







 本文详细介绍了Zookeeper的基础概念、工作原理、特点、数据结构,包括本地模式和分布式模式的安装步骤,客户端操作,以及高级特性如选举机制和ZAB协议。还涉及了生产环境中的案例,如磁盘清理和内存优化。
本文详细介绍了Zookeeper的基础概念、工作原理、特点、数据结构,包括本地模式和分布式模式的安装步骤,客户端操作,以及高级特性如选举机制和ZAB协议。还涉及了生产环境中的案例,如磁盘清理和内存优化。
一. Zookeeper
第一章:Zookeeper入门
1.1 概述
zookeeper是一个开源的分布式的,为分布式应用提供协调的Apache项目
1.2 工作机制
Zookeeper从设计模式角度来理解:是一个基于观察者模式设计的分布式服务管理框架,它是负责存储和管理大家都关心的数据,然后接受观察者的注册,一旦这些数据的状态发生变化 ,Zookeeper就将负责通知已经在Zookeeper上注册的那些观察者做出相应的反应。

1.3 特点
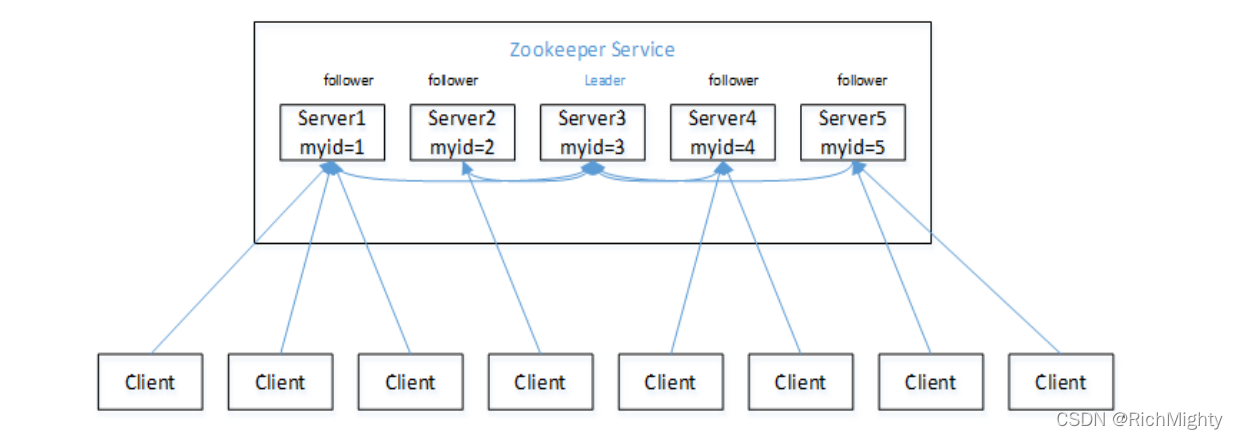
1)Zookeeper:一个领导者(Leader),多个跟随者(Follower)组成的集群
2)集群中只要有半数以上节点存活,Zookeeper集群就能正常服务,所以zk适合安装奇数台服务器
3)全局数据一致:每个Server保存一份相同的数据副本,Client无论连接到哪个Server,数据都是一致的
4)更新请求顺序进行,来自同一个Client的更新请求按其发送顺序依次执行
5)数据更新原子性,一次数据更新要么成功,要么失败
6)实时性,在一定时间范围内,Client能读到最新数据
1.4 数据结构
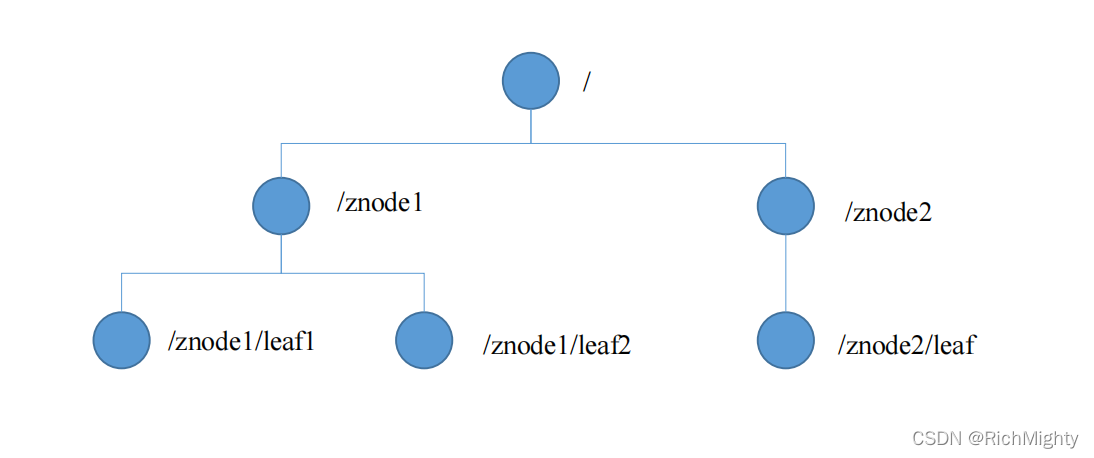
ZooKeeper数据模型的结构与Unix文件系统很类似,整体上可以看作是一棵树,每个节点称做一个ZNode。每一个ZNode默认能够存储1M B的数据,每个ZNode都可以通过其路径唯一标识。
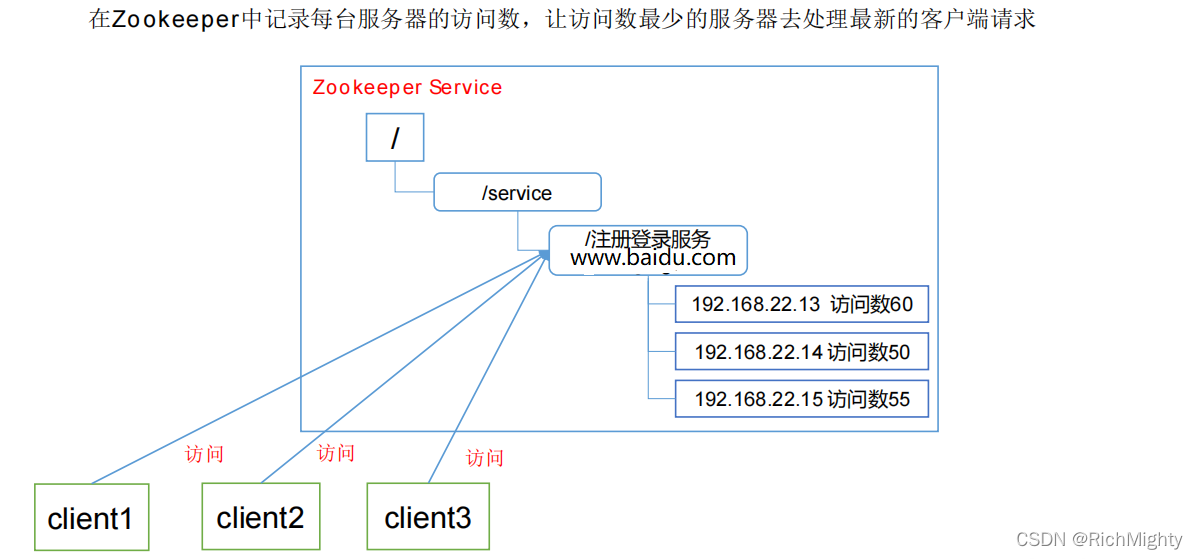
1.5 应用场景
提供的服务包括:统一命名服务、统一配置管理、统一集群管理、服务器节点动态上下线、软负载均衡等
统一命名服务:

统一配置管理:
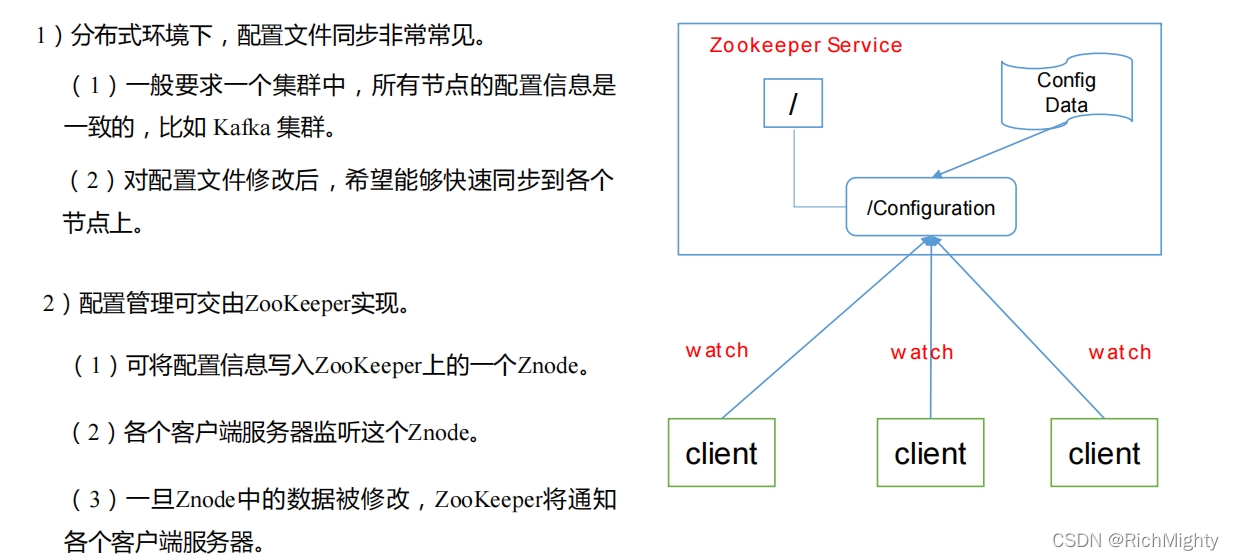
统一集群管理:

服务器动态上下线:

软负载均衡:
1.6 下载地址
官网:https://zookeeper.apache.org/
安装包下载地址:http://archive.apache.org/dist/zookeeper/
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-vhVROVLj-1650939977805)(image-20210701143807103.png)]](https://i-blog.csdnimg.cn/blog_migrate/e6429c5042e82293e18490c12d46ab6c.png)
第二章:Zookeeper安装
2.1 本地模式安装
1.安装前准备
(1)安装 Jdk
[root@zookeeper software]# rpm -ivh jdk-8u181-linux-x64(1).rpm
(2)拷贝 Zookeeper 安装包到 Linux 系统下
(3)解压到指定目录
[root@zookeeper software]# tar -zxvf zookeeper-3.4.10.tar.gz -C /opt/module/
2.配置修改
(1)将/opt/module/zookeeper-3.4.10/conf 这个路径下的 zoo_sample.cfg 修改为 zoo.cfg
[root@zookeeper conf]# mv zoo_sample.cfg zoo.cfg
(2)打开 zoo.cfg 文件,修改 dataDir 路径
[root@zookeeper zookeeper-3.4.10]# vim zoo.cfg
修改如下内容:
dataDir=/opt/module/zookeeper-3.4.10/zkData
(3)在/opt/module/zookeeper-3.4.10/这个目录上创建 zkData 文件夹
[root@zookeeper zookeeper-3.4.10]# mkdir zkData
3.操作 Zookeeper
(1)启动 Zookeeper
[root@zookeeper zookeeper-3.4.10]# bin/zkServer.sh start
(2)查看进程是否启动
[root@zookeeper zookeeper-3.4.10]# jps
4020 Jps
4001 QuorumPeerMain
(3)查看状态:
[root@zookeeper zookeeper-3.4.10]# bin/zkServer.sh status
ZooKeeper JMX enabled by default
Using config: /opt/module/zookeeper-
3.4.10/bin/../conf/zoo.cfg
Mode: standalone
(4)启动客户端:
[root@zookeeper zookeeper-3.4.10]# bin/zkCli.sh
(5)退出客户端:
[zk: localhost:2181(CONNECTED) 0] quit
(6)停止 Zookeeper
[root@zookeeper zookeeper-3.4.10]# bin/zkServer.sh stop
2.2 配置参数解读
Zookeeper中的配置文件zoo.cfg中参数含义解读如下:
(1)tickTime =2000:通信心跳数,Zookeeper 服务器与客户端心跳时间,单位毫秒
Zookeeper使用的基本时间,服务器之间或客户端与服务器之间维持心跳的时间间隔,也就是每个tickTime时间就会发送一个心跳,时间单位为毫秒.
(2)initLimit =10:LF 初始通信时限
集群中的Follower跟随者服务器与Leader领导者服务器之间初始连接时能容忍的最多心跳数(tickTime的量),用它来限定集群中的Zookeeper服务器连接到Leader的时限。
(3)syncLimit =5:LF 同步通信时限
集群中Leader与Follower之间的最大响应时间单位,假如响应超过syncLimit * tickTime,Leader认为Follwer死掉,从服务器列表中删除Follwer。
(4)dataDir:存放快照日志目录
zookeeper数据节点数据是运行在内存中的,当然内存保存这些结点的数据不可能无限大,而且数据节点的内容是动态变化的,因此zookeeper提供将数据节点持久化的机制,每隔一段时间,zookeeper会将内存中的数据节点DataTree序列到磁盘中,因此就形成了我们的快照日志。
(5)dataLogDir: 存放事务日志目录
就是用于存放事务执行的相关信息,如zxid、cxid等
(6)clientPort =2181:客户端连接端口
监听客户端连接的端口
(7)autopurge.snapRetainCount(3.4.0)
这个参数指定了需要保留的文件数目,默认保留3个
(8)autopurge.purgeInterval(3.4.0)
这个参数指定了清理频率,单位是小时,需要填写一个1或者更大的数据,默认0表示不开启自动清理功能
(9)quorumListenOnAllIPs
该参数设置为true,Zookeeper服务器将监听所有可用IP地址的连接。他会影响ZAB协议和快速Leader选举协议。默认是false。
可视化事务日志
第一步:将libs中的slf4j-api-1.6.1.jar文件和zookeeper根目录下的zookeeper-3.4.8.jar文件复制到临时文件夹tmplibs中
第二步:执行命令:
#可视化事务日志
java -classpath .:slf4j-api-1.6.1.jar:zookeeper-3.4.11.jar org.apache.zookeeper.server.LogFormatter /opt/zookeeper/version-2/log.300000001
#可视化快照日志
java -classpath .:slf4j-api-1.6.1.jar:zookeeper-3.4.11.jar org.apache.zookeeper.server.SnapshotFormatter /opt/zookeeper/data/version-2/snapshot.0
2.3 分布式模式安装
1.集群规划
| 主机 | 服务 | 端口 |
|---|---|---|
| 192.158.21.146 | zookeeper_1 | 2181,2888,3888, |
| 192.158.21.147 | zookeeper_2 | 2181,2888,3888, |
| 192.158.21.148 | zookeeper_3 | 2181,2888,3888, |
2.解压安装
(1)解压 Zookeeper 安装包到/opt目录下
[root@zookeeper software]# tar -zxvf zookeeper-3.4.10.tar.gz -C /opt/
[root@zookeeper software]# mv zookeeper-3.4.10.tar.gz zookeeper
(2)同步/opt/zookeeper目录内容到 zookeeper_2、zookeeper_3
scp -rp /opt/zookeeper root@192.158.21.147:/opt/zookeeper
scp -rp /opt/zookeeper root@192.158.21.148:/opt/zookeeper
3.配置服务器编号
(1)在/data这个目录下创建 zkData
[root@zookeeper zookeeper]# mkdir -p /data/zookeeper
(2)在/data/zookeeper 目录下创建一个 myid 的文件
[root@zookeeper zookeeper]# touch myid
(3)编辑 myid 文件
[root@zookeeper zookeeper]# echo "1" > myid
(4)拷贝配置好的 zookeeper 到其他机器上
scp -rp /data/zookeeper root@192.158.21.147:/data/zookeeper
scp -rp /data/zookeeper root@192.158.21.148:/data/zookeeper
并分别在 zookeeper_2、zookeeper_3上修改 myid 文件中内容为 3、4
4.配置 zoo.cfg 文件
(1)重命名/opt/zookeeper/conf 这个目录下的 zoo_sample.cfg 为 zoo.cfg
[root@zookeeper zookeeper]# mv zoo_sample.cfg zoo.cfg
(2)编辑 zoo.cfg 文件
[root@zookeeper zookeeper]# vim zoo.cfg
#根据情况来设置这个
/dataDir=/data/zookeeper
#在文件末尾添加集群配置:
server.1=192.158.21.146:2888:3888
server.2=192.158.21.147:2888:3888
server.3=192.158.21.148:2888:3888
配置参数解读:
server.A=B:C:D
A 是一个数字,表示这个是第几号服务器;
集群模式下配置一个文件 myid,这个文件在 dataDir 目录下,这个文件里面有一个数据
就是 A 的值,Zookeeper 启动时读取此文件,拿到里面的数据与 zoo.cfg 里面的配置信息比
较从而判断到底是哪个 server。
B 是这个服务器的地址;
C 是这个服务器 Follower 与集群中的 Leader 服务器交换信息的端口;
D 是万一集群中的 Leader 服务器挂了,需要一个端口来重新进行选举,选出一个新的
Leader,而这个端口就是用来执行选举时服务器相互通信的端口
(3)同步 zoo.cfg 配置文件
scp -rp /opt/zookeeper/conf/zoo.cfg root@192.158.21.147:/opt/zookeeper/conf
scp -rp /opt/zookeeper/conf/zoo.cfg root@192.158.21.148:/opt/zookeeper/conf
4.集群操作
(1)分别启动 Zookeeper
[root@zookeeper_1 zookeeper]# bin/zkServer.sh start
[root@zookeeper_2 zookeeper]# bin/zkServer.sh start
[root@zookeeper_3 zookeeper]# bin/zkServer.sh start
(2)查看集群状态
[root@zookeeper_1 ~/zookeeper/bin]# ./zkServer.sh status
ZooKeeper JMX enabled by default
Using config: /root/zookeeper/bin/../conf/zoo.cfg
Mode: leader
[root@zookeeper_2 ~/zookeeper/bin]# ./zkServer.sh status
ZooKeeper JMX enabled by default
Using config: /root/zookeeper/bin/../conf/zoo.cfg
Mode: follower
[root@zookeeper_3 ~/zookeeper/bin]# ./zkServer.sh status
ZooKeeper JMX enabled by default
Using config: /root/zookeeper/bin/../conf/zoo.cfg
Mode: follower
2.4 observer模式
1.在observer节点创建myid
[root@zookeeper zookeeper]# touch myid
[root@zookeeper zookeeper]# echo "4" > myid
2.在observer节点zoo.cfg添加一下配置
peerType=observer
3.在所有zk节点zoo.cfg添加一行配置
server.4=10.0.0.9:2888:3888:observer
4.启动observer节点
[root@zookeeper_4 zookeeper]# bin/zkServer.sh start
5.查看节点状态
[root@zookeeper_4 zookeeper]# ./zkServer.sh status
ZooKeeper JMX enabled by default
Using config: /opt/zookeeper/bin/../conf/zoo.cfg
Mode: observer
第三章:Zookeeper客户端操作
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-L4l6I9yp-1650939977806)(image-20210701155447007.png)]](https://i-blog.csdnimg.cn/blog_migrate/387d9c4cb38c4cbfe2dabfb828434f09.png)
3.1 启动客户端
[root@zookeeper zookeeper]# ./zkCli.sh
3.2 显示所有操作命令
[zk: localhost:2181(CONNECTED) 1] help
3.3 查看当前 znode 中所包含的内容
[zk: localhost:2181(CONNECTED) 0] ls /
[zookeeper]
3.4 查看当前节点详细数据
[zk: localhost:2181(CONNECTED) 2] ls2 /
[zookeeper]
cZxid = 0x0
ctime = Thu Jan 01 08:00:00 CST 1970
mZxid = 0x0
mtime = Thu Jan 01 08:00:00 CST 1970
pZxid = 0x0
cversion = -1
dataVersion = 0
aclVersion = 0
ephemeralOwner = 0x0
dataLength = 0
numChildren = 1
###
cZxid :创建节点的id
ctime : 节点的创建时间
mZxid :修改节点的id
mtime :修改节点的时间
pZxid :子节点的id
cversion : 子节点的版本
dataVersion : 当前节点数据的版本
aclVersion :权限的版本
ephemeralOwner :判断是否是临时节点
dataLength : 数据的长度
numChildren :子节点的数量
3.5 分别创建 2 个普通节点
[zk: localhost:2181(CONNECTED) 8] create /service "fuwu"
Created /service
[zk: localhost:2181(CONNECTED) 12] create /conf "peizhi"
Created /conf
3.6 获得节点的值
[zk: localhost:2181(CONNECTED) 14] get /service
fuwu
cZxid = 0x300000002
ctime = Fri Jul 02 00:04:59 CST 2021
mZxid = 0x300000002
mtime = Fri Jul 02 00:04:59 CST 2021
pZxid = 0x300000002
cversion = 0
dataVersion = 0
aclVersion = 0
ephemeralOwner = 0x0
dataLength = 4
numChildren = 0
[zk: localhost:2181(CONNECTED) 15] get /conf
peizhi
cZxid = 0x300000003
ctime = Fri Jul 02 00:06:14 CST 2021
mZxid = 0x300000003
mtime = Fri Jul 02 00:06:14 CST 2021
pZxid = 0x300000003
cversion = 0
dataVersion = 0
aclVersion = 0
ephemeralOwner = 0x0
dataLength = 6
numChildren = 0
3.7 创建短暂节点
[zk: localhost:2181(CONNECTED) 16] create -e /yuming "www.baidu.com"
Created /yuming
(1)在当前客户端是能查看到的
[zk: localhost:2181(CONNECTED) 18] ls /
[conf, zookeeper, service, yuming]
(2)退出当前客户端然后再重启客户端
[zk: localhost:2181(CONNECTED) 19] quit
(3)再次查看根目录下短暂节点已经删除
[zk: localhost:2181(CONNECTED) 0] ls /
[conf, zookeeper, service]
3.8 创建带序号的节点
(1)先创建一个普通的根节点/haojing/keji
[zk: localhost:2181(CONNECTED) 1] create /haojing "niubi"
Created /haojing
(2)创建带序号的节点
[zk: localhost:2181(CONNECTED) 4] create -s /haojing/keji "niubi"
Created /haojing/keji0000000000
[zk: localhost:2181(CONNECTED) 5] create -s /haojing/zhineng "niubi"
Created /haojing/zhineng0000000001
(3)查看带序号的节点
[zk: localhost:2181(CONNECTED) 6] ls /haojing
[keji0000000000, zhineng0000000001]
如果原来没有序号节点,序号从 0 开始依次递增。如果原节点下已有 2 个节点,则再排序时从 2 开始,以此类推
3.9 修改节点数据值
[zk: localhost:2181(CONNECTED) 10] set /conf "nginx"
3.10 节点的值变化监听
(1)在 zookeeper_1 主机上注册监听/conf节点数据变化
[zk: localhost:2181(CONNECTED) 2] get /conf watch
(2)在 zookeeper_2主机上修改/conf 节点的数据
[zk: localhost:2181(CONNECTED) 1] set /conf "tomcat"
(3)观察zookeeper_1主机收到数据变化的监听
WatchedEvent state:SyncConnected type:NodeDataChanged path:/conf
3.11 节点的子节点变化监听(路径变化)
(1)在 zookeeper_2 主机上注册监听/haojing 节点的子节点变化
[zk: localhost:2181(CONNECTED) 2] ls /haojing watch
[keji0000000000, zhineng0000000001]
(2)在zookeeper_2 主机/haojing 节点上创建子节点
[zk: localhost:2181(CONNECTED) 4] create /haojing/xinzhineng "niubi"
Created /haojing/xinzhineng
(3)观察zookeeper_2主机收到子节点变化的监听
WatchedEvent state:SyncConnected type:NodeChildrenChanged path:/haojing
3.12 删除节点
[zk: localhost:2181(CONNECTED) 7] delete /service
3.13 递归删除节点
[zk: localhost:2181(CONNECTED) 12] rmr /conf/java
3.14 查看节点状态
[zk: localhost:2181(CONNECTED) 14] stat /conf
cZxid = 0x300000003
ctime = Fri Jul 02 00:06:14 CST 2021
mZxid = 0x300000010
mtime = Fri Jul 02 00:25:36 CST 2021
pZxid = 0x300000014
cversion = 2
dataVersion = 2
aclVersion = 0
ephemeralOwner = 0x0
dataLength = 6
numChildren = 0
第四章:Zookeeper高级
4.1 节点类型
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-njoynq0Y-1650939977807)(image-20210701164338503.png)]](https://i-blog.csdnimg.cn/blog_migrate/93dac021c1c368ed59d5165a06c691cf.png)
4.2 监听器原理
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-1VhFTH7C-1650939977808)(image-20210701164930132.png)]](https://i-blog.csdnimg.cn/blog_migrate/085021abbaa2da14c284e61130af1f7f.png)
4.3 选举机制
1.选举流程概述
目前有5台服务器,每台服务器均没有数据,它们的编号分别是1,2,3,4,5按编号依次启动,它们的选择举过程如下:
- 服务器1启动,给自己投票,然后发投票信息,由于其它机器还没有启动所以它收不到反馈信息,服务器1的状态一直属于Looking(选举状态)。
- 服务器2启动,给自己投票,同时与之前启动的服务器1交换结果,由于服务器2的编号大所以服务器2胜出,但此时投票数没有大于半数,所以两个服务器的状态依然是LOOKING。
- 服务器3启动,给自己投票,同时与之前启动的服务器1,2交换信息,由于服务器3的编号最大所以服务器3胜出,此时投票数正好大于半数,所以服务器3成为领导者,服务器1,2成为小弟。
- 服务器4启动,给自己投票,同时与之前启动的服务器1,2,3交换信息,尽管服务器4的编号大,但之前服务器3已经胜出,所以服务器4只能成为小弟。
- 服务器5启动,后面的逻辑同服务器4成为小弟
2.选举机制中的概念
(1)Serverid:服务器ID
用来唯一标识一台zookeeper集群中的机器,每台集群不能重复,和myid一致
(2)Zxid:事务ID
用来标识一次服务器状态的变更,在某一时刻,集群中的每台机器的ZXID值不一定完全一样,这和zookeeper服务器对于客户端“更新请求”的处理逻辑有关
(3)Epoch:逻辑时钟
每个Leader任期的代号,没有Leader是同一轮投票过程中的逻辑时钟是相同的,每投完一次票这个值就会增加1
(4)Server状态:选举状态
- LOOKING,竞选状态
- FOLLOWING,随从状态,同步leader状态,参与投票
- OBSERVING,观察状态,同步leader状态,不参与投票
- LEADING,领导者状态
3.在投票完成后,需要将投票信息发送给集群中的所有服务器,它包含如下内容:
-
服务器ID
-
数据ID
-
逻辑时钟
-
选举状态
成为 Leader 的条件:
1)选 epoch 最大的
2)若 epoch 相等,选 zxid 最大的
3)若 epoch 和 zxid 相等,选择 server_id 最大的(zoo.cfg中的myid)
4.4 客户端向服务端写数据流程
4.4.1.写流程之写入请求直接发送给Leader节点
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-22w9msNx-1650939977810)(image-20211108111711060.png)]](https://i-blog.csdnimg.cn/blog_migrate/60d94856f649a9ea49a9d2e19add617d.png)
4.4.2.写流程之写入请求直接发送给Follower节点
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-KanuAnQm-1650939977810)(image-20211108111809212.png)]](https://i-blog.csdnimg.cn/blog_migrate/70ac4bfa7071092650ee1058654aefde.png)
4.5 ZAB协议
4.5.1 什么是ZAB协议
Zab 借鉴了 Paxos 算法,是特别为 Zookeeper 设计的支持崩溃恢复的原子广播协议。基于该协议Zookeeper 设计为只有一台客户端(Leader)负责处理外部的写事务请求,然后Leader 客户端将数据同步到其他 Follower 节点。即 Zookeeper 只有一个 Leader 可以发起提案。
4.5.2 ZAB协议内容
Zab 协议包括两种基本的模式:消息广播、崩溃恢复。
1)消息广播
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-D7WBKjO1-1650939977812)(image-20211108113724918.png)]](https://i-blog.csdnimg.cn/blog_migrate/d400c50e33a74fda919016bf462cade2.png)
2)崩溃恢复-异常假设
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-so3sCmwa-1650939977812)(image-20211108113922086.png)]](https://i-blog.csdnimg.cn/blog_migrate/df1b4e13717582a5cb911d2ecdd35398.png)
3)崩溃恢复-Leader选举
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-EboMfUgz-1650939977813)(image-20211108114122948.png)]](https://i-blog.csdnimg.cn/blog_migrate/d930d07706a0a9dbb050ae48ad61aa3f.png)
4)崩溃恢复-数据恢复
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-c3x3kOlZ-1650939977816)(image-20211108140725643.png)]](https://i-blog.csdnimg.cn/blog_migrate/b409416ab0e7be8bab8c64035a97332c.png)
第五章:生产案例
5.1 磁盘清理
对3个master节点串行重启,每个间隔3分钟,每个节点做如下操作(注意使用hadoop用户)
1.修改 zookeeper-current/conf/zoo.cfg
autopurge.purgeInterval=24
autopurge.snapRetainCount=20
2.重启 zk
su - hadoop
/home/hadoop/zookeeper-current/bin/zkServer.sh stop
/home/hadoop/zookeeper-current/bin/zkServer.sh start
5.2 zk内存分配
1.找到zookeeper/bin/zkEnv.sh
在这个文件里面明确说明独立JVM内存设置文件,路径是zookeeper/conf/java.env
2.编辑java.env
#!/bin/sh
export JAVA_HOME=/usr/java/jdk # 这是你JDK安装路劲
#export JAVA_HOME=/home/jdk1.8.0_131
#heap size MUST be modified according to cluster environment
export JVMFLAGS="-Xms512m -Xmx1024m $JVMFLAGS" #这里是需要设置的内存大小,-Xms512m 最小内存 -Xmx1024m 最大使用内存
3.重启zk集群
/home/hadoop/zookeepe/bin/zkServer.sh stop
/home/hadoop/zookeeper/bin/zkServer.sh start


















 1423
1423

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











