



前言
Java本身就内置了一些优秀的API(拿来即用,无需自己造轮子)接口,通过这些接口能够节省开发时间,提升工作效率。
这里想对工作中常用到的容器类(Collection,Map)API做一个详细介绍和使用详解(包含代码案例)。
本篇幅侧重容器类的泛型应用,所有代码也都使用泛型,不了解泛型的同学请先学习泛型类。
一、容器类的概述和深入理解
- Java提供的容器类API都位于java.util.包内。
- 容器类API主要以Collection(数据集合)和Map(键值对数据)区分。
- Collection为集合数据结构的接口,接口中定义了一组列表的增删改查等API,不同的子类具备不同实现(工作中列表常用于数据传送)。
- Collection接口是集合数据结构的根接口
- Java提供了对Collection接口的子接口List,Set和Queue的具体实现(在后文中只对List,Set做深入了解。)
- Map为键值对数据结构的接口,Map在工作中广泛用于数据配置,缓存管理...,有时也用来处理数据
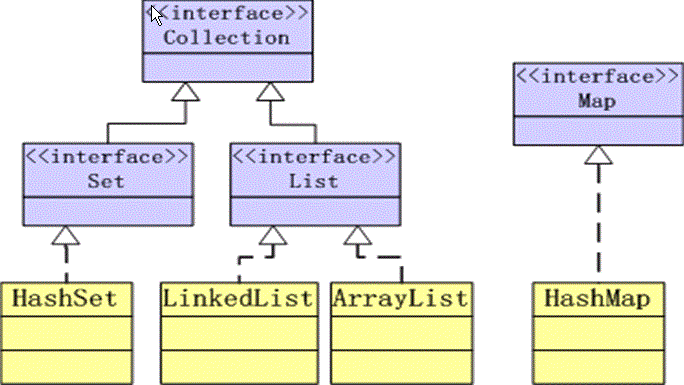
具体可以参考下面类关系图。
- 图中可以看到Collection为集合的根接口,子接口包括Set和List
- Set的具体实现类为HashSet
- List的具体实现类为LinkedList和ArrayList
- Map键值对数据结构不继承Collection,Map保持独立存在,且拥有HashMap和HashTable的具体实现(图中缺少HashTable的实现关系,后文会讲到)
二、Collection集合
2.1、Collection接口中定义的方法说明
Collection是一个接口类,它的接口中定义了如下抽象方法,这些抽象方法在所有子接口中继承,并由具体实现类实现。
| 方法 | 说明 |
| boolean add(E e) | 将指定的元素添加到集合中 |
| boolean addAll(Collection c) | 将指定集合的所有元素添加到集合中 |
| Iterator iterator() | 返回一个迭代器,该迭代器可用于顺序访问集合中的元素 |
| boolean remove() | 从集合中移除指定的元素 |
| boolean removeAll() | 从集合中删除指定集合的所有元素 |
| void clear() | 从集合中删除所有元素 |
| int size() | 返回集合的长度(元素数) |
| boolean isEmpty() | 判断集合是否为空 |
2.2、Set无序集合接口
- Set是一个无序的集合,集合中不能出现重复的元素!
- Set本身是接口,无法直接创建对象实例,可以通过其子类来创建使用。
- Set的子类实现类如下,以下子类都对Set做了具体实现,他们之间的关系属于implements
- EnumSet
- HashSet
- LinkedHashSet
- TreeSet
- Set接口常用方法如下,鉴于实际工作场景,代码案例以HashSet为例(工作中常用HashSet解决实际问题)。
| 方法 | 说明 |
| add() | 将指定的元素添加到集合中 |
| addAll() | 将指定集合的所有元素添加到集合中 |
| iterator() | 返回一个迭代器,该迭代器可用于顺序访问集合中的元素 |
| remove() | 从集合中移除指定的元素 |
| removeAll() | 从存在于另一个指定集合中的集合中删除所有元素 |
| clear() | 从集合中删除所有元素 |
| size() | 返回集合的长度(元素数) |
| keepAll() | 保留集合中所有还存在于另一个指定集合中的所有元素 |
| toArray() | 返回包含集合中所有元素的数组 |
| contains() | 如果集合包含指定的元素,则返回true |
| containsAll() | 如果集合包含指定集合的所有元素,则返回true |
| hashCode() | 返回哈希码值(集合中元素的地址) |
代码案例
案例中不会对所有函数方法都去测试,各位同学可以自己参考尝试测试结果
class Main {
public static void main(String[] args) {
//使用HashSet类创建集合
Set<Integer> set1 = new HashSet<>();
//将元素添加到set1
set1.add(2);
set1.add(3);
System.out.println("Set1: " + set1); // 控制台打印:Set1: [2, 3]
//使用HashSet类创建另一个集合
Set<Integer> set2 = new HashSet<>();
//添加元素
set2.add(1);
set2.add(2);
System.out.println("Set2: " + set2); // 控制台打印:Set2: [1, 2]
//两个集合的并集
set2.addAll(set1);
System.out.println("并集是: " + set2);// 控制台打印:并集是: [1, 2, 3]
}
}Set内容补充(在工作中很常用!)
- 为了得到两个集合x和y的并集,我们可以使用x.addAll(y)
- 要获得两个集合x和y的交集,我们可以使用x.retainAll(y)
- 要检查x是否是y的子集,我们可以使用y.containsAll(x)
2.3、List有序集合
- List是一个有序的集合,可存储相同的元素。
- List本身是一个接口类无法实例化,可通过它的子类实现来实例化
- List的子类实现类如下
- ArrayList:底层采用数组数据结构,非线程安全,按照顺序存储元素,可通过元素下标获取元素。
- LinkedList:链表结构,链表中的元素不按照顺序存储,链表中的元素又称节点,节点之间通过prev,next链接
- prev当前存储元素的上一个元素(第一个元素为null)
- next当前存储元素的下一个元素(最后一个元素为null)
- Vector(底层使用数组,线程安全,但在实际工作中使用较少)
- List的实现类ArrayList无需像普通数组那样声明空间大小,ArrayList数组空间的大小是动态调整的,根据存放元素的多少自动增减。
2.3.1、实现ArrayList
- ArrayList底层是一个Object类型的数组,是非线程安全的。
- ArrayList的数组大小是动态的,它的默认初始容量是10。
- ArrayList构造方法可以指定初始化容量。
- ArrayList容量不够时,会自动按照当前容量的1.5倍进行扩容,扩容的本质是创建一个更大的新数组,并将旧数组数据复制到新数组中,程序运行效率会受到一定影响。
- 具体扩容计算规则:newCapacity = oldCapacity + (oldCapacity >> 1)。
- 数组扩容的效率较低,所以在创建ArrayList时尽量给定一个合适的初始化容量,可以很大程度上避免数组的重复扩容,提高性能。
- 存储的元素可重复,并支持null元素的存储,且维护插入顺序(每个元素拥有对应的下标)。
- 可以通过元素下标快速访问对应元素(查找效率高),也可以for循环查找。
- 数组优点
- 数组的检索效率很高
- 缺点:
- 1. 数组元素随机的增删效率较低(数组末尾的增删除外),数组扩容效率较低。
- 2. 数组存不了大量数据,因为数组在内存中是连续的,很难找到一块很大的连续空间。
- 3. ArrayList是非线程安全的。
ArrayList构造函数
| 构造函数 | 说明 |
| ArrayList() | 创建一个默认容量为10的空列表。 |
| ArrayList(int initialCapacity) | 创建一个初始容量为initialCapacity的空列表。(推荐此种方式创建) |
| ArrayList(Collection c) | 创建一个包含指定集合的元素的列表,这些元素按照集合的迭代器返回的顺序排列。 |
ArrayList常用函数
| 函数 | 说明 |
| clone() | 创建具有相同元素、大小和容量的新数组列表。 |
| contains() | 在数组列表中搜索指定的元素并返回一个布尔值。 |
| qnsureCapacity() | 指定数组列表可以包含的总元素。 |
| isEmpty() | 检查数组列表是否为空。 |
| indexOf() | 在数组列表中搜索指定的元素,并返回该元素的索引。 |
| trimToSize() | 将数组列表的容量减少到当前大小。 |
| set(int index, E element) | 用指定元素替换指定位置的元素。 |
| get(int index) | 返回指定位置的元素。 |
| add(E e) | 将指定的元素添加到列表的末尾。 |
| add(int index, E element) | 在指定位置插入元素,后面的元素依次后移。 |
| addAll() | 将一个数组列表的元素添加到另一个数组列表 |
| clear() | 移除列表中的所有元素。 |
| size() | 返回列表中的元素数量。 |
| toArray() | 将列表中的元素转换为数组。 |
| lastIndexOf(Object o) | 返回列表中最后一次出现的指定元素的索引。 |
| remove(Object o) | 移除列表中第一次出现的指定元素,并返回被移除的元素。 |
| remove(int index) | 移除指定位置的元素,并返回被移除的元素。后面的元素依次前移。 |
ArrayList基础函数使用
import java.util.ArrayList;
class Test {
public static void main(String[] args){
ArrayList<String> arr = new ArrayList<>();
// 1.添加元素
arr.add("Dog");
arr.add("Cat");
arr.add(2,"Horse"); // 通过下标索引插入一个元素,下标索引从0开始
System.out.println("ArrayList: " + arr);
// 输出结果
// ArrayList: [Dog, Cat, Horse]
// 2.从列表中访问元素:通过元素下标访问,元素下标从0开始
String item = arr.get(2);
System.out.println("访问元素:" + item);
// 输出结果
// 访问元素:Horse
// 3.将一个数组列表的元素添加至另一个数组列表
// 创建一个新数组
ArrayList<String> arr2 = new ArrayList<>();
arr2.add("fish");
arr.addAll(arr2);// 使用addAll() 添加元素
System.out.println("ArrayList: " + arr);
// 输出结果
// ArrayList: [Dog, Cat, Horse, fish]
// 4.使用set更改ArrayList元素
arr.set(2, "Apple");
System.out.println("修改后的ArrayList: " + animals);
// 输出结果
// 修改后的ArrayList:[Dog, Cat, Apple, fish]
// 5.使用remove删除ArrayList元素
String str = arr.remove(2);
System.out.println("删除后的ArrayList: " + animals);
System.out.println("删除元素: " + str);
// 输出结果
// 删除后的ArrayList: [Dog, Cat, fish]
// 6.使用size获取数组的长度
System.out.println("数组长度: " + arr.size());
// 输出结果
// 数组长度: 3
// 7.使用clear清除所有元素
arr.clear()
System.out.println("删除后的ArrayList: " + arr);
// 输出结果
// 删除后的ArrayList: []
}
}遍历ArrayList数组
class Test {
public static void main(String[] args) {
//创建数组列表
ArrayList<String> arr = new ArrayList<>();
arr.add("Cow");
arr.add("Cat");
arr.add("Dog");
System.out.println("ArrayList: " + arr);
//使用for循环
System.out.println("访问所有元素: ");
for(int i = 0; i < arr.size(); i++) {
System.out.print(arr.get(i));
System.out.print(", ");
}
//使用 forEach 循环
for(String item : arr) {
System.out.print(item);
System.out.print(", ");
}
}
}将Array转化为ArrayList
import java.util.ArrayList;
import java.util.Arrays;
class Test {
public static void main(String[] args) {
//创建一个字符串类型的数组
String[] arr = {"Dog", "Cat", "Horse"};
//从数组创建ArrayList
//Arrays是一个工具类,提供对ArrayList的函数方法
//Arrays.asList代码行的意思是将数组转化为ArrayList
ArrayList<String> animals = new ArrayList<>(Arrays.asList(arr));
}
}数组排序
这里只对数组排序做简单说明,实际业务场景中会遇到更多复杂的排序,有兴趣可以在网上查阅资料深入了解
import java.util.ArrayList;
import java.util.Collections;
class Test {
public static void main(String[] args){
ArrayList<String> arr= new ArrayList<>();
//在数组列表中添加元素
arr.add("Horse");
arr.add("Zebra");
arr.add("Dog");
arr.add("Cat");
System.out.println("未排序的ArrayList: " + arr);
//对数组列表进行排序
//Collections是Java内置的工具类,sort表示排序
Collections.sort(arr);
System.out.println("排序后的ArrayList: " + arr);
// 控制台输出结果
// 未排序的ArrayList: [Horse, Zebra, Dog, Cat]
// 排序后的ArrayList: [Cat, Dog, Horse, Zebra]
}
}2.3.2、实现LinkedList
- LinkedList的底层是双向链表结构,LinkedList中的每个元素又称节点
- LinkedList的每个节点都包含三个元素,分别为prev(前继指针),Data(节点存储元素),next(后继指针)
- prev
- data
- next
- LinkedList是非线程安全的,多线程环境需要使用同步或者并发集合
- LinkedList优点
- 因其链表结构的特点,LinkedList具备高效的头部尾部操作。
- 在已知位置(尤其是列表中间或开头)插入和删除元素比 ArrayList 更快(移动指针比移动大批数组元素快)
- 顺序访问快;适合做队列、堆栈、双端队列。
- LinkedList缺点
- 索引访问慢,占用内存比ArrayList多
LinkedList构造函数说明
| 构造方法 | 说明 |
| LinkedList() | 创建一个空列表。 |
| LinkedList(Collection c) | 创建一个包含指定集合元素的列表,元素的顺序由集合的迭代器返回顺序决定。 |
LinkedList常用函数说明
| 方法名称 | 说明 | 备注 |
| boolean add(E e) | 在列表尾部添加指定元素。等价于addLast(e)。 | |
| void add(int index, E element) | 在列表的指定索引位置插入指定元素。将当前在该位置的元素(如果有)和任何后续元素右移(索引增加 1)。 | 效率较低(通常 O(n)),需要先找到位置。 |
| boolean addAll(Collection c) | 按指定集合的迭代器返回的顺序,在列表尾部添加所有元素。 | |
| boolean addAll(int index, Collection c) | 从指定index索引位置开始,按指定集合的迭代器返回的顺序,插入所有元素。 | 效率较低(通常 O(n)),需要先找到位置。 |
| void addFirst(E e) | 在列表开头插入指定元素。 | 高效 O(1) |
| void addLast(E e) | 在列表尾部添加指定元素。等价于add(e)。 | 高效 O(1) |
| boolean offer(E e) | 在列表尾部添加指定元素(建议用于队列)。等价于add(e)/addLast(e)。 | 高效 O(1) |
| boolean offerFirst(E e) | 在列表开头插入指定元素(建议用于双端队列)。 | 高效 O(1) |
| boolean offerLast(E e) | 在列表尾部添加指定元素(建议用于双端队列)。等价于offer(e)/addLast(e)。 | 高效 O(1) |
| void push(E e) | 将元素推入此列表表示的堆栈顶部(在列表开头插入)。等价于addFirst(e)。 | 高效 O(1) |
| E remove() | 移除并返回列表的头部(第一个)元素(建议用于队列)。等价于removeFirst()。 | 列表为空时抛出NoSuchElementException。 高效 O(1) |
| E remove(int index) | 移除并返回列表指定索引位置的元素。 | 效率较低(通常 O(n)),需要先找到位置。 |
| boolean remove(Object o) | 移除列表中首次出现的指定元素(如果存在)。 | 需要遍历查找。 |
| E removeFirst() | 移除并返回列表的第一个元素。 | 列表为空时抛出NoSuchElementException。高效 O(1) |
| E removeLast() | 移除并返回列表的最后一个元素。 | 列表为空时抛出NoSuchElementException。高效 O(1) |
| boolean removeFirstOccurrence(Object o) | 从列表开头向结尾搜索,移除列表中首次出现的指定元素。等同于remove(o)。 | 需要遍历查找。 |
| boolean removeLastOccurrence(Object o) | 从列表结尾向开头搜索,移除列表中最后一次出现的指定元素。 | 需要遍历查找。 |
| E poll() | 移除并返回列表的头部(第一个)元素(队列操作)。如果列表为空,则返回null。 | 高效 O(1) |
| E pollFirst() | 移除并返回列表的第一个元素。如果列表为空,则返回null。 | 高效 O(1) |
| E pollLast() | 移除并返回列表的最后一个元素。如果列表为空,则返回null。 | 高效 O(1) |
| E pop() | 从此列表表示的堆栈中弹出一个元素(移除并返回第一个元素)。等价于removeFirst()。 | 高效 O(1) |
| void clear() | 移除列表中的所有元素。 | |
| E element() | 获取但不移除列表的头部(第一个)元素。 | 列表为空时抛出NoSuchElementException。 高效 O(1) |
| E get(int index) | 返回列表指定索引位置的元素。 | 效率较低 O(n),需要遍历到指定位置。不推荐随机访问! |
| E getFirst() | 返回列表的第一个元素。 | 列表为空时抛出NoSuchElementException。 高效 O(1) |
| E getLast() | 返回列表的最后一个元素。 | 列表为空时抛出NoSuchElementException。 高效 O(1) |
| E peek() | 获取但不移除列表的头部(第一个)元素。如果列表为空,则返回null。 | 高效 O(1) |
| E peekFirst() | 获取但不移除列表的第一个元素。如果列表为空,则返回null。 | 高效 O(1) |
| E peekLast() | 获取但不移除列表的最后一个元素。如果列表为空,则返回null。 | 高效 O(1) |
| E set(int index, E element) | 替换列表指定索引位置的元素为指定的元素。 | 效率较低 O(n),需要先找到位置。返回被替换的元素。 |
| int size() | 返回列表中的元素数量。 | 高效 O(1)(LinkedList 维护 size 计数器) |
| boolean isEmpty() | 返回列表是否为空(不包含任何元素)。 | 高效 O(1) |
| boolean contains(Object o) | 返回列表是否包含指定元素。 | 需要遍历查找。 |
| int indexOf(Object o) | 返回指定元素在列表中首次出现的索引;如果列表不包含该元素,则返回-1。 | 从开头向结尾搜索。需要遍历。 |
| int lastIndexOf(Object o) | 返回指定元素在列表中最后一次出现的索引;如果列表不包含该元素,则返回-1。 | 从结尾向开头搜索。需要遍历。 |
| Object[] toArray() | 返回一个按正确顺序(从第一个元素到最后一个元素)包含此列表中所有元素的数组。 | |
| T[] toArray(T[] a) | 返回一个按正确顺序包含此列表中所有元素的数组;返回数组的运行时类型是指定数组的类型。如果指定数组能容纳列表,则使用该数组,否则分配新数组。 | |
| Iterator iterator() | 返回此列表中元素的按正确顺序(从第一个到最后一个)进行迭代的迭代器。 | |
| ListIterator listIterator() | 返回此列表中元素的(按正确顺序)列表迭代器(从指定位置开始默认为 0)。 | |
| ListIterator listIterator(int index) | 返回此列表中元素的(按正确顺序)列表迭代器,从列表中指定位置开始。 | 初始时调用next将返回索引为index的元素。 |
| List subList(int fromIndex, int toIndex) | 返回此列表中指定的fromIndex(包括)和toIndex(不包括)之间的部分的视图。 | 此视图上的操作会反映在原始列表上。 |
| boolean containsAll(Collection c) | 返回列表是否包含指定集合中的所有元素。 | |
| boolean removeAll(Collection c) | 移除列表中所有也包含在指定集合中的元素(取差集)。 | |
| boolean retainAll(Collection c) | 仅保留列表中也包含在指定集合中的元素(取交集)。 | |
| Spliterator spliterator() | 创建此列表中元素的Spliterator。 | JDK 8+ |
| LinkedList clone() | 返回此LinkedList实例的浅拷贝。 | 元素本身不被复制。 |
| void sort(Comparator c) | 根据指定的 Comparator 对列表进行排序。 |
代码案例
双端操作,接口函数方法
import java.util.LinkedList;
public class DequeExample {
public static void main(String[] args) {
// 创建一个LinkedList
LinkedList<String> deque = new LinkedList<>();
// 添加元素到两端
deque.addFirst("前端"); // 头部添加
deque.addLast("后端"); // 尾部添加
deque.offerFirst("数据库"); // 头部添加(安全方法)
deque.offer("中间件"); // 尾部添加(队列风格)
deque.push("缓存"); // 头部添加(栈风格)
System.out.println("当前队列: " + deque);
// 输出: [缓存, 数据库, 前端, 后端, 中间件]
// 查看但不移除
System.out.println("头部元素: " + deque.peekFirst()); // 缓存
System.out.println("尾部元素: " + deque.peekLast()); // 中间件
// 移除操作
System.out.println("移除头部: " + deque.pop()); // 缓存 (栈风格)
System.out.println("移除尾部: " + deque.pollLast()); // 中间件
// 最终队列状态
System.out.println("剩余元素: " + deque); // [数据库, 前端, 后端]
}
}列表的操作与索引访问
import java.util.LinkedList;
public class ListOperations {
public static void main(String[] args) {
LinkedList<String> languages = new LinkedList<>();
languages.add("Java");
languages.add("Python");
languages.add(1, "JavaScript"); // 在索引1处插入
System.out.println("初始列表: " + languages);
// 输出: [Java, JavaScript, Python]
// 访问元素
System.out.println("索引1的元素: " + languages.get(1)); // JavaScript
// 修改元素
languages.set(0, "Kotlin");
System.out.println("修改后: " + languages); // [Kotlin, JavaScript, Python]
// 查找操作
// indexOf
System.out.println("Python位置: " + languages.indexOf("Python")); // 2
System.out.println("包含C++? " + languages.contains("C++")); // false
// 移除元素
languages.remove(1); // 移除索引1
languages.remove("Python"); // 移除指定元素
System.out.println("最终列表: " + languages); // [Kotlin]
}
}作为队列和栈使用
import java.util.LinkedList;
public class QueueStackExample {
public static void main(String[] args) {
// 作为队列使用 (先进先出)
System.out.println("=== 队列行为 ===");
LinkedList<Integer> queue = new LinkedList<>();
queue.offer(10); // 入队
queue.offer(20);
queue.offer(30);
while(!queue.isEmpty()) {
System.out.println("出队: " + queue.poll());
}
// 输出: 10 → 20 → 30
// 作为栈使用 (后进先出)
System.out.println("\n=== 栈行为 ===");
LinkedList<Integer> stack = new LinkedList<>();
stack.push(100); // 压栈
stack.push(200);
stack.push(300);
while(!stack.isEmpty()) {
System.out.println("弹栈: " + stack.pop());
}
// 输出: 300 → 200 → 100
}
}三、Map键值对
- Map是一种键值对存储的数据结构,其中键值不可重复(重复键值会覆盖旧值)
- 键和值可为任意对象(包括null,部分实现类会限制null值)
- Map是一种无序结构,个别实现类提供有序存储(TreeMap,LinkedHashMap)
Map接口类的子类实现类(性能对比)
本文仅对常用的HashMap和Hashtable做深入探讨
Hashtable在函数使用上与HashMap几乎一致,于此文中也不在赘述,感兴趣的同学可以查阅网上资料深入了解。
| 实现类 | 数据结构 | 顺序保证 | 允许Null键/值 | 线程安全 | 时间复杂度 |
| HashMap | 数组+链表/红黑树 | 无序 | 允许 | 否 | 平均O(1) |
| LinkedHashMap | 链表+哈希表 | 按插入或访问顺序 | 允许 | 否 | O(1) |
| TreeMap | 红黑树 | 按键自然排序/自定义 | 键不能为null | 否 | O(log n) |
| Hashtable | 数组+链表 | 无序 | 不允许 | 是(锁全表) | O(1) |
| ConcurrentHashMap | 分段数组+链表 | 无序 | 不允许 | 是(分段锁) | 平均O(1) |
Map接口类的核心函数
| 方法签名 | 返回类型 | 描述 |
| int size() | int | 返回Map中键值对的数量 |
| boolean isEmpty() | boolean | 如果Map中没有键值对则返回true |
| boolean containsKey(Object key) | boolean | 如果Map包含指定键则返回true |
| boolean containsValue(Object value) | boolean | 如果Map包含至少一个指定值的映射则返回true |
| V get(Object key) | V | 返回指定键所映射的值,如果Map不包含该键则返回null |
| V put(K key, V value) | V | 将键值对放入Map。如果键已存在,则替换旧值并返回旧值;否则返回null |
| V remove(Object key) | V | 根据键删除映射,并返回被删除的值。如果键不存在则返回null |
| void putAll(Map m) | void | 将指定Map中的所有映射复制到此Map |
| void clear() | void | 清空Map中的所有映射 |
| Set keySet() | Set | 返回Map中所有键组成的Set视图(因为键唯一) |
| Collection values() | Collection | 返回Map中所有值组成的Collection视图(值可能重复) |
| Set> entrySet() | Set> | 返回Map中所有键值对(Map.Entry对象)组成的Set视图 |
| default V getOrDefault(Object key, V defaultValue) | V | 如果键存在则返回值,否则返回默认值(Java 8+) |
| default V putIfAbsent(K key, V value) | V | 如果键不存在(或映射为null),则将键值对加入,否则返回当前值(Java 8+) |
| default boolean remove(Object key, Object value) | boolean | 仅当键映射到指定值时才移除该映射(Java 8+) |
| default boolean replace(K key, V oldValue, V newValue) | boolean | 仅当键映射到指定值时才替换新值(Java 8+) |
| default V replace(K key, V value) | V | 如果键存在,则替换值并返回原值,否则返回 null(Java 8+) |
| default void replaceAll(BiFunction function) | void | 对每个条目执行函数替换值(Java 8+) |
| default V merge(K key, V value, BiFunction remappingFunction) | V | 合并操作(Java 8+) |
| default V compute(K key, BiFunction remappingFunction) | V | 计算新值(Java 8+) |
| default V computeIfAbsent(K key, Function mappingFunction) | V | 若键不存在或值为null,则通过函数计算新值(Java 8+) |
| default V computeIfPresent(K key, BiFunction remappingFunction) | V | 键存在且非null时计算新值(Java 8+) |
| boolean equals(Object o) | boolean | 比较Map与指定对象是否相等(比较键值对) |
| int hashCode() | int | 返回Map的哈希码 |
3.1、实现HashMap
- HashMap允许null键和null值(Hashtable不允许)
- 非线程安全,多线程环境下需外部同步(或使用ConcurrentHashMap)
- 默认初始容量16,加载因子0.75,扩容时翻倍(2的幂次方,当元素数量超过容量*加载因子时,扩容并重新计算哈希)
- 插入顺序不保证遍历顺序(LinkedHashMap可保证)
- HashMap在实际开发场景中常用来作配置或者直接参与数据处理
HashMap构造函数
- 加载因子:用于确定何时扩容,默认0.75表示当HashMap中的元素数量超过容量*0.75时,哈希表会进行扩容(rehash),容量翻倍。
- 异常:
- 如果指定的初始容量为负数,抛出IllegalArgumentException。
- 如果指定的加载因子小于等于0或者为NaN(非数字),同样抛出IllegalArgumentException。
| 构造函数 | 参数 | 默认值 | 功能描述 | 使用场景与注意事项 |
| HashMap() | 无 | 初始容量:16 加载因子:0.75 | 创建默认配置的HashMap | 最常用初始化方式,适合无特殊要求的场景 |
| HashMap(int initialCapacity) | initialCapacity :初始容量 | 加载因子:0.75 | 创建指定初始容量的空HashMap | 预分配优化:容量 ≥ (元素数/0.75) |
| HashMap(int initialCapacity, float loadFactor) | initialCapacity:初始容量 loadFactor:加载因子 | 无 | 自定义初始容量和扩容阈值因子 | 精确控制扩容行为loadFactor范围:0 < loadFactor ≤ Float.MAX_VALUE |
| HashMap(Map m) | m:源Map对象 | 初始容量:max(m.size()/0.75 + 1, 16) 加载因子:0.75 | 复制已有Map的所有键值对 | 高效克隆Map,等价于new HashMap() + putAll() |
HashMap常用函数
| 方法签名 | 返回值类型 | 功能描述 | 示例 |
| 基础操作 | |||
| V put(K key, V value) | V | 将指定键值对存入Map。若键已存在,则替换旧值并返回旧值;若键不存在,则存入并返回null。 | map.put("a", 1); // 返回null map.put("a", 2); // 返回1 |
| V get(Object key) | V | 根据键获取对应的值。若键不存在,返回null。 | map.get("a"); // 返回2 |
| V remove(Object key) | V | 根据键删除键值对,并返回被删除的值。若键不存在,返回null。 | map.remove("a"); // 返回2 |
| void clear() | void | 清空Map中的所有键值对。 | map.clear(); |
| int size() | int | 返回Map中键值对的数量。 | map.size(); // 返回0 |
| boolean isEmpty() | boolean | 判断Map是否为空。 | map.isEmpty(); // 返回true |
| 检查方法 | |||
| boolean containsKey(Object key) | boolean | 判断Map中是否包含指定的键。 | map.containsKey("a"); // false |
| boolean containsValue(Object value) | boolean | 判断Map中是否包含指定的值。 | map.containsValue(2); // false |
| 视图方法 | |||
| Set keySet() | Set | 返回Map中所有键组成的Set视图。 | Set keys = map.keySet(); |
| Collection values() | Collection | 返回Map中所有值组成的Collection视图。 | Collection values = map.values(); |
| Set> entrySet() | Set> | 返回Map中所有键值对(Entry)组成的Set视图。 | Set> entries = map.entrySet(); |
| Java 8+ 增强方法 | |||
| V getOrDefault(Object key, V defaultValue) | V | 安全获取值,当键不存在时返回指定的默认值。 | map.getOrDefault("a", 0); // 返回0 |
| V putIfAbsent(K key, V value) | V | 仅当键不存在(或映射值为null)时,才将键值对存入Map,并返回当前键对应的值(若存入则返回null,否则返回旧值)。 | map.putIfAbsent("a", 1); // 返回null,并存入 map.putIfAbsent("a", 2); // 返回1,不存入 |
| boolean remove(Object key, Object value) | boolean | 仅当键和值都匹配时,才移除该键值对。成功移除返回true,否则false。 | map.remove("a", 1); // true |
| boolean replace(K key, V oldValue, V newValue) | boolean | 仅当键和旧值都匹配时,才将键对应的值替换为新值。替换成功返回true,否则false。 | map.replace("a", 1, 2); // true |
| V replace(K key, V value) | V | 替换指定键对应的值(仅当键存在时)。返回旧值,若键不存在返回null。 | map.replace("a", 3); // 返回2,map变为{"a":3} |
| void replaceAll(BiFunction function) | void | 根据给定的函数替换所有键对应的值。 | map.replaceAll((k,v) -> v * 2); // {"a":6} |
| V compute(K key, BiFunction remappingFunction) | V | 根据键和计算函数重新计算新值并替换旧值(无论键是否存在)。函数返回值不能为null(否则会删除该键值对)。 | map.compute("a", (k,v) -> v+1); // {"a":7} |
| V computeIfAbsent(K key, Function mappingFunction) | V | 当键不存在(或映射值为null)时,使用函数生成新值并存入,返回新值;若键存在,直接返回旧值。 | map.computeIfAbsent("b", k -> 10); // 存入{"b":10}并返回10 |
| V computeIfPresent(K key, BiFunction remappingFunction) | V | 当键存在且非null时,通过函数计算新值并替换旧值,返回新值(若函数返回null,则删除该键值对并返回null);键不存在返回null。 | map.computeIfPresent("b", (k,v) -> v*2); // {"b":20} 返回20 |
| V merge(K key, V value, BiFunction remappingFunction) | V | 合并:若键不存在或值为null,则存入指定value;若键存在,则用函数合并旧值和新值(若函数返回null,则删除该键值对)。 | map.merge("b", 5, (oldVal, newVal) -> oldVal + newVal); // 25 |
HashMap函数基础操作
import java.util.*;
public class HashMapDemo {
public static void main(String[] args) {
// 1. 创建与初始化
HashMap<String, Integer> scores = new HashMap<>();
scores.put("Alice", 90); // 添加元素
scores.put("Bob", 85);
scores.put("Charlie", 92);
// 2. 基础操作
System.out.println("Bob's score: " + scores.get("Bob")); // 获取值 → 85
System.out.println("Remove: " + scores.remove("Bob")); // 删除 → 85
// 验证是否存在key值“Alice”
System.out.println("Contains Alice? " + scores.containsKey("Alice")); // true
System.out.println("Size: " + scores.size()); // 2
}
}
HashMap视图遍历
import java.util.*;
public class HashMapDemo {
public static void main(String[] args) {
// 1. 创建与初始化
HashMap<String, Integer> scores = new HashMap<>();
scores.put("Alice", 90); // 添加元素
scores.put("Bob", 85);
scores.put("Charlie", 92);
// 3. 键值遍历
System.out.println("\n=== Keys ===");
for (String name : scores.keySet()) {
System.out.println(name);
}
// 4. 值遍历
System.out.println("\n=== Values ===");
for (int score : scores.values()) {
System.out.println(score);
}
// 5. 键值对遍历
System.out.println("\n=== Entries ===");
for (Map.Entry<String, Integer> entry : scores.entrySet()) {
System.out.println(entry.getKey() + ": " + entry.getValue());
// 修改值(直接更新Map)
if (entry.getKey().equals("Charlie")) {
entry.setValue(95); // 原始map同步更新
}
}
}
}四、完结
10000多字,真写死我了,部分资料查阅自网络,按照个人理解将其输出成方便同学理解的文字。且看且珍惜。
写了一个上午+下午,真心创作不易,点个赞吧看官老爷们。
少年就是少年,遇春风不喜,夏蝉不烦,秋风不悲,冬雪不叹。
但我更情愿你别成为这样的少年。
愿你遇春风欣喜,夏蝉烦扰,伤秋感春,悲叹冬雪。
如此才像少年。
也祝你历经半生,归来仍是这样一少年。
加油。
别放弃。
即使乾坤已定,你我仍有无限可能。
用一生的时间去追寻心中那遥不可及的答案。


















 1332
1332

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











