ZooDefs.Ids.OPEN_ACL_UNSAFE, CreateMode.EPHEMERAL);
System.out.println(nodeName + " reached the barrier");
}
private static void waitForAllNodes() throws Exception {
List<String> children = zk.getChildren(barrierPath, false);
while (children.size() < totalParticipants) {
System.out.println("Waiting for other nodes...");
Thread.sleep(1000);
children = zk.getChildren(barrierPath, false); // 重新获取子节点
}
System.out.println("All nodes reached the barrier, continuing execution...");
}
}
每个节点通过在 Zookeeper 中创建临时节点加入到屏障路径 /barrier 下。
其他节点会检查当前屏障下的节点数量,直到达到预期的参与者数量,才解除阻塞,继续执行。
ZAB协议
Zab( ZooKeeper Atomic Broadcast , ZooKeeper 原子消息广播协议)协议是一个分布式一致性算法,让ZK拥有了崩溃恢复和原子广播的能力,进而保证集群中的数据一致性。
协议的事务编号 Zxid 设计中,ZXID是一个长度64位的数字,其中低32位是按照数字递增,任何数据的变更都会导致,低32位的数字简单加1。高32位是leader周期编号,每当选举出一个新的leader时,新的leader就从本地事物日志中取出ZXID,然后解析出高32位的周期编号,进行加1,再将低32位的全部设置为0。这样就保证了每次新选举的leader后,保证了ZXID的唯一性而且是保证递增的。
Zab 协议有两种模式,它们分别是恢复模式和广播模式:
当服务启动或者在领导者崩溃后,Zab 就进入了恢复模式,当领导者被选举出来,且大多数 server 的完成了和 leader 的状态同步以后,恢复模式就结束了,他就可以开始广播消息了,即进入广播状态
Zab协议分为四个核心步骤:
选举: 在ZooKeeper集群中选举中一个Leader
发现: Leader中会维护一个Follower的列表和Observer列表并与之通信
同步: Leader会把自己的数据同步给Follower和Observer, 做到多副本存储
广播: Leader接受Follower的事务Proposal,然后将这个事务性的proposal广播给其他learner
客户端
Curator是Netflix公司在原生zookeeper基础上开源的一个ZooKeeper Java客户端,现在是Apache下的一个开源项目。Curator解决了原生客户端存在的一系列问题,并提供了Fluent风格的操作API,针对业务场景,提供了如分布式锁、集群领导选举、分布式计数器、缓存机制、分布式队列等工具类
参考:https://gitee.com/wenwang2000/spring-multiple-datasource/tree/master/spring-boot-zookeeper
<!-- curator-framework -->
<dependency>
<groupId>org.apache.curator</groupId>
<artifactId>curator-framework</artifactId>
<version>版本号</version>
</dependency>
<!-- curator-recipes,业务场景解决方案 -->
<dependency>
<groupId>org.apache.curator</groupId>
<artifactId>curator-recipes</artifactId>
<version>版本号</version>
</dependency>
运维命令
ZooKeeper响应少量命令。每个命令由四个字母组成。可通过telnet或nc向ZooKeeper发出命令。
这些命令默认是关闭的,需要配置4lw.commands.whitelist来打开,可打开部分或全部示例如下:
#打开指定命令
4lw.commands.whitelist=stat, ruok, conf, isro
#打开全部
4lw.commands.whitelist=*
# 安装Netcat工具,已使用nc命令 查看服务器及客户端连接状态
echo stat | nc localhost 2181
常用命令
[stat] # 列出连接客户端列表、最大/平均/最小延迟数、数据接收/发送量、连接数、节点总数、模式 echo stat | nc 127.0.0.1 2181
[ruok] # Are You Ok的缩写,测试服务器是否正在运行,如果在运行返回imok,否则返回空 echo ruok | nc 127.0.0.1 2181
[dump] # 列出未经处理的会话和临时节点 echo dump | nc 127.0.0.1 2181
[conf] # 输出Zookeeper相关服务的详细配置信息,如客户端端口,数据存储路径、最大连接数、日志路径、数据同步端口、主节点推举端口、session超时时间等等 echo conf | nc 127.0.0.1 2181
[cons] # 输出连接到Zookeeper的服务器信息,包括队列、数据接收量、数据发送量、sessionID、操作延时、最后的操作信息等等 echo cons | nc 127.0.0.1 2181
[envi] # 列出zookeeper的版本信息、主机名称、Java版本、java_home、class_path、服务器名称、当前登陆用户名、目录等等; echo envi | nc 127.0.0.1 2181
[crst] # 重置当前的所有连接、会话等等 echo crst | nc 127.0.0.1 2181
[srst ] # 重置Zookeeper的所有统计信息 echo srst nc 127.0.0.1 2181
[srvr] # 列出zookeeper的版本信息、数据接收/发送量、连接数、节点模式、Node数、最大/平均/最小延迟数 echo srvr | nc 127.0.0.1 2181
[wchs] # 列出watch的总数,连接数 echo wchs | nc 127.0.0.1 2181
[wchp] # 列出所有watch的路径及sessionID echo wchp | nc 127.0.0.1 2181
[mntr] # 列出集群的关键性能数据,包括zk的版本、最大/平均/最小延迟数、数据包接收/发送量、连接数、zk角色(Leader/Follower)、node数量、watch数量、临时节点数 echo mntr | nc 127.0.0.1 2181

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









