






目录
1.将解压好的zookeeper重名为zookeeper-3.5.7(保留版本号)
1.先进入root模式下,编辑 /etc/profile ;在profile文件里添加以下:
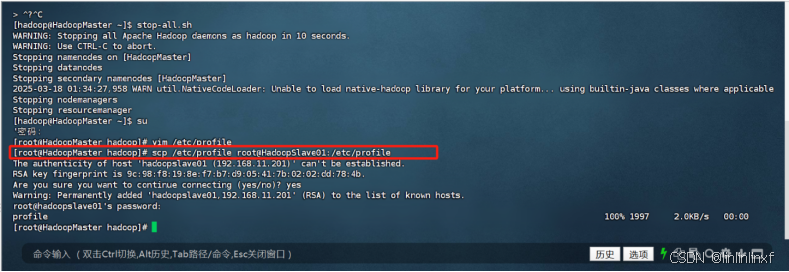
2.通过scp命令远程分发另外两个节点(一定要在root模式下,不然没权限)
3.在zookeeper的安装目录下(~/bigdatasoftware/zookeeper-3.5.7/)创建zkData文件(在文件中写入“1”)
1.进入zook的安装目录下的conf目录,将目录下的zoo_sample.cfg重命名为zoo.cfg
2.编辑zoo.cfg文件,修改数据存储路径为刚刚创建的zkData;
(1).软连接Hadoop的core-site.xml文件到hbase的conf目录下
(2)软连接Hadoop的hdfs-site.xml文件到hbase的conf目录下
(1)因为hbase是依赖zookeeper和Hadoop的,因此启动hbase前,需要先启动zookeeper和Hadoop集群。
第一种:[hadoop@HadoopMaster hbase-2.4.6]$ bin/hbase-daemon.sh start master
第二种:[hadoop@HadoopMaster hbase-2.4.6]$ bin/start-hbase.sh
前言
在大数据时代,海量数据的存储、管理和分析成为企业面临的重大挑战。分布式数据库 HBase 凭借其高可靠性、高性能和可扩展性,成为处理海量结构化数据的理想选择。而 Zookeeper 作为分布式协调服务,为 HBase 提供了可靠的元数据管理、集群状态监控和分布式锁等服务,是 HBase 稳定运行的基石。
一、资源准备
- 资源版本:zookeeper-3.7.5、hbase-2.4.6
- 虚拟机:HadoopMaster、HadoopSlave01、HadoopSlave02
- 资源获取链接
链接:https://pan.baidu.com/s/1dkTwGrKwqDsCxSQCMrxnXw?pwd=trv7
提取码: trv7
二、zookeeper安装部署
1.集群部署
在HadoopMaster和HadoopSlave01、HadoopSlave02三个节点上部署zookeeper
2.上传解压zookeeper安装包
代码如下(示例):
tar -zxvf apache-zookeeper-3.5.7-bin.tar.gz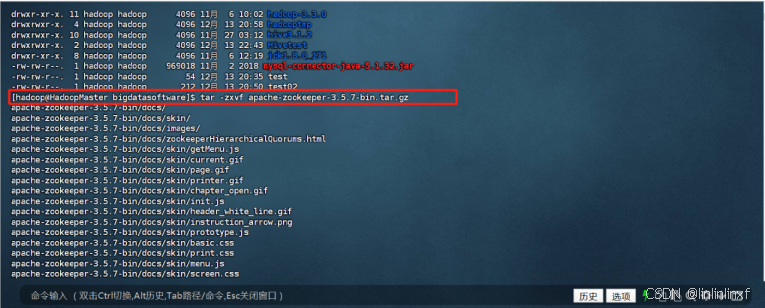
3.配置相关文件
1.将解压好的zookeeper重名为zookeeper-3.5.7(保留版本号)
mv apache-zookeeper-3.5.7-bin zookeeper-3.5.7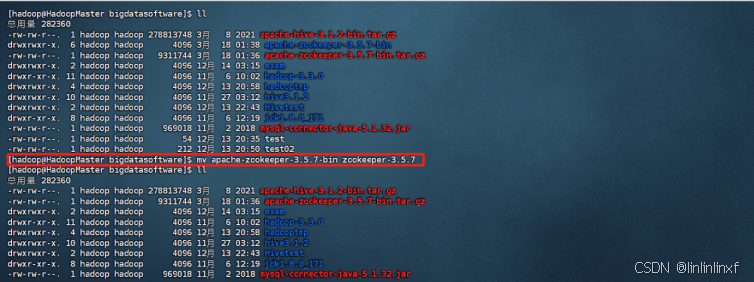
2.配置环境变量
1.先进入root模式下,编辑 /etc/profile ;在profile文件里添加以下:
#zookeeper
export ZK_HOME=/home/hadoop/bigdatasoftware/zookeeper-3.5.7
export PATH=$PATH:$ZK_HOME/bin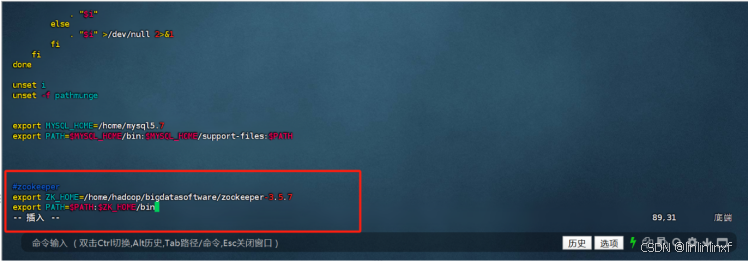
配置完成记得source以下文件,使其环境变量生效
source /etc/profile2.通过scp命令远程分发另外两个节点(一定要在root模式下,不然没权限)
3.在zookeeper的安装目录下(~/bigdatasoftware/zookeeper-3.5.7/)创建zkData文件(在文件中写入“1”)
vim myid
4.配置zoo.cfg
1.进入zook的安装目录下的conf目录,将目录下的zoo_sample.cfg重命名为zoo.cfg
2.编辑zoo.cfg文件,修改数据存储路径为刚刚创建的zkData;
vim zoo.cfg
3.再在zoo.cfg文件中添加
server.1=HadoopMaster:2888:3888
server.2=HadoopSlave01:2888:3888
server.3=HadoopSlave02:2888:3888
5.远程分发zookeeper包给另外两个节点
scp -r ~/bigdatasoftware/zookeeper-3.5.7 hadoop@HadoopSlave01:~/software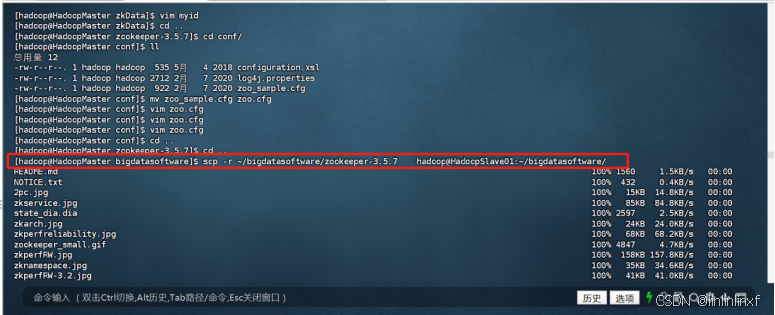
发送完成后,将HadoopSlave01和HadoopSlave02中zookeeper-3.5.7/zkData/myid中内容改为2(对应HadoopSlave01)和3(对应HadoopSlave2)。
6.集群操作
1.分别启动
[hadoop@HadoopMaster zookeeper-3.5.7]$ bin/zkServer.sh start
[hadoop@HadoopSlave01 zookeeper-3.5.7]$ bin/zkServer.sh start
[hadoop@HadoopSlave02 zookeeper-3.5.7]$ bin/zkServer.sh start
2.查看进程

3.查看状态
[hadoop@HadoopMaster zookeeper-3.5.7]bin/zkServer.sh status[hadoop@HadoopMaster zookeeper-3.5.7]$ bin/zkServer.sh status
ZooKeeper JMX enabled by default
Using config: /home/hadoop/bigdatasoftware/zookeeper-3.5.7/bin/../conf/zoo.cfg
Client port found: 2181. Client address: localhost.
Mode: follower
[hadoop@HadoopSlave01 zookeeper-3.5.7]$ bin/zkServer.sh status
ZooKeeper JMX enabled by default
Using config: /home/hadoop/bigdatasoftware/zookeeper-3.5.7/bin/../conf/zoo.cfg
Client port found: 2181. Client address: localhost.
Mode: leader
[hadoop@HadoopSlave02 zookeeper-3.5.7]$ bin/zkServer.sh status
ZooKeeper JMX enabled by default
Using config: /home/hadoop/bigdatasoftware/zookeeper-3.5.7/bin/../conf/zoo.cfg
Client port found: 2181. Client address: localhost.
Mode: follower
成功!!!
三.Hbase的安装部署
1.上传解压hbase安装包
tar -zxvf hbase-2.4.6-bin.tar.gz2.配置环境变量(root模式下)
添加以下内容
export HBASE_HOME=/home/hadoop/bigdatasoftware/hbase-2.4.6
export PATH=$PATH:$HBASE_HOME/bin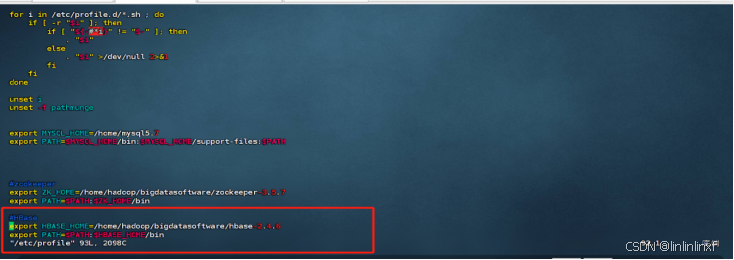
配置完成后,scp远程发送给另外两个节点
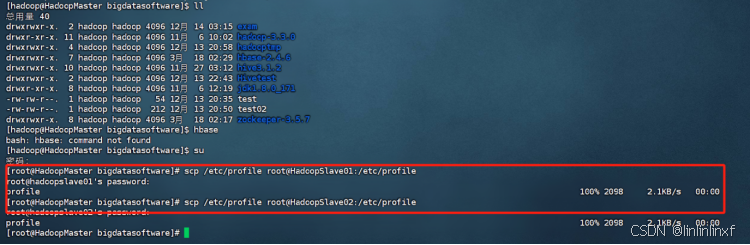
3.配置hbase-env.sh文件
进入hbase-2.4.6/conf目录下,添加以下内容
export JAVA_HOME=/home/hadoop/bigdatasoftware/jdk1.8.0_171
export HBASE_MANAGES_ZK=false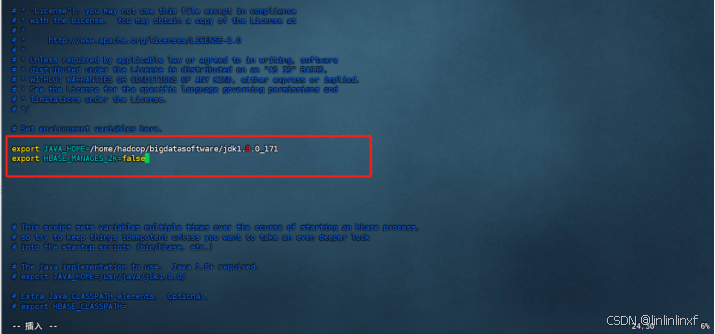
4.配置hbase-site.xml文件
将里面的内容替换(有些地方修改为自己的路径和主机名)为以下:
<configuration>
<!-- 8020或9000要与hadoop的core-site.xml fs.defaultFS的端口一致 -->
<property>
<name>hbase.rootdir</name>
<value>hdfs://HadoopMaster:9000/HBase</value>
</property>
<property>
<name>hbase.cluster.distributed</name>
<value>true</value>
</property>
<property>
<name>hbase.master.port</name>
<value>16000</value>
</property>
<!-- 在分布式的情况下一定要设置,不然容易出现Hmaster起不来的情况 -->
<property>
<name>hbase.unsafe.stream.capability.enforce</name>
<value>false</value>
</property>
<property>
<name>hbase.wal.provider</name>
<value>filesystem</value>
</property>
<property>
<name>hbase.zookeeper.property.dataDir</name>
<value>/home/hadoop/bigdatasoftware/zookeeper-3.5.7/zkData</value>
</property>
<property>
<name>hbase.zookeeper.quorum</name>
<value>HadoopMaster,HadoopSlave01,HadoopSlave02</value>
</property>
</configuration>5.配置regionservers文件
将里面的内容替换为三个主机名:

6.软连接Hadoop的配置文件到Hbase
(1).软连接Hadoop的core-site.xml文件到hbase的conf目录下
ln -s ~/bigdatasoftware/hadoop-3.3.0/etc/hadoop/core-site.xml ~/bigdatasoftware/hbase-2.4.6/conf/core-site.xml(2)软连接Hadoop的hdfs-site.xml文件到hbase的conf目录下
ln -s ~/bigdatasoftware/hadoop-3.3.0/etc/hadoop/hdfs-site.xml ~/bigdatasoftware/hbase-2.4.6/conf/hdfs-site.xml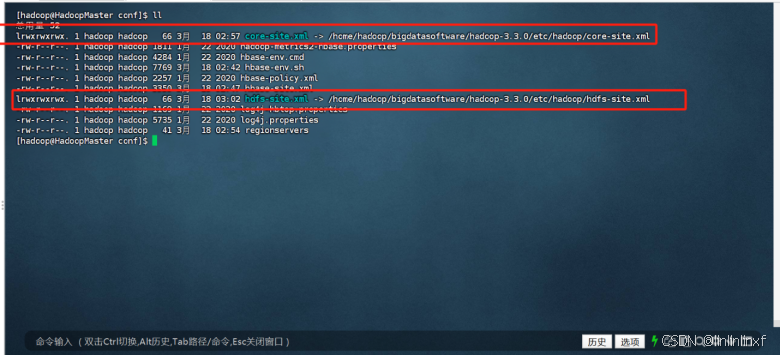
7.配置完成远程分发hbase给另外两个节点
scp -r ~/bigdatasoftware/hbase-2.4.6 hadoop@HadoopSlave01:~/software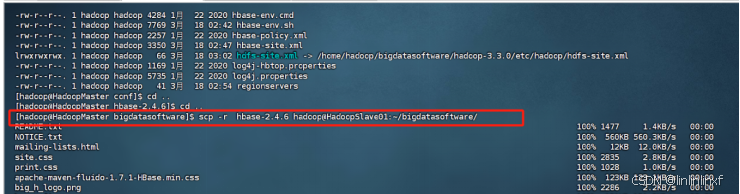
8.启动Hbase
(1)因为hbase是依赖zookeeper和Hadoop的,因此启动hbase前,需要先启动zookeeper和Hadoop集群。
(2)启动方式
第一种:[hadoop@HadoopMaster hbase-2.4.6]$ bin/hbase-daemon.sh start master
第二种:[hadoop@HadoopMaster hbase-2.4.6]$ bin/start-hbase.sh
(3)停止服务
[hadoop@HadoopMaster hbase-2.4.6]$ bin/stop-hbase.sh
9.验证
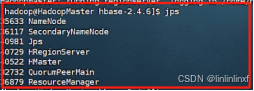
1.jps进程验证
Hbase启动成功后,主节点HadoopMaster有以下节点(zookeeper集群1个+Hadoop集群3个+hbase 2个)
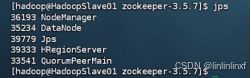
Hbase启动成功后,附节点HadoopSlave01和HadoopSlave01有以下节点
2.网页验证
启动hbase后,可通过http://(ip地址):16010验证
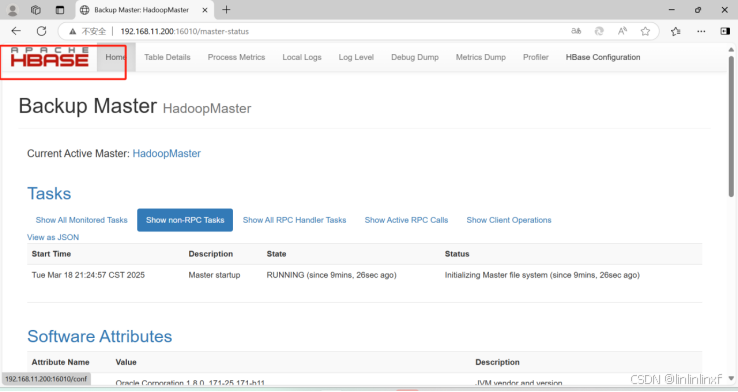
成功!!!

















 2008
2008

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









