






 本文全面介绍了Kotlin开发语言,涵盖基础语法,如val和var、类型推导等;面向对象特性,包括类与对象、继承构造等;还有Lambda编程、高阶函数、泛型、扩展函数、协程等内容,详细阐述各部分的概念、用法及特点。
本文全面介绍了Kotlin开发语言,涵盖基础语法,如val和var、类型推导等;面向对象特性,包括类与对象、继承构造等;还有Lambda编程、高阶函数、泛型、扩展函数、协程等内容,详细阐述各部分的概念、用法及特点。
基础语法:
val和var:
- val(value的简写)用来声明一个不可变的变量,这种变量在初始赋值之后就再也不能重新赋值,对应 Java 中的final变量。
- var(variable的简写)用来声明一个可变的变量,这种变量在初始赋值之后仍然可以再被重新赋值,对应Java中的非final变量。
注意:
- 在kotlin中定义一个变量,只允许在变量前面声明val关键字或者var关键字。
- val的含义:引用不可变 (变量一旦初始化就不能更改指向,但是可以更改变量指向的内容里的值) 因此,val声明的变量是只读变量,它的引用不可更改,但并不代表其引用对象也不可变。事实上,我们依然可以修改引用对象的可变成员。这跟Java中的final对象概念上是一样的。
-
尽可能的采用val,不可变对象及纯函数(没有副作用的函数,具有引用透明性)来设计程序。(可以先用val声明变量,如果val无法满足需求的时候再使用var声明变量)
fun main() {
val book=Book("java")
book.name="python"
book.printName()
}
class Book(var name:String){
fun printName(){
println(this.name)
}
}类型推导机制:
类型推导机制是kotlin在Java的基础上增强的语言特性之一。通俗的说,编译器可以在不显式声明类型的情况下,自动推导出它所需要的类型。而在这些情况下,需要显式声明类型:
- 它作为一个函数的参数。
- 它是一个非表达式定义的函数,除了返回Unit的情况外。
- 它是一个递归的函数。
- 它是一个公有方法的返回值。
函数:
函数是用来运行代码的载体,kotlin定义函数的语法规则为:首先使用fun关键字来声明一个函数,fun关键字后面紧跟着函数名,函数名尽可能的要表达这个函数的作用。再后面就是一对括号,它包含函数的参数。括号后面的是可选的,用于声明函数的返回类型,最后加上大括号就是函数体了。(fun 函数名 (参数):返回类型{函数体})
当一个函数中只有一行代码的时候,kotlin允许我们不必编写函数体,可以直接将唯一的一行代码写在函数定义的尾部,中间使用等号连接即可。fun 函数名 (参数):返回类型=一行代码。使用这种方式,return省略了,等号足以表达返回值的意思。
条件语句:
kotlin的条件语句有两种实现方式:if和when。
if语句与Java的if语句没有什么区别,但是kotlin的if有一个额外的功能,它是可以有返回值的,返回值就是if每一个条件的最后一行代码的返回值。
when语句与Java的switch语句有点类似,但是比switch语句强大的多。when语句的格式为:when(参数){匹配值->{执行逻辑}……},当执行逻辑只有一行的时候,{}可以省略,同样的when语句也有返回值。when语句除了能用在常量的匹配上,还可以用在类型的匹配和逻辑表达式的匹配。类型匹配的核心就是is关键字,它相当于Java中的instanceof关键字( instanceof 关键字用于测试对象是否是指定类型(类或子类或接口)的实例)。
循环语句:
kotlin的循环语句有两种实现方式:while和for。
while与Java的while没有什么区别。
for却做了很大程度的修改,kotlin增强了Java的for each循环变成了for in循环,再普及一下区间,until,step,downto。区间是kotlin新的东西,用关键字..来表示,例如:val a = 0..10 那就表示创建了一个0到10的区间,并且两端都是闭区间,我们可以用for in来遍历区间:for(i in 0..10)这样的形式。until关键字是用来创建一个左闭右开的区间,例如:val a = 0 until 10 。step关键字表示每一步的要跳过的距离,例如:for(i in 0 until 10 step 2)那就表示每次循环时在区间范围内递增2。上面两个关键字所创建的区间都是升序的区间,也就是左端必须小于等于右端,如果想创建一个降序的区间,可以使用downTo关键字,例如:val a = 10 downTo 1 那就是创建了一个降序的两端闭区间,也可以搭配step关键字。
Kotlin中的Unit,Any和Nothing:
Unit:
Unit在Kotlin中的定义:首先 Unit 本身是一个用 object 表示的单例,所以可以理解为Kotlin有一个类,这个类只有一个单例对象,叫 Unit 。由于在Kotlin中,一切方法/函数都是表达式,表达式是总是有值的,所以每一个方法都必有一个返回值。如果没有用 return 明确的指定,那么一般来说就会用自动帮我们加上Unit。
Any:
Any?是Any的父类,那么严格来说,Any?是所有的类的父类,而Any只是所有不可为空的类(也就是没有?)的父类。
Nothing:
Nothing 是一个类,这个类构造器是私有的,也就是说我们从外面是无法构造一个 Nothing 对象的。前面说每一个方法都有返回值,且返回值至少也是一个 Unit,这是对正常方法来说的。如果一个方法的返回类型定义为 Nothing ,那么这个方法就是无法正常返回的。可以这么理解,Koltin中一切方法都是表达式,也就是都有返回值,那么正常方法返回 Unit ,无法正常返回的方法就返回 Nothing 。
面向对象:
类与对象:
kotlin中也是使用class关键字来声明一个类的,这一点与Java一致,我们还可以在这个类中加入字段和函数来丰富它的功能。而在对类实例化时,如下:val p =Person() kotlin 实例化一个类的方式与Java是类似的,但是它去掉了new关键字,之所以这么设计,是因为当你调用了某个类的构造函数时,你的意图就只能是对这个类进行实例化。
注意:
- Java的属性都有默认值,比如int的默认值为0,引用类型的默认值为null。所以在声明属性时不需要我们指定默认值,而在kotlin中,除非显式的声明延迟初始化,否则我们都要手动指定属性的默认值。
- kotlin类中的成员默认是全局可见的,而Java的默认可见域是包可见性。
继承和构造函数:
在kotlin中任何一个非抽象类是不可以被继承的,相当于Java中给类声明了final关键字,之所以这么设计是因为类和变量一样,最好都是不可变的。而抽象类由于它本身是无法创建实例的,一定要由子类继承它才能创建实例,因此抽象类必须可以被继承才行,不然就没有意义了。
open与:关键字:
要想让类可以被继承,那么需要在父类前面加上open关键字(open class 类名),主动告诉编译器该类可继承;而子类的后面加上:关键字(class 子类 :父类())。
init语句块:
任何一个面向对象的编程语言都会有构造函数的概念,kotlin中也有,但是kotlin中分为了两种:主构造函数和次构造函数。主构造函数是最常用的构造函数,每个类默认都会有一个不带参数的主构造函数,当然你也可以显式的给它指明参数。主构造函数的特点是没有函数体,直接定义在类名的后面,我们在实例化时,必须传入构造函数中要求的所有参数。如果我们想在主构造函数中编写一些逻辑,kotlin给我们提供了init语句块,所有的主构造函数逻辑都可以写在里面。
调用父类的构造函数:
继承规则规定子类的构造函数必须调用父类中的构造函数,也就是先有父,再有子。在Java中使用super调用父类的东西或者构造函数,而在kotlin中子类的主构造函数调用父类中的哪个构造函数,那么在继承时通过父类后面的那个括号来指定。同样子类的主构造函数也要加上该构造函数所需的参数,但是不能将其声明为val或者var,因为在主构造函数中声明成val或者var将自动成为该类的字段。例子:class 类名(val 字段1:int,字段2:int):父类(字段2)
函数的参数默认值:
kotlin提供了给函数设定参数默认值的功能,我们可以在定义函数时给任意参数设定一个默认值,这样当调用此函数时就不会强制要求调用方法为此参数传递值,而在没有传递值的情况下会自动使用参数的默认值。设定默认值的格式为:fun 函数名(num:Int=100)。在调用函数时,kotlin提供了另外一种神奇的机制,就是可以通过键值对的方式来传递参数,这个时候哪个参数在前面在后面都无所谓。形式为:函数(num=100)指定给该参数传递值。
constructor关键字:
次构造函数其实是几乎用不到的,因为参数默认值的功能基本上可以替代次构造函数的功能。简述一下,任何一个类只能有一个主构造函数,但是可以有多个次构造函数,次构造函数也可以用于实例化一个类,它还拥有函数体。次构造函数是通过constructor关键字来定义的。kotlin规定,当一个类既有主构造函数和次构造函数时,所有的次构造函数都必须直接或者间接的调用主构造函数。例如:
class Student(val sno:String,val grade:Int,name:String,age:Int):Person(name,age){
constructor(name:String,age:Int):this("",0,name,age){}
constructor():this("",0){}
}而另外一种特殊情况,类中没有显式的定义主构造函数但是却定义了次构造函数时,它就是没有主构造函数的。那么这种情况下,因为没有主构造函数,父类也不用加上括号,而次构造函数只能直接调用父类的构造函数,也就是把this换成super。
class Student:Person{
constructor(name:String,age:Int):super(name,age){}
}可见性修饰符:
kotlin的可见性修饰符与Java的类似,但是也有不一样的地方。
- Java中有四种可见性修饰符,分别是:public,private,protected,default;而kotlin中也有四种,分别是:public,private,protected,internal(kotlin独特的修饰符表示:模块内访问)。
- kotlin的默认修饰符为public,而Java为default。
- kotlin可以在一个文件内单独声明方法和常量,同样支持可见性修饰符。
- kotlin和Java的protected的访问范围不同,Java是包,类以及子类可见;而kotlin是只允许类和子类。
接口:
接口是用于实现多态编程的重要组成部分,kotlin与Java一样,任何一个类最多只能继承一个父类,但是却可以实现任意多个接口。我们可以在接口中定义一系列的抽象行为,然后交给具体的类去实现;若同时实现了多个接口,而接口之间又有相同函数名字时,就需要主动指定使用哪个接口的函数或者重写哪个函数。如果是默认实现的接口函数,你可以在实现类中通过super<接口名>这种方式来调用它,当该接口函数有了默认实现时,那么实现类就自由选择实现或者不实现该函数。在实现接口的属性和方法时,都必须带上override关键字。注意:接口中的函数不要求有函数体。
数据类:
在一个规范的系统架构中,数据类通常占据着非常重要的角色,它们用于将服务器端或者数据库中的数据映射到内存中,为编程逻辑提供数据模型的支持。数据类通常需要重写equals(),hashCode(),toString()这几个方法。但是同样的功能却在kotlin中实现的极其简单,只需要一个data关键字即可,当一个类前面声明了data后,kotlin就会根据主构造函数中的参数帮你将equals(),hashCode(),toString()等固定且无实际逻辑意义的方法自动生成,从而大大的减少了开发的工作量。
数据类的约定和使用:
- 数据类必须拥有一个构造方法,该构造方法必须包含至少一个参数,一个没有参数的数据类是没有任何用处的。
- 与普通的类不同的是,数据类的构造方法的参数强制使用var或者val进行声明。
- data class之前不能使用abstract,open,sealed,inner进行修饰。
- 在kotlin1.1版本之前数据类只允许实现接口,之后的版本既可以实现接口也可以继承类。
单例类:
kotlin创建单例类的方式很简单,只需要使用object关键字,规则为:object 类名{}。那么这个类就是一个单例类了,调用单例类的函数时只需要直接:类名.函数名 即可。kotlin会保证全局只会存在一个类实例(使用单例类会将整个类中的所有方法全部变成类似于静态方法的调用方式)。
静态方法:
静态方法也叫做类方法,指的是不需要创建实例就可以直接调用的方法,在Java中定义一个静态方法非常简单,只需要在方法上声明一个static关键字即可。而kotlin却极度弱化了静态方法这个概念,在kotlin中如果只是希望让类中的某一个方法变成静态方法的调用方式,那么使用companion object{方法},那么该方法就会变成静态方法的调用方式,不用创建实例可以直接调用该方法。companion object关键字会在类的内部创建一个伴生类,而括号里面的方法就是定义在这个伴生类里面的实例方法,只是kotlin会保证类只会存在一个伴生类对象。通过这种语法特征来支持类似于静态方法调用的写法。
定义真正的静态方法:
- 注解:在单例类或者companion object中的方法里加上@JvmStatic注解,那么编译器就会把这些方法编译成为真正的静态方法。
- 顶层方法:它是指那些没有定义在任何类中的方法,kotlin会把所有的顶层方法全部编译成为静态方法。如果在kotlin中调用的话,直接写上方法名即可,因为所有的顶层方法都可以在任何的位置被直接调用,不用管包名路径,也不用创建实例。而Java没有顶层方法这个概念,所有的方法都必须写在类中。
空指针检查:
首先了解一下null,当一个值为null时,它可以代表很多含义,比如:该值从来没有被初始化;该值不合法;该值不需要;该值不存在。在Android系统上崩溃率最高的异常类型就是空指针异常(NullPointerException),它会让程序变得脆弱。
可空类型系统:
kotlin却非常简单的处理了这个问题,它利用编译时判空检查的机制几乎杜绝了空指针异常。虽然编译时判空检查的机制有时候会导致代码变得比较难写,但是不用担心,kotlin提供了一系列的辅助工具应对各种判空情况。在kotlin中默认的所有参数和变量都不可以为空,如果我们想让一个变量或者参数为空时,kotlin提供了另外一套可为空的类型系统,只不过在使用可为空的类型时,要在编译时处理掉给不可为空的类型传递null的情况,否则代码无法通过编译。
可为空类型写法为:
- 在类型后面加上一个问号?。比如Int?就代表可为空的整型,也是说明传入null时也不会报错。
- 而对于对象调用方法时,比如:a?.方法(),代表当对象a不为空时调用方法,如果为空就什么也不做。
- 再接着?:操作符意思是这个操作符左右两边都接收一个表达式,如果左边表达式的结果不为空那么就返回左边表达式的结果,否则就返回右边表达式的结果。比如:val c = a?:b
- 非空断言!!:写在变量后面代表我非常确信这个变量不会为空,不用进行空指针检查,如果有出现问题,那么可以直接抛出异常,后面自己承担。
字符串内嵌表达式:
kotlin从一开始就支持了字符串内嵌表达式的功能,弥补了Java在这点的遗憾。在kotlin中,我们不需要再像Java那样拼接字符串了,而是可以直接的将表达式写在字符串里面,即使是非常复杂的字符串,也会变得简单。语法规则为:1.仅有一个变量时($),比如:"hello,$name." 那么在运行时这个变量就会替代这一部分内容。2.表达式(${}),比如:"hello,${obj.name}.",那么在运行时就会使用这个表达式执行的结果替代这一部分内容。
延迟初始化和密封类:
对变量延迟初始化:
如果你的类中有很多的全局变量实例,为了保证它们能够满足kotlin的空指针检查语法标准,你不得不做出许多的非空判断保护才行,即使你非常确定它们不会为空,解决办法是对全局变量进行延迟初始化。同样类中的属性除非显式的声明延迟初始化,否则必须初始化。延迟初始化使用的是lateinit关键字,它可以告诉编译器,我会在晚些时候进行初始化,就可以不用一开始就对它赋值为null了。例如:private lateinit val a:Int 一旦使用了延迟初始化就要保证它在被调用前已经被初始化过了。
密封类:
密封类需要使用sealed关键字修饰,并且被sealed关键字修饰的类,它的子类必须要以嵌套类的形式在父类中全部声明。一个密封的类是一个抽象的类,它有一个受限制的类层次结构。继承自它的类必须与密封类在同一个文件中。使用密封类变量作为条件传入when语句时,kotlin会自动检测该密封类有哪些子类,并且强制要求在when语句中处理每一个密封子类所对应的情况,避免了由于编译器认为缺少条件分支,而不通过的情况。
Lambda编程:
定义:
在数学和计算中,Lambda 表达式通常是一个函数:对于某些或所有输入值的组合,它指定一个输出值。简单地说,它是没有声明的方法,也即没有访问修饰符、返回值声明和名字。Lambda表达式的语法结构为:{参数列表->函数体},首先最外面是一个大括号,如果有参数传入时还需要声明参数列表,参数列表的末尾使用一个->符号,表示参数列表结束和函数体开始,函数体中可以写任意的代码,但是不建议写太长,并且最后一行的代码会自动作为Lambda表达式的返回值。(简单来说,Lambda就是一小段可以作为参数传递的代码)
注意:
- 首先,我们可以不需要定义一个Lambda变量,而是可以直接的将Lambda表达式直接写入函数当中。
- 当Lambda参数是函数的最后一个参数时,可以将Lambda参数移动到函数括号的外面。
- 如果Lambda参数是函数的唯一一个参数的话,还可以将函数的括号进行省略。
- 当Lambda表达式的参数列表中只有一个参数时,那么可以不必声明参数名,而是使用it关键字替代这个参数名。
举例:
//Java创建子线程
new Thread(new Runnable(){
@override
public void run(){
System.out.println("hello");
}
}).start();
//直接翻译为kotlin
Thread(object : Runnable(){
//因为kotlin创建匿名类的方式与Java有区别,它舍弃了new,所以创建匿名类实例的时候改用了object关键字
override fun run(){
println("hello")
}
}).start()
//精简之后
Thread{
println("hello")
}).start()
高阶函数:
高阶函数和Lambda表达式是密不可分的,如果一个函数接收另一个函数作为参数,或者返回值的类型是另一个函数,那么这种函数就叫做高阶函数。定义函数类型的语法为:(参数列表)->返回值。如果没有参数则写空括号,如果没有返回值就写Unit。高阶函数允许让函数类型的参数来决定函数的执行逻辑,即使是同一个高阶函数,如果传入不同的函数类型参数,那么它的执行逻辑和最后返回的结果就可能完全不同的。
举例:
1.函数引用:
//函数引用
fun main(){
val num1=100
val num2=200
//传入参数和不同的函数类型
val result=test(num1,num2,::sum)
}
//这里的func是一个函数类型参数,接收两个Int,返回类型也是Int
fun test(num1:Int,num2:Int,func:(Int,Int)->Int):Int{
//函数类型参数的调用
val result=func(num1,num2)
return result
}
fun sum(num1:Int,num2:Int){
return num1+num2
}2.Lambda表达式:
//lambda表达式
fun main(){
val num1=100
val num2=200
//传入参数和不同的函数类型
val result=test(num1,num2){n1,n2->n1+n2}
}
//这里的func是一个函数类型参数,接收两个Int,返回类型也是Int
fun test(num1:Int,num2:Int,func:(Int,Int)->Int):Int{
//函数类型参数的调用
val result=func(num1,num2)
return result
}
高阶函数的实现原理:
我们都知道,kotlin代码最终都是要翻译为Java·字节码的,但是Java中没有高阶函数这个概念,这依赖于kotlin的编译器。它会把调用方的函数类型参数变成一个Function接口的匿名类实现,并且在invoke函数里放置了实现逻辑,而函数方使用的传入的函数类型参数其实也是在调用invoke函数。这就表明我们每调用一次Lambda表达式,都会创建一个新的匿名类的实现,这将会造成额外的内存和性能开销。
内联函数:
为了解决每次使用lambda表达式所带来的创建匿名类的开销,kotlin提供了内联函数的功能,它可以将使用lambda表达式的开销所消除。使用规则为:在高阶函数前面加上inline关键字的声明。那么kotlin就会在编译时自动把内联函数的代码替换到调用它的地方,从而解决开销。
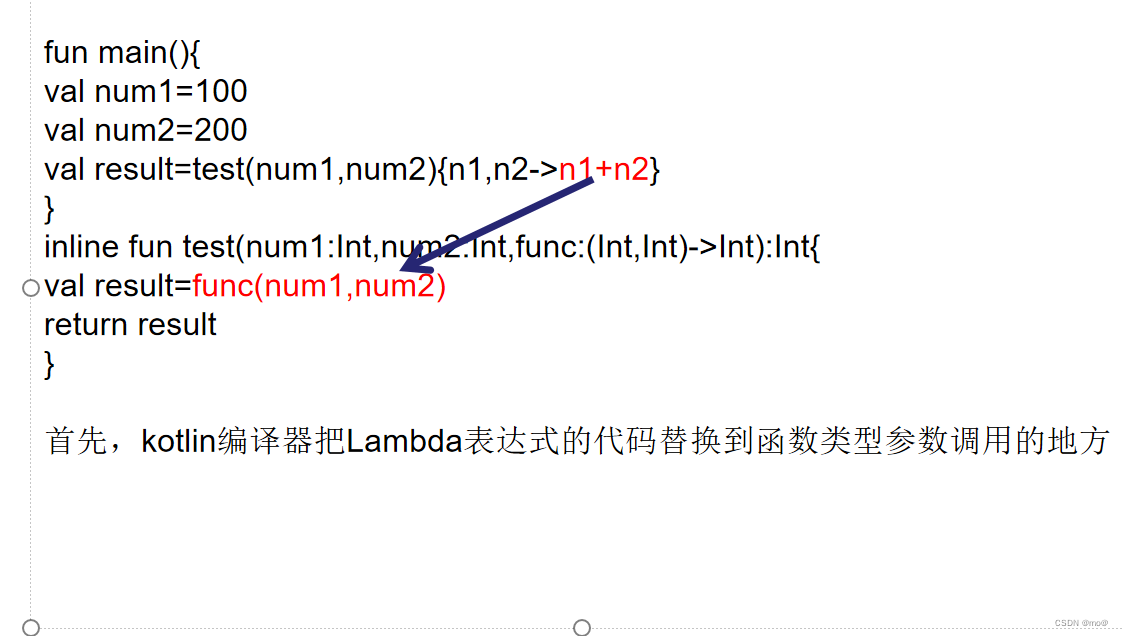


noinline和crossinline:
如果一个高阶函数中接收了两个或者更多的函数类型的参数,这时如果我们加上inline关键字,那么kotlin会自动的将所有的引用了lambda表达式的函数类型参数全部进行内联。如果我们不想让其中的一个引用了lambda表达式的函数类型参数被内联,那么可以在这个函数类型参数前面加上noinline关键字,那么这个参数就不会被自动内联。那为什么会有noinline呢?这是因为内联的函数类型参数在编译的时候会进行代码替换,因此它没有真正的参数属性。非内联的函数类型参数可以自由的传递给其他任何的函数,因此它就是一个真实的参数。而内联的函数类型参数只允许传递给另外一个内联函数,这也是它的最大的局限性。另外,内联函数和非内联函数还有一个区别,那就是内联函数所引用的Lambda表达式是可以使用return关键字进行返回的,而非内联函数就只能局部返回,同时不允许直接使用return。
将高阶函数声明为内联函数是一个好的习惯,事实上,绝大多数的高阶函数都是可以直接声明为内联函数的,但是也有少部分例外的情况。也就是,如果我们在高阶函数中创建了另外的Lambda或者匿名类的实现,并且在它们两者的其中调用了函数类型参数,此时再将高阶函数声明为内联函数,就一定会提示错误。这种情况下,就可以借助crossinline关键字,将这些调用的函数类型参数前面加上crossinline声明,就正常运行了。原理是:内联函数的Lambda表达式中允许使用return,但是高阶函数的匿名类实现中不允许直接使用return,两者造成了冲突。而crossinline关键字就像是一个契约,它用于保证在内联函数的Lambda表达式中一定不会再使用return,这样冲突就不存在了,但是还是可以局部返回。
泛型:
在一般的编程模式下,我们需要给任何一个变量指定一个具体的类型,而泛型允许我们在不指定具体类型的情况下进行编程。在泛型的使用上有以下几点的优势:1.类型检查,能在编译时就可以帮你检查出错误;2.更加语义化,在声明时就知道存储的对象类型;3.自动类型转换,在获取数据时不需要进行强制类型转换;4.扩展性更好。
泛型主要有两种定义方式:定义泛型类和定义泛型方法。
//定义泛型类
class MyClass<T>{
//在MyClass类中的方法都允许使用T类型的参数和返回值
fun method(param:T):T{
return param
}
}
val myClass=MyClass<Int>()
val result=myClass.method(123)
//定义泛型方法
class MyClass{
//在fun后面加上<T>声明表示一个泛型方法
fun <T> method(param:T):T{
return param
}
}
//调用时也要调整一些
val myClass=MyClass()
//调用方法时指定泛型类型
val result=myClass.method<Int>(123)
//因为kotlin有出色的类型推导机制
//它可以根据传入的参数自动推导出泛型类型,因此也可以省略对泛型的指定
val result=myClass.method(123)
设定类型上界:
kotlin还支持我们对泛型的类型进行限制,例如:
class MyClass{
fun <T:Number> method(param:T):T{
return param
}
}
这就说明这个泛型方法只能接收Number子类的类型,而其他类型都不会被允许。另外,在默认情况下,所有的泛型都是可以指定为可空类型的,这是因为在不手动指定上界的时候,泛型的默认上界就是Any?。而如果想要让泛型的类型不可为空,,只需要将上界指定为Any即可。
类委托和委托属性:
委托是一种设计模式,它的基本理念就是:操作对象自己不会去处理某段逻辑,而是会把工作委托给另外一个辅助对象去处理。kotlin也支持委托功能,并且将委托功能分为了两种:类委托和委托属性。首先类委托,它的核心思想就是将一个类的具体实现委托给另一个类去实现。例如:
class MySet<T>(val helperSet:HashSet<T>):Set<T>{
override val size: Int
get()= helperSet.size
override fun contains(element: T)= helperSet.contains(element)
override fun containsAll(elements:Collection<T>)= helperSet.containsAll(elements)
override fun isEmpty() = helperSet.isEmpty()
override fun iterator()= helperSet.iterator()
}这里的MySet类的,实现了Set接口,而HashSet参数相当于一个辅助对象,然后在Set接口的实现中,都调用了辅助对象的方法实现,这其实就是一种委托模式。而委托模式的意义就是,让大部分方法实现调用辅助对象的方法,少部分方法实现由自己重写,或者加入一些新的东西。但是这种方式有一定的弊端:就是委托类要调用大量的被委托类的方法时,那么就要写很多模板式代码。这种情况Java没有什么解决方法,但是kotlin通过类委托解决。类委托关键字为by。它放置在委托类后面,被委托类前面(辅助对象),就可以避免这些模板式代码。例如:
class MySet<T>(val helperSet:HashSet<T>):Set<T> by helperSet{
}
委托属性的核心思想是将一个属性的具体实现委托给另一个类去完成。语法结构为:
class MyClass {
var p by Delegate()
}by左边是属性,右边是该属性要委托的类,当调用当调用p属件的时,就会自动调用Delegate类的getValue()方法,当给p属性赋值的时就会自动调用setDelegate()方法。而Delegate类还得进行具体的实现才行:
class Delegate {
var propValue: Any? = null
operator fun getValue(myClass: MyClass, prop: KProperty<*>): Any? {
return propValue
}
operator fun setValue(myClass: MyClass, prop: KProperty<*>, value: Any?) {
propValue = value
}
}这是一种标准的代码实现模板,在Delegate类中我们必须实现getValue()和setValue()这两个方法,并且这两个方法都要使用operator关键字进行声明。getValue()方法要接收两个参数:第一个参数用于声明该Delegate类的委托功能可以在什么类中使用,这里写成MyClass表示仅可在MyClass类中使用;第二个参数KProperty<*>是Kotlin中的一个属性操作类,可用于获取各种属性相关的值,在当前场景下用不到,但是必须在方法参数上进行声明。另外,<*>这种泛型的写法表示你不知道或者不关心泛型的具体类型,仅仅为了通过编译。setValue()方法,前两个参数一样,最后一个表示要赋值给委托属性的值,这个参数类型必须和getValue()方法的返回值一样。如果属性使用val声明的话,那么可以不用实现setValue()方法。
类型擦除:
泛型功能其实是通过类型擦除来实现的,因为虚拟机中没有泛型,只有普通的类和方法。也就是说泛型对于类型的约束只存在于编译时期,之后编译器会把所有的泛型类型参数替换成为它们的限定类型(对于Java来说,没有限定类型的参数都会被替换为object)。而运行时还是会按照JDK 1.5之前的机制来运行的,在必要时还会插入强制类型转换,而且在取出数据的时候JVM并不知道具体的数据类型。
泛型的局限性:
- 不能用基本类型实例化类型参数,kotlin不存在。
- 如果试图查询一个对象是否属于某一个泛型类型,会报错。
- 不能实例化参数化Java泛型数组。
- 不能抛出或者捕获泛型类的实例。
泛型实化:
因为kotlin提供了内联函数的概念,它会将内联函数中的代码在编译时就自动被替换到调用它的地方,这样的话也就不存在类型擦除的问题了,因为代码在编译之后会直接使用实际的类型来替代内联函数中的泛型,这个时候泛型类就可以获取泛型的实际类型。语法结构为:在声明泛型的地方加上reified关键字表示该泛型要实化,同时满足它是内联函数。例如:inline fun <reified T>sum(){}
泛型的协变:
一个泛型类或者泛型接口中的方法,它的参数列表是接收数据的地方,因此可以称为in位置;而它的返回值是输出数据的地方,因此可以称为out位置。在Java中,如果A是B的子类,那么某个方法接收一个B时,传入A也合法;但是如果某个方法接收一个MyClass<B>时,我们传入MyClass<A>,这样不合法,因为可能存在类型转换的安全隐患,而且MyClass<A>不是MyClass<B>的子类。但在kotlin中通过协变使其合法:1.把MyClass<T>类的泛型设置为只读,那么它是没有类型转换的安全隐患的,而要实现这一点,我们就不能使用set方法给泛型赋值,只能使用构造函数加上val给泛型赋值,或者构造函数+var+private,保证对于外部泛型不可修改。也就是泛型不能出现在in位置,只能出现在out位置。2.进行协变声明,在泛型T声明前加上out关键字,表示泛型不能出现在in位置,只能出现在out位置,也就是泛型T是协变的,也自然解决了MyClass<A>不是MyClass<B>的子类的问题,让MyClass<A>成为MyClass<B>的子类。使得如果某个方法接收一个MyClass<B>时,我们传入MyClass<A>,合法。
泛型的逆变:
从定义来看,协变和逆变完全相反,逆变:假如定义了一个MyClass<T>的泛型类,其中A是B的子类,同时MyClass<B>又是MyClass<A>的子类,那么我们就可以称MyClass在T这个泛型是逆变的。使用方式为:在泛型T声明前加上in关键字,表示泛型不能出现在out位置,只能出现在in位置,也就是泛型T是逆变的。使得MyClass<B>成为MyClass<A>的子类。kotlin在提供协变和逆变的功能时,只要我们遵守协变时在out,逆变时在in,就不会有类型转换异常的风险,如果想要打破这个规则可以使用注解@UnsafeVariance。
扩展函数:
扩展函数表示即使在不修改某个类的情况下,仍然可以打开这个类,并且向该类添加新的函数。kotlin对扩展函数进行了很好的支持,但Java却没有支持。扩展函数的语法规则为:
fun ClassName.methodName(param1:Int,param2:Int):Int{
return 0
}相比于普通的函数定义,只需要在定义扩展函数时在函数名字前面加上一个ClassName.的语法结构,就表示将这个函数添加到指定类中了,这个函数也会有类的上下文。扩展函数可以定义在任何一个现有类中,也可以创建新文件,让它有全局的访问域。
运算符重载:
运算符重载是kotlin提供的一个比较有趣的语法糖,kotlin允许我们将所有的运算符甚至其他的关键字进行重载,从而扩展这些运算符和关键字的用法。虽然kotlin赋予了我们这种能力,但是在使用时要考虑逻辑的合理性。运算符重载使用的是operator关键字,只要在指定的函数前面加上operator关键字,就可以实现运算符重载的功能,而这个指定函数是根据不同的运算符有不同的重载函数。具体为:

协程:
协程可以理解为轻量级的线程,线程需要依靠操作系统的调度才可以实现不同线程之间的切换,协程却可以在编程语言的层面上就可以实现不同协程之间的切换。协程允许我们在单线程的环境下模拟多线程编程的效果,代码执行的挂起和恢复完全是由编程语言来控制的,和操作系统无关。
Job:
每一个协程创建时,都会生成一个 Job 实例,这个实例是协程的唯一标识,负责管理协程的生命周期。当协程创建、执行、完成、取消时,Job 的状态也会随之改变,通过检查 Job 对象的属性可以追踪到协程当前的状态。通常来说,Job 的生命周期会经过四个状态:New → Active → Completing → Completed。
Job 一共包含六个状态:
- 新创建 New
- 活跃 Active
- 完成中 Completing
- 已完成 Completed
- 取消中 Cancelling
- 已取消 Cancelled
我们无法直接访问这些状态,但我们可以访问 Job 的属性:isActive、isCancelled ,isCompleted,通过这些属性可以得知 Job 当前的状态。
基本用法:
kotlin并没有将协程纳入标准库的API中,而是以依赖库的形式提供的。
如何开启一个协程?
- Global.launch{}函数,它可以创建一个协程的作用域,这样在函数代码块中的代码就是在协程中运行的。Global.launch{}函数每次创建的都是一个顶层的协程,这种协程在应用程序运行结束的时候会跟着一起结束。
- runBlocking{}函数,它同样可以创建一个协程的作用域,不同的是,它可以保证在协程作用域内的所有代码和子代码没有全部执行完之前就一直阻塞当前线程,也就是说让应用程序在协程中的代码都运行完了之后再结束。需要注意的是:runBlocking函数通常只应该在测试环境下使用,在正式环境下容易产生一些性能问题。
- launch函数,首先它必须在协程的作用域中才可以被调用,其次它可以在当前协程的作用域下创建子协程。子协程的特点是,如果外层作用域的协程结束了,那么该作用域下所有的子协程也会一起跟着结束。
- sleep()和delay():delay()是一个非阻塞式的挂起函数,它只会挂起当前协程,并不会影响其他的协程的运行;而sleep()会阻塞当前的线程,这样运行在该线程下的所有协程都会被阻塞。注意:delay()只能在协程的作用域或者其他挂起函数中调用。
- suspend关键字:使用它可以将任意函数声明成挂起函数,而挂起函数之间是可以互相调用的,这些函数只能在协程内部或者其他挂起函数中执行,不能在其他普通函数中执行。
- coroutineScope函数,suspend关键字只能将任意函数声明成挂起函数,但是无法提供协程的作用域。比如:在挂起函数中调用launch函数是无法成功的。那么就可以借助coroutineScope函数,它也是一个挂起函数,因此可以被其他的挂起函数调用,调用之后,它就可以继承外部的协程的作用域,从而给任意挂起函数提供协程作用域。让挂起函数中调用launch函数成为现实。它还可以保证其作用域的代码和子协程全部执行完之前,外部的协程会一直被挂起。
- 不管是coroutineScope函数还是launch函数,它们都会返回一个Job对象,我们只需要调用Job对象的cancel方法就可以实现取消协程了。一般来说,如果每次创建的都是顶层协程,取消时就需要逐个调用所有已经创建协程的cancel方法。所以顶层协程一般也不建议使用,因为维护成本太高了。
- 实际项目常用写法:首先创建一个Job对象(val job = Job());再把它传入coroutineScope函数中,返回一个coroutineScope对象(val scope = coroutineScope(job));这样随时就可以调用launch函数来创建一个协程了(scope.launch{逻辑});现在调用coroutineScope的launch函数所创建的协程,都会被关联在Job对象的作用域下面,只需要调用一次cancel方法,就会将同一个作用域的所有协程全部取消(job.cancel())。
- launch函数只能用于执行一段逻辑,却不能获取执行的结果,因为它的返回值永远是一个Job对象。与之相反的是async函数,它也必须在协程作用域中调用,它会创建一个新的子协程但是却可以返回一个Deferred对象,如果我们想要获取这个执行结果的话,只需要调用Deferred对象的await()方法即可。事实上,在调用async函数之后,代码块中的代码就会立刻开始执行,当调用await()方法时,如果代码块的代码还没有执行完的话,那么await()就会将当前协程阻塞,直到可以获取到async函数的执行结果。
锁:
kotlin中没有synchronized关键字,但是提供了@Synchronized注解和synchronized()来实现等同的效果。同时kotlin也有lock的方式进行加锁。


















 1302
1302

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











