





安装Ollama
Ollama 是一个开源的大型语言模型(LLM)平台,旨在让用户能够轻松地在本地运行、管理和与大型语言模型进行交互。
Ollama 提供了一个简单的方式来加载和使用各种预训练的语言模型,支持文本生成、翻译、代码编写、问答等多种自然语言处理任务。
Ollama 的特点在于它不仅仅提供了现成的模型和工具集,还提供了方便的界面和 API,使得从文本生成、对话系统到语义分析等任务都能快速实现。
与其他 NLP 框架不同,Ollama 旨在简化用户的工作流程,使得机器学习不再是只有深度技术背景的开发者才能触及的领域。
Ollama 支持多种硬件加速选项,包括纯 CPU 推理和各类底层计算架构(如 Apple Silicon),能够更好地利用不同类型的硬件资源。
官方下载 https://ollama.com/download
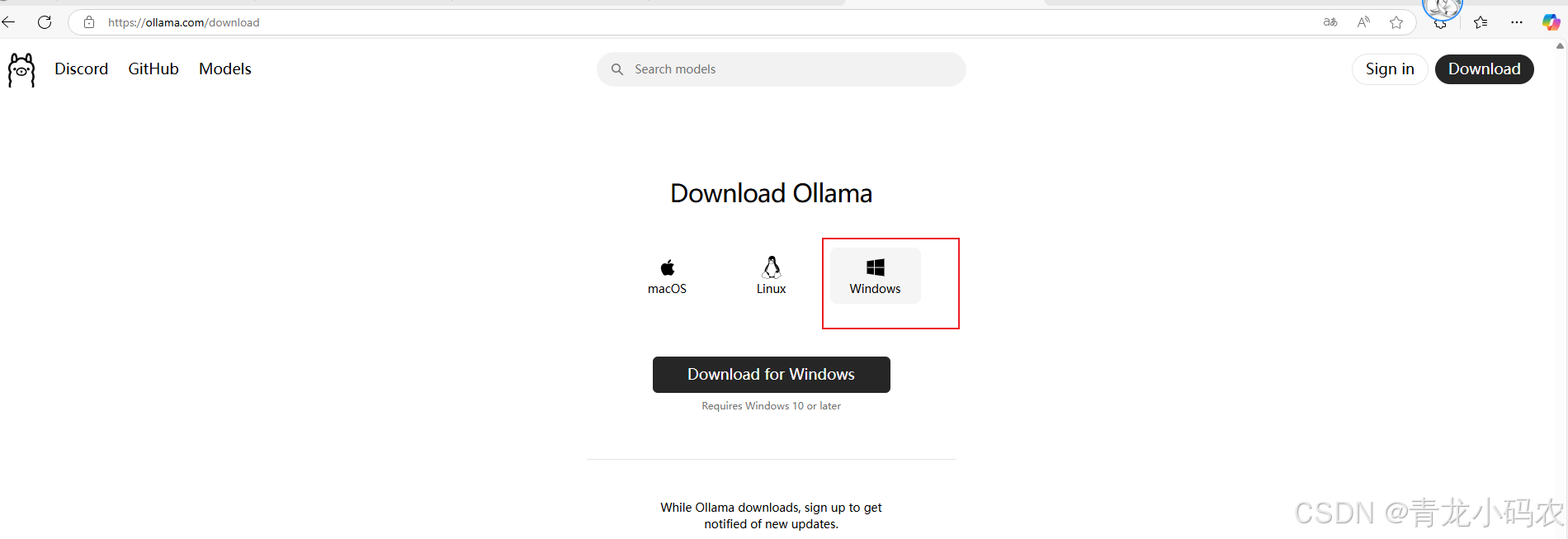
在电脑上看到 Ollama 的图标,双击打开即可(安装完成后默认是启动的):
本地安装 Ollama
安装位置:C:\Users\用户名\AppData\Local\Programs\Ollama
访问地址: http://localhost:11434
开启IP访问(增加系统变量):OLLAMA_HOST=0.0.0.0:11434

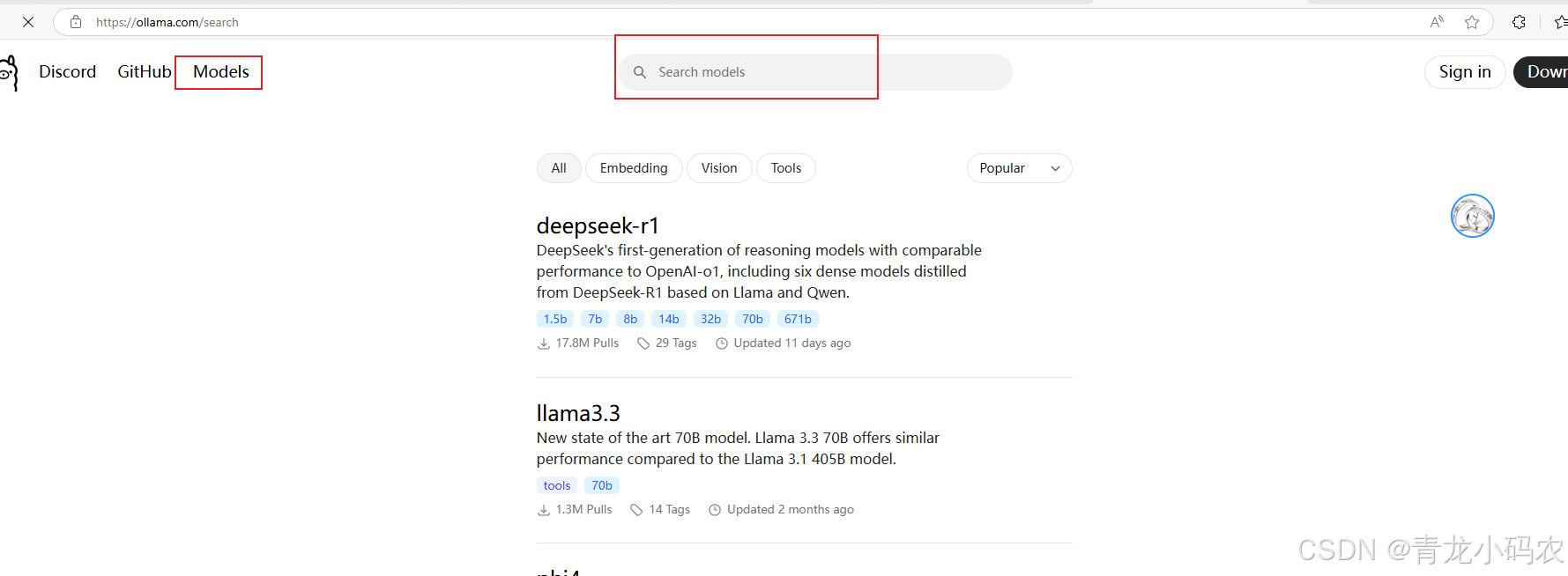
模型(Model)
在 Ollama 中,模型是核心组成部分。它们是经过预训练的机器学习模型,能够执行不同的任务,例如文本生成、文本摘要、情感分析、对话生成等。
Ollama 支持多种流行的预训练模型,常见的模型有:
- deepseek:深度求索提供的大型语言模型,专门用于文本生成任务。
- LLama2:Meta 提供的大型语言模型,专门用于文本生成任务。
- GPT:OpenAI 的 GPT 系列模型,适用于广泛的对话生成、文本推理等任务。
- BERT:用于句子理解和问答系统的预训练模型。
- 其他自定义模型:用户可以上传自己的自定义模型,并利用 Ollama 进行推理。
模型的主要功能:
- 推理(Inference):根据用户输入生成输出结果。
- 微调(Fine-tuning):用户可以在已有模型的基础上使用自己的数据进行训练,从而定制化模型以适应特定的任务或领域。
模型通常是由大量参数构成的神经网络,通过对大量文本数据进行训练,能够学习语言规律并进行高效的推理。
任务(Task)
Ollama 支持多种 NLP 任务。每个任务对应模型的不同应用场景,主要包括但不限于以下几种:
- 对话生成(Chat Generation):通过与用户交互生成自然的对话回复。
- 文本生成(Text Generation):根据给定的提示生成自然语言文本,例如写文章、生成故事等。
- 情感分析(Sentiment Analysis):分析给定文本的情感倾向(如正面、负面、中立)。
- 文本摘要(Text Summarization):将长文本压缩为简洁的摘要。
- 翻译(Translation):将文本从一种语言翻译成另一种语言。
通过命令行工具,用户可以指定不同的任务,并加载不同的模型来完成特定任务。
推理(Inference)
推理是指在已训练的模型上进行输入处理,生成输出的过程。
推理过程:
- 输入:用户向模型提供文本输入,可以是一个问题、提示或者对话内容。
- 模型处理:模型通过内置的神经网络根据输入生成适当的输出。
- 输出:模型返回生成的文本内容,可能是回复、生成的文章、翻译文本等。
微调(Fine-tuning)
微调是指在一个已预训练的模型上,基于特定的领域数据进行进一步的训练,以便使模型在特定任务或领域上表现得更好。
Ollama 支持微调功能,用户可以使用自己的数据集对预训练模型进行微调,来定制模型的输出。
微调过程:
- 准备数据集:用户准备特定领域的数据集,数据格式通常为文本文件或 JSON 格式。
- 加载预训练模型:选择一个适合微调的预训练模型,例如 LLama2 或 GPT 模型。
- 训练:使用用户的特定数据集对模型进行训练,使其能够更好地适应目标任务。
- 保存和部署:训练完成后,微调过的模型可以保存并部署,供以后使用。
下载Deepseek
| DeepSeek模型版本 | 参数量 | 特点 | 适用场景 | 硬件配置 |
|---|---|---|---|---|
| DeepSeek-R1-1.5B | 1.5B | 轻量级模型,参数量少,模型规模小 | 适用 |
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1317
1317

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









