




 本文提出一种新的大规模词义消歧(WSD)方法,基于牛津词典构建的大数据集,涵盖所有已知词义,解决了词义上下文信息不平衡问题,尤其提升了罕见词义的预测准确性。
本文提出一种新的大规模词义消歧(WSD)方法,基于牛津词典构建的大数据集,涵盖所有已知词义,解决了词义上下文信息不平衡问题,尤其提升了罕见词义的预测准确性。
介绍:
尽管最近的研究证明了神经语言模型的优越性,但是WSD研究的范围仍然是几个单词的意义只能在几个领域中确定。因此,有必要朝着开发一个高度可扩展的过程的方向发展,这个过程可以处理在不同领域中出现的词义(当WSD数据集中的单词数量增加时,必须创建一个新的WSD分类器)。
论文的主要贡献:
- 介绍了一个新的大数据集,它是由牛津词典自动构建的,被广泛用作词义的标准来源;
大部分的WSD数据集:部分含义;
论文的WSD数据集:所有已知含义;没有构建成本;数据质量有保障;所有领域可用。 - 提出了一个新的词义消歧模型,它根据词在上下文中的词性来单独确定词义;
解决了平衡性问题——常用词义往往有相对较多的例句,但很少遇到词义却可能有很少的例句,从而导致很难学到稀有词的精确上下文信息;对单词的罕见语义有更高的准确性; - 引入了一种混合词义预测方法,该方法对不常用的词义进行单独分类,以获得合理的性能。
混合词义预测方法,即将一个词的稀有含义与其他经常遇到的意义分别分类。这就提高了预测的准确性,即使词义的上下文信息中含有相对较少的例句而导致的词义含糊不清。
论文进行了比较实验,以证明与基准方法相比,作者提出的方法更可靠。此外作者还研究了该方法在现实环境中使用新闻文章的适应性。
要把WSD的成果商业化,就必须在广泛的领域内处理大部分词语及其含义;这些领域包括信息检索、机器翻译,甚至是使用各种资源(如电影和书籍)的第二语言教育。
相关工作:
WSD的一般方法:
- 监督方法:通常利用一组有效的特征,这些特征将词义分类并创建一个分类模型来学习这个集合;
优点:性能最佳;
缺点:代价昂贵;不可能构建一个包含每个词的所有含义的数据集;
性能主要取决于数据质量; - 基于知识的方法:利用外部词汇知识库(如:WordNet、BabeNet);
优点:不需要依赖于人工整理的知识资源中的人工注释数据。
缺点:性能并未由于监督方法。
以往的研究:很大程度上依赖于单词在上下文中正确表达语义信息的能力。在过去,一个单词被映射到它对应的向量,1:1对应,使用一个固定的单词表示,如Word2Vec [25], GloVe[33],或FastText[2]。固定的单词表示,无论其意义是什么,都表达了相同的词的嵌入,换句话说,这种方法总是产生相同表示的向量,表示相同的含义,即使它们在上下文中的意义不同。因此,考虑歧义词语的固定词表征和语境信息是不合理的。
最近的研究:
基于上下文词嵌入的神经语言模型提出了根据上下文对有不同含义的词进行分别表示。上下文词嵌入对WSD有显著的积极影响。[24]报告了一个监督WSD任务的重要结果,该任务使用双向长短期记忆(BiLSTM)从目标词周围的可变长句子上下文的嵌入中获取目标词的上下文信息。
从那时起
最新的语言模型,如ELMo[34]和BERT[24],已经成功地在监督的WSD任务中执行了更复杂的上下文化单词嵌入。
优点:适用于现有研究的数据集——单词的每一个含义提供的例句数量充分,且各个含义之间的分布是相当的;
缺点:本文的数据集某些词没有足够的例句来训练高性能神经语言模型——在学习稀有词词义时性能不好;
性能:取决于神经网络语言模型的性能
用于WSD的牛津数据集:
数据预处理:
- 删除只有一个sense ID的所有例句;
- 删除所有不属于预定义的词性标签列表中的词义的例句;
- 对于一个单词的每一个词性标注标签,最大的词义数量限制在20个,其余的删除;
- 删除所有超过50个单词或少于5个单词的例句。
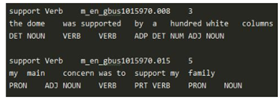

数据集缺点:某些词的实际应用较少,没有包含足够的例句来训练最新的高性能的神经语言模型。
不同单词的词义有不同数量的例句,这取决于它们在真实环境中的使用频率;因此,神经语言模型在学习稀有词义的完全不同的上下文信息时会遇到困难。
数据集优点:包含单词的所有已知含义;没有构建成本;数据质量有保障;所有领域可用。
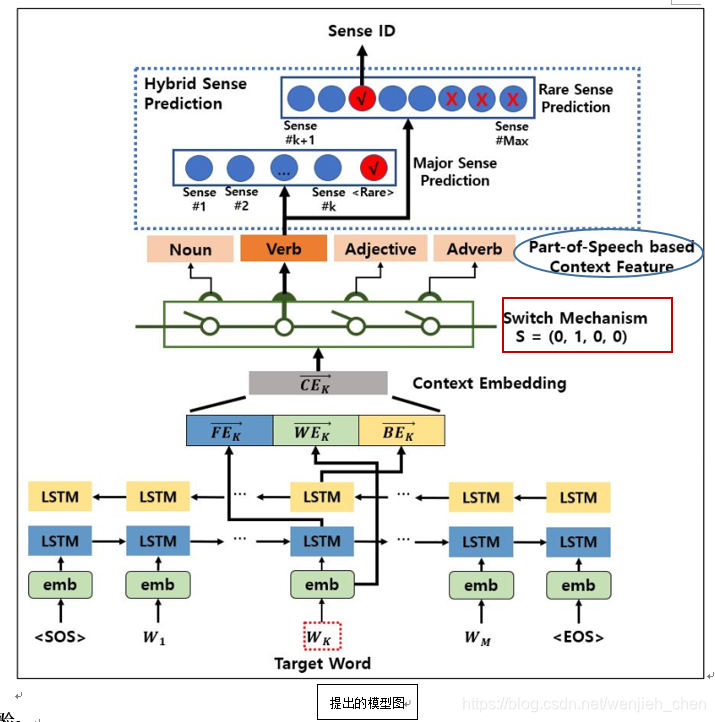
提出的WSD模型:
以一个例句为例,模型通过以下三个步骤预测目标词的词义:
(1)首先使用双向LSTM生成一个代表目标词上下文信息的上下文嵌入(〖CE〗_k ) ⃗;
(2)它使用一个转换机制来提供一个依赖于例句中目标词的词性的上下文特征;
(3)它执行混合预测计算的可能性分别罕见的感官时前面的预测表明,某种意义上属于<罕见>,这是一个象征“罕见的意义。
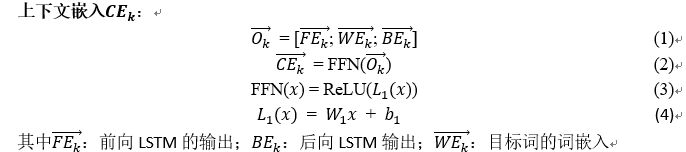
FFN为前馈神经网络,ReLU为修正的线性单元Rectified Linear Unit [11],将单词嵌入的维数、BiLSTM的隐藏单位和FFN的隐藏大小设为300。


实验:
**实验设置:**
论文从公开可用的牛津词典中为WSD开发了新的数据集。数据集由765,145个句子组成,每个句子都包含一个有歧义的词,并且标注了它的词义和词性。训练集、验证集、测试集包含的句子数如下表:

another测试集:News Test(华尔街日报中随机抽取的3072 news articles,人工标注相关的Sense ID)——在更真实的环境下验证本文的模型的性能。
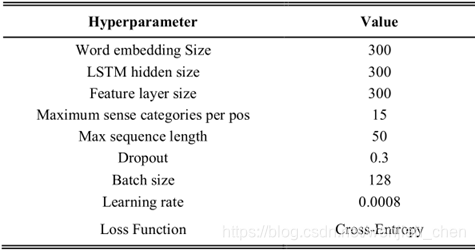
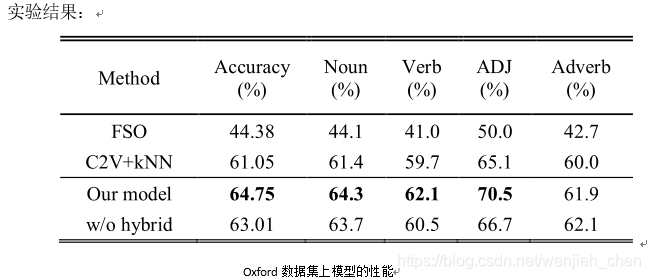
上图表明,在基于牛津词典的WSD数据集上,我们提出的系统比两种比较模型的性能要好。这表明,根据词性分别预测词义的方法在语义歧义程度较高的数据上是可行的。通过与FSO方法的对比可以明显看出,WSD对上下文中词语的语义分析要比简单匹配方法准确得多。此外,我们提出的模型比仅根据上下文嵌入的相似性确定单词词义的context2vec模型的准确率高出3.7%。由于两种方法都给出了从双向LSTM获取目标词上下文嵌入的相似方法,因此可以强调,性能差异源于我们的基于词性的词义分类方法。
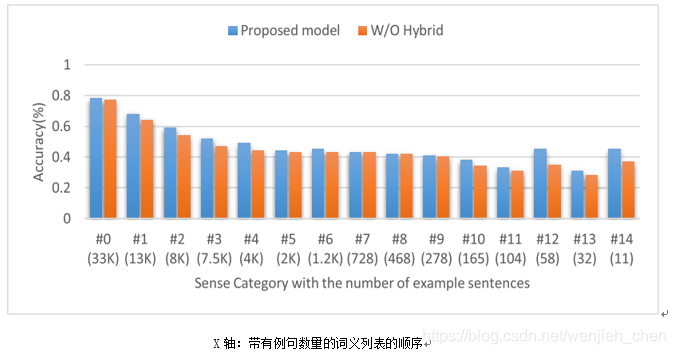
可以看出,整体的准确率趋势会随着词典中词义的顺序而下降,也可以看出混合预测方法有助于提高分类准确率。特别是,这种稀有感觉的准确性得到了更明显的提高。
由于每种语义的例句数量存在显著差异,因此上下文特征仍然包含来自神经语言模型的错误。尽管如此,这种结果可以通过单独预测稀有词义来弥补。因此,混合词义分类方法对于不常用的词义预测性能起到了一定的补偿性作用。
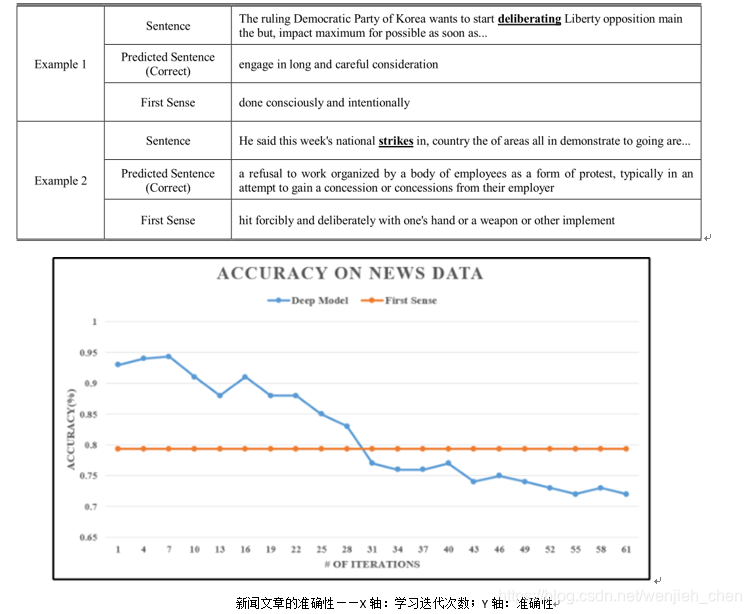
First Sense in the News Test:79.36%;这个数字相对较高,因为现实生活中的使用频率在字典中实现的较少。
尽管在七次学习迭代后,本文的模型达到了94.33%的准确率,但是随着迭代次数的增加,性能下降。
总而言之,本文的模型可以有效地解决第二语言学生或翻译者在语境中准确识别单词含义的问题
结论:
- 提出一种新的可以处理通用大规模数据集的WSD体系结构;
- 引进一个新的WSD数据集——从Oxford Dictionary(经过认证且高度可靠、词义识别的标准来源之一)自动构建;
尽管现有的研究已经显示出相当大的成功,但是由于训练数据的局限性,它们只覆盖了有限的几个领域,因此存在一个门槛。相比之下,本文提出的模型可以处理范围广泛的文本,这扩展了它的能力,并使其在如第二语言教育、医学等各种应用中取得成功。
在未来,将扩展其工作,加入多模式数据,如图像或音频。这应该最终允许我们扩展我们的模型的能力,以利用各种格式的内容。
reference:
[1]. Y. Heo, S. Kang and J. Seo, “Hybrid Sense Classification Method for Large-Scale Word Sense Disambiguation,” in IEEE Access, vol. 8, pp. 27247-27256, 2020, doi: 10.1109/ACCESS.2020.2970436

















 1083
1083

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









