






1、Q-Q图是什么
QQ图,或称Quantile-Quantile图,是一种可视化工具。
统计学里Q-Q图(Q代表分位数)是一个概率图,用图形的方式比较两个概率分布,把他们的两个分位数放在一起比较。首先选好分位数间隔。图上的点(x,y)反映出其中一个第二个分布(y坐标)的分位数和与之对应的第一分布(x坐标)的相同分位数。因此,这条线是一条以分位数间隔为参数的曲线。
如果两个分布相似,则该Q-Q图趋近于落在y=x线上。如果两分布线性相关,则点在Q-Q图上趋近于落在一条直线上,但不一定在y=x线上。Q-Q图可以用来可在分布的位置-尺度范畴上可视化的评估参数。
用于确定一个样品:
- 是否从遵循特定概率分布(通常是正态分布)的群体中抽取。
- 与另一个样品遵循相同的分布。
QQ图提供了强大的可视化评估功能,可精确定位分布之间的偏差,并确定造成偏差的数据点。将一个样品与概率分布进行比较时,通常会将此图与正态检验等分布检验一起使用,以验证统计假设。
QQ图最常见的用途是确定样品数据是否遵循特定的概率分布。这种分布通常是正态分布,你可以将此图与正态检验一起使用。不过,它也可以使用不同的分布,如对数正态分布、威布尔分布或指数分布。
2、Q-Q图的原理
要弄清Q-Q图的原理,我们先来介绍下分位数的概念:
分位数, 指的就是连续分布函数中的一个点,这个点对应概率p。若概率0<p<1,随机变量X或它的概率分布的分位数Za,是指满足条件p(X≤Za)=α的实数。
继续,
百分位数,统计学术语,如果将一组数据从小到大排序,并计算相应的累计百分位,则某一百分位所对应数据的值就称为这一百分位的百分位数。可表示为:一组n个观测值按数值大小排列。如,处于p%位置的值称第p百分位数。
那么Q-Q图的原理就是,通过把一列样本数据的分位数与已知分布的一列数据的分位数相比较,从而来检验数据的分布情况。所以, Q-Q图的两个功能都是比较两列数据的分位数是否分布在y=x的直线上。当两列数据行数相同时, 首先将两列数据分别从高到低排序, 直接画散点图就可以了, 当两列数据行数不一样时, 需要分别计算出每列数据的百分位数, 再将两列数据的百分位数画散点图, 检查散点图是否分布在y=x直线附近。
3、实例
3.1 检验数据是否符合正态分布
# 导入包
import pandas as pd
import numpy as np
from scipy import stats
import matplotlib.pyplot as plt
%matplotlib inline
# 读入数据
fname = r"D:\作业\数据分析与可视化\StudentsPerformance.csv"
df = pd.read_csv(fname, engine='python')
# 选择需要的列
df = df.loc[:, ['math score', 'reading score', 'writing score']]
# 求总分数
df['score_tol'] = df['math score'] + df['reading score'] + df['writing score']
# 按照总成绩排序,按照总分数降序排序
df = df.sort_values('score_tol', ascending=False).reset_index(drop=True)
# 计算按照成绩得到的分位数
df['分位数'] = df['score_tol'].rank(pct=True, ascending=False)
# 调包画QQ图检验是否符合正态分布
stats.probplot(df['score_tol'], dist="norm", plot=plt)
# 显示图形
plt.show()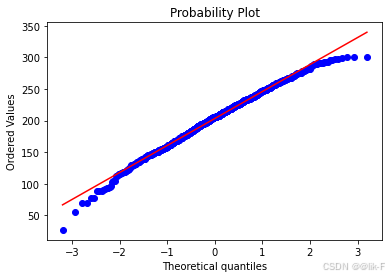
可以看到, 学生的三科总分与标准正态分布的数值画出的散点图, 基本分布在一条直线附近, 可以认为学生分数符合正态分布。
3.2 检验两列数据是否符合同一分布
(1)两列数据行数相同时
# 导入seaborn库
import seaborn as sns
# 数据行数相同的情况下直接按照排序结果画图
ls1 = sorted(df['math score'].values) # 对数学成绩进行排序
ls2 = sorted(df['reading score'].values) # 对阅读成绩进行排序
# 使用seaborn的regplot函数绘制散点图和回归线
sns.regplot(x=pd.Series(ls2), y=pd.Series(ls1), ci=None, color='b', line_kws={'color': 'r'})
# 使用seaborn的regplot函数绘制散点图,其中x轴是阅读成绩(ls2),y轴是数学成绩(ls1)。
# ci=None表示不显示置信区间。
# color='b'设置散点的颜色为蓝色。
# line_kws={'color': 'r'}设置回归线的颜色为红色。
# 显示图形
plt.show()
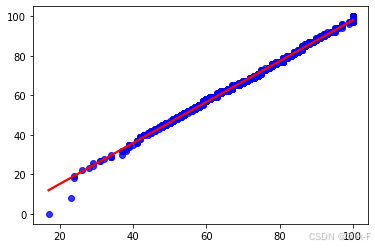
(2)两列数据行数不同时
# 当数据数据行数不同时,需要根据百分位数对应的值画QQ图
# 随机选择行数据
df1 = df.sample(n=800)
# 获取只有800行数据的数学分数的分位数
ls1 = sorted([np.percentile(df1['math score'], i) for i in np.linspace(1, 100, 500)], reverse=True)
# 计算df1中数学成绩的百分位数,np.linspace(1, 100, 500)生成从1到100的500个等间距的百分位数值,
# np.percentile计算给定百分位的值,sorted函数对结果进行降序排序,存储在ls1中。
# 获取有1000行数据的阅读分数的分位数
ls2 = sorted([np.percentile(df['reading score'], i) for i in np.linspace(1, 100, 500)], reverse=True)
# 对应百分位数画QQ图
sns.regplot(x=pd.Series(ls2), y=pd.Series(ls1), ci=None, color='b', line_kws={'color': 'r'})
# 使用seaborn的regplot函数绘制QQ图,其中x轴是阅读成绩的百分位数(ls2),y轴是数学成绩的百分位数(ls1)。
# ci=None表示不显示置信区间,color='b'设置散点的颜色为蓝色,line_kws={'color': 'r'}设置回归线的颜色为红色。
# 显示图形
plt.show()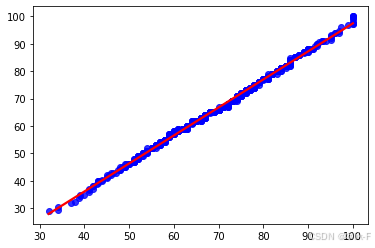
可以看到, 'math score' 和 'reading score' 两列的分位数分布在y=x 直线附近, 我们可以认为两列数据符合同一分布。

















 405
405

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









