







在第三章也就是上一章的内容中,学到了改进神经网络的学习方法,其中包括一开始解决到的使用二次代价函数导致的学习缓慢问题,过拟合和相关规范化的问题,还有其他类型的神经元模型,让我们知道了对于一个网络来说一些超参数的选定方式。
那么本章中主要是介绍深度学习网络,在这里可以看到我们的网络是如何逐步进行特征提取,池化,然后输入隐藏层最终输出的。当然在这一章我也做了一些实验,有关mnist数据集手写数字识别的例子。
- 介绍卷积网络
- 局部感受野
- 共享权重和偏置
- 池化层(混合层)
- 实践部分
介绍卷积网络
其实在前面的章节中,我们已经学到了如何识别手写数字,那我们前面使用的网络主要是全连接的邻接关系的网络。既网络中的神经元与相邻的层上的每个神经元均连接:
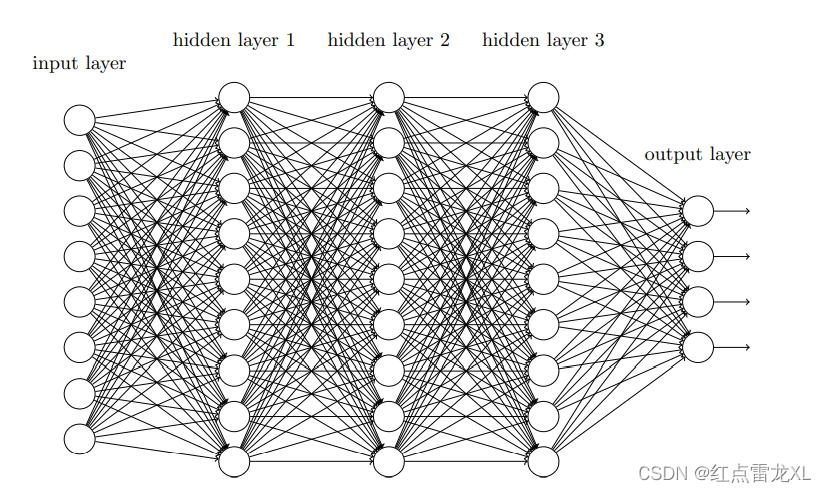
让我们感到疑惑的问题就是,这个网络完全不考虑图像的空间结构,它在完全相同的基础上去堆到两个相距很近或者相距很远的输入像素,我想可能在后续权重和偏置变化中会显示出不同,但开始组建网络的时,就显得不那么合理了。
然后根据存在的这些问题,就开始描述卷积神经网络(Convolutional neural networks),其中这卷积神经网络采用了三种基本概念:局部感受野,共享权重,和混合。
局部感受野
在之前的全连接的网络中,我们看到的图像的神经元往往是排成一列组成输入神经元然后全连接的。而卷积网络中,我们把输入看作是一个28×28的神经元则更好一点,

但其实本质上都是一样的,都是把图像的每个像素点看作一个输入神经元,然后出入到网络的隐藏层,只不过输入的方式不一样。
对于卷积网络来说,不会吧每个输入像素连接到每个隐藏神经元,相反我们只把输入图像进行小的,局部区域的链接。具体就是把输入神经元的一个小区域链接到第一个隐藏层的每个神经元。类似:
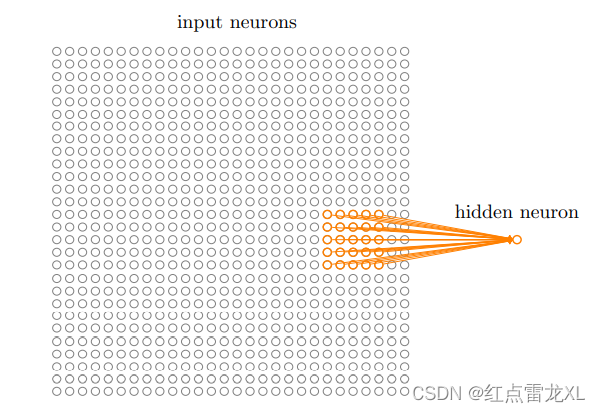
其中在黄线牵着的神经元区域称为隐藏神经元的局部感受野。它是输入像素上的一个小窗口,每个链接学习的一个权重。
然后再整个输入像素上交叉移动局部感受野,对于每个局部感受野,再第一个隐藏层中有一个不同的隐藏神经元。
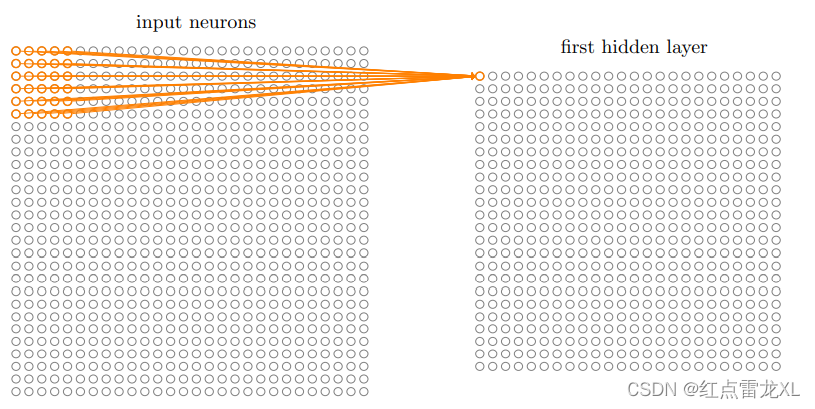
如果我们使用28×28的输入像素,5×5的局部感受域,通过局部感受域的不断滑动,那么隐藏层中就会有24×24个神经元。
其中面我们使用的是一个行或一列的移动,也可以是两列两行的移动,也就成为不同的步长,文章中使用的步长为1。
共享权重和偏置
上面已经说过,对于每个隐藏层神经元具有一个偏置和连接到它的局部感受域的5×5权重,那么对于隐藏层的隐藏神经元我们打算使用的是一个相同的权重和偏置,换句话说,对于第j,k个隐藏神经元,输出为:
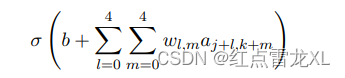
这里是神经元的激活函数,b是偏置的共享值,
是一个共享权重的5×5数组,最终我们使用
来表示位置为x,y的输入激活值。
我们有时候把从输⼊层到隐藏层的映射称为⼀个特征映射。我们把定义特 征映射的权重称为共享权重。我们把以这种⽅式定义特征映射的偏置称为共享偏置。共享权重 和偏置经常被称为⼀个卷积核或者滤波器。
目前描述的网络只能检测一种局部特征的类型,其实在正常情况下一个像素点往往有3个或5个或者更多的特征。有时为了完成图像识别我们需要超过一个的特征映射,那么一个完整的卷积层也是由几个不同的特征映射组成。
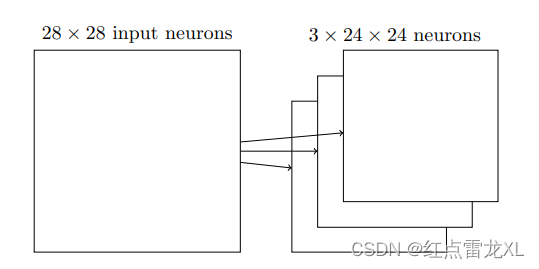
比如在一个图像中,我们需要提取它的三个特征,比如RGB,往往需要获取不同通道的特征。
池化层(混合层)
对于一个卷积神经网络来说,除了上面刚刚提到的卷积层,还包括一个混合层,当然,混合层一般紧接在卷积层之后,它的目的就是简化从卷积层输出的信息。
例如,池化层的每一个神经元要总结卷积层的一个小区域比如2×2的信息,其中还有很常用的max-pooling,他是将卷积层的小区域中的最大的一个保存下来:

把上面卷积层的24×24个神经元通过池化后,我们就会得到12×12个神经元,注意这里没有滑动的操作,我们只是把一个区域内的神经元的最大值保存了下来。对于12×12的话,就是24/2得到的。
然后通过池化后我们的得到的卷积层和池化层看起来就像这样:
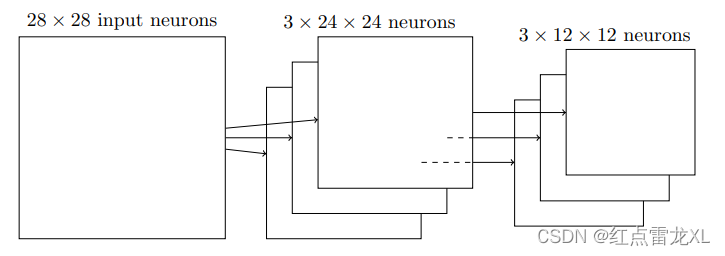
其中还有另外的池化的方法,比如L2混合。去2×2区域中激活值的平方和的平方根,而不是最大激活值。
把上述的结构整合在一起,就可以构建一个完整的网络了,最终的完整的卷积神经网络:
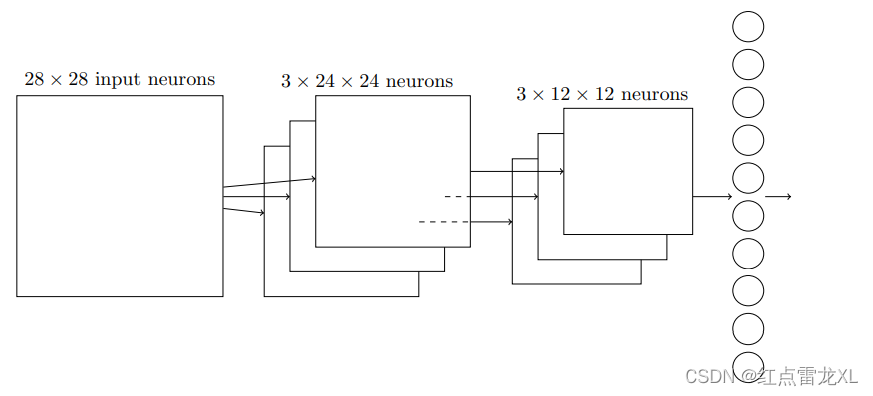
实践部分
整本书的实验部分,我的话只是做了这第六章的,其实前面也是有的,其中运行方式都是相同的,只拿出来一部分作为展示就可以了。
目录展示
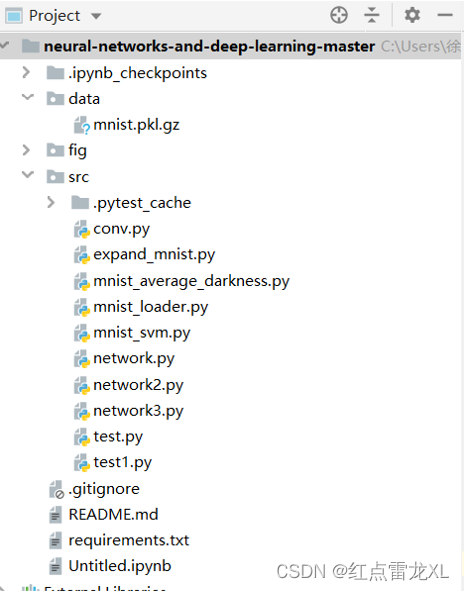
可以看到整个mnist手写数字识别项目的目录,其中我下面的实验都是基于network3的。
使用工具

其中项目运行,网络模型构建的工具使用的anaconda的一个notebook,用这个的主要原因我想应该是比较方便,比如这里用到的一些库比如theano等,直接可以从anaconda上下载,也不用担心比较乱的问题。
获得结果后需要做的就是一个对数据的处理,方便后面用matlab作图,查看一下具体的运行过程。
运行过程及脚本展示
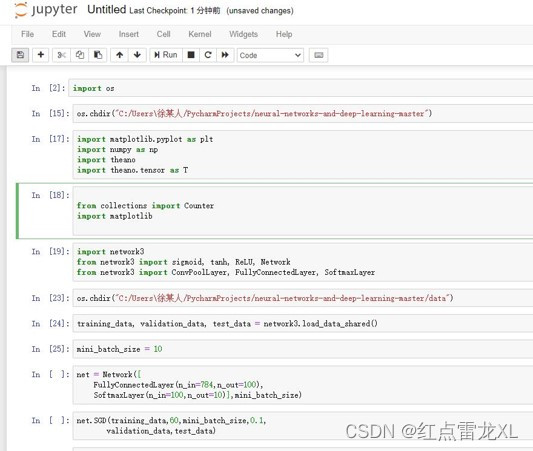
这是在notebook上的脚本,当然这种也可以在pythonshell上运行,都是一样的,然后书中其实还给了其他的脚本,主要就是一些其他网络的构建,比如多一个或两个卷积网络(也就是卷积层和池化层)等等。
其中我使用的网络是很简单的,就是一个全连接层的网络。
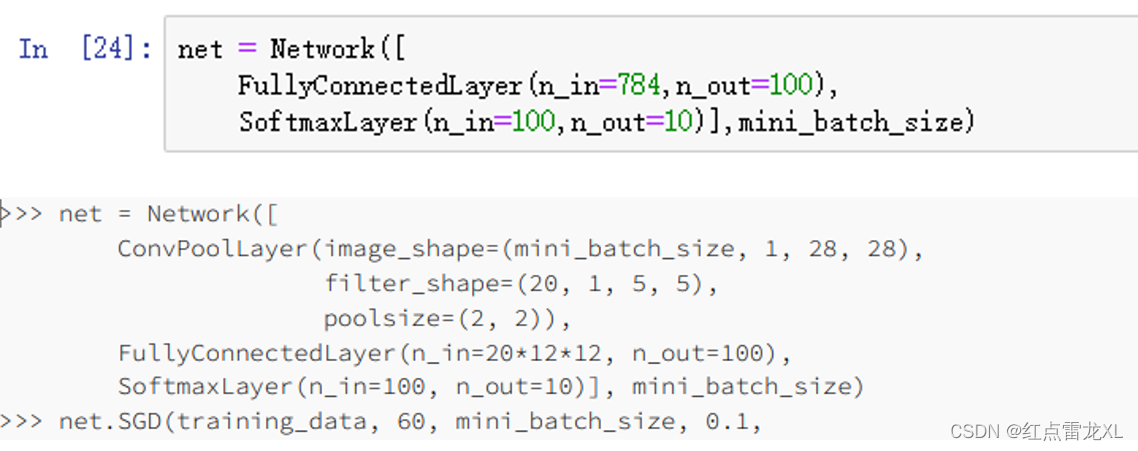
当然在做的时候也可以加入卷积层和池化层。其中添加的部分如下图所示:
其中我也没有使用gpu加速

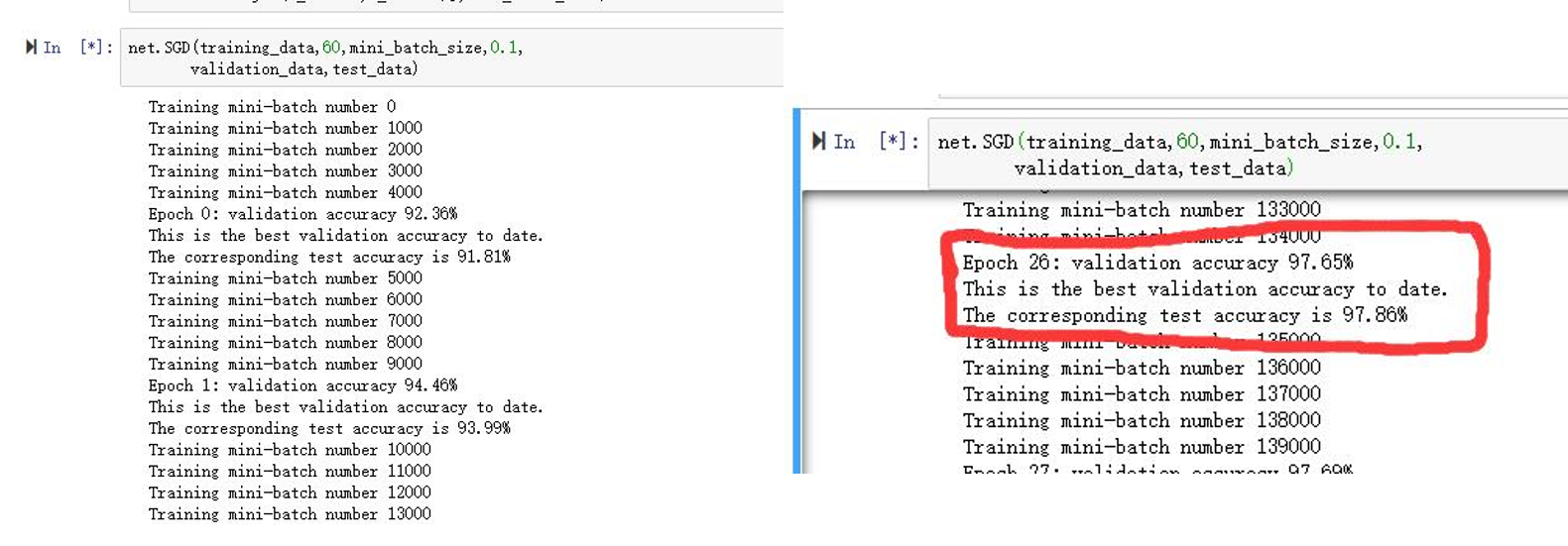
最终结果可以看到:
数据处理、图像生成和效果查看
在上面取得结果后,我们就可以使用python进行数据处理,主要是去掉一些没用的数据。
导入一个csv文件中,那么这个文件就可以直接导入matlab中进行作图
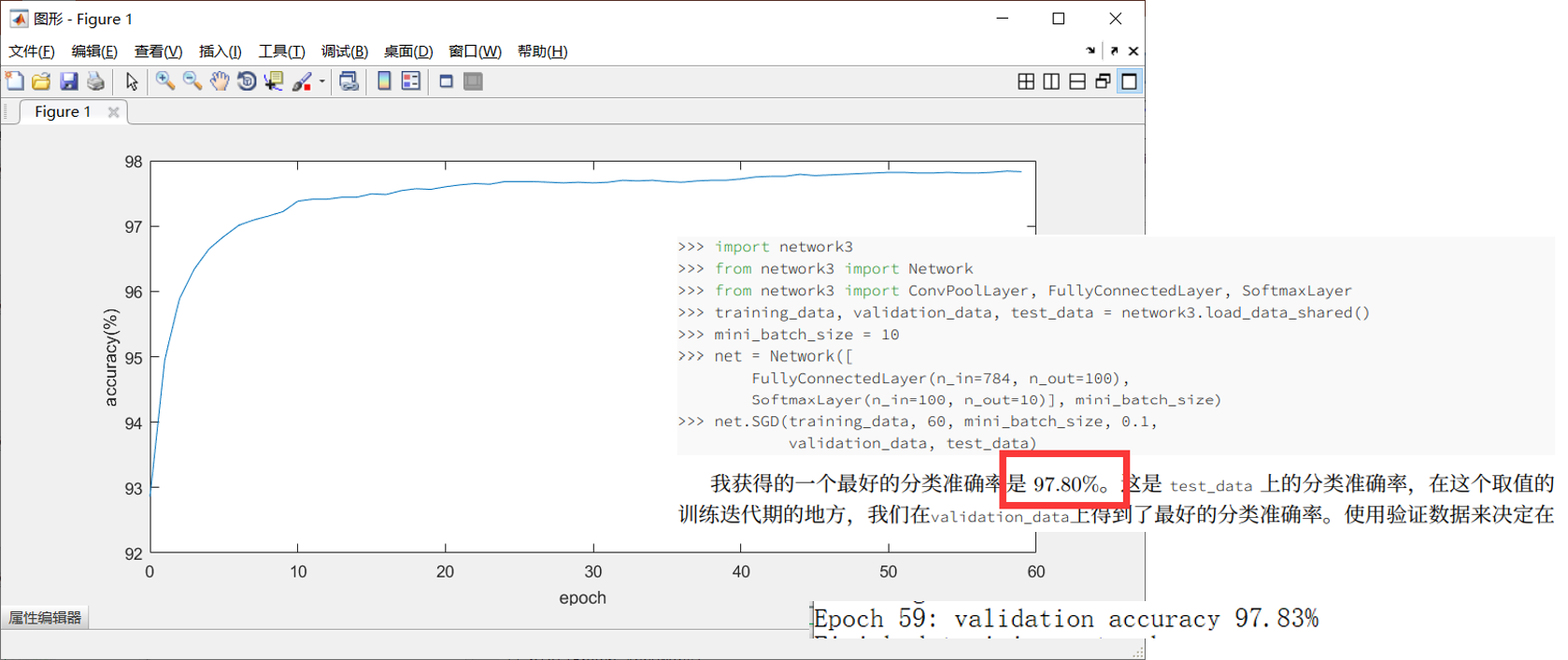
然后的话和书上的数据进行比对一下就可以了,可以看到整体的趋势和最终的结果方面与书上的都大致相似,表示实验成功。
上面就是我对于nndl这本书学习到的内容了,其中我只学习了第一章,第二章,第三章,第六章的内容。书中给出的概念的介绍也是非常易于理解的,对于实验过程来说,还是比较顺利的,把一些库导入,根据脚本设置一下网络的模型,最终进行数据处理图像生成一下就可以了,还是比较简单的。
当然,我是用的网络是比较简单的,使用这样的网络主要还是因为书中有这个简单网络的结果,我想比对一下以此确定是否成功。如果想用一个比较复杂的网络的话也是可以的,毕竟在这个书附带的github上也有很多的脚本,但具体的运行过程是不变的。
下面就是要进行对DLCV(Deep Learning for Computer Vision with Python - Starter Bundle)的学习了,这英文书目前读起来确实是慢了不少把。后面也会对DLCV的内容进行一个简单的总结,希望能学好一点。O(∩_∩)O


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









