







目录
Room:
在日常开发中,数据持久化是不可或缺的功能之一,Android平台为开发者了许多数据持久化的方法,如使用SharePreference、文件流、SQLite Database其中SQLite Database更适合用于业务中的数据持久化,但由于原生的SQLite需发者编写大量的SQL语句和处理逻辑,因此涌现出了许多ORM框架。
1.Android数据库ORM框架:
前面已提到,为了方便开发者在Android平台上更加简单地实现数据持久化功能,涌现了许多ORM框架,其中比较典型的有GreenDAO、ORMLite以及Litepal等。这些框架有的由著名的公司维护,有的由知名的开源作者维护。无论是哪架,都可以很好地替代原生SQLite,Jetpack也为我们提供了Room组件。Room在SQLite上提供了一个抽象层,以便在充分利用SQLite强大功能的同时,能够流畅的访问数据库。
2.使用Room实现登录账号列表功能:
2.1:需求:
实现登录账号的功能,并且要有切换账号和删除账号,所以就可以使用一个数据表来存储一个账号了。
2.2:Room的基本组成:
Room的整体结构主要由Entity、Dao和Database这3部分组成。每个部分都有明确的职责,详细说明如下:
- Entity:用于定义封装实际数据的实体类,每个实体类都会在数据库中有一张对应的表,并且表中的列是根据实体类中的字段自动生成的。
- Dao:Dao是数据访问对象的意思,通常会在这里对数据库的各项操作进行封装,在实际编程的时候,逻辑层就不需要和底层数据库打交道了,直接和Dao层进行交互即可。
- Database。用于定义数据库中的关键信息,包括数据库的版本号、包含哪些实体类以及提供Dao层的访问实例。
对于APP而言,它要使用DataBase获取对应的数据库访问对象Dao,然后使用Dao对Entity进行存储操作。
2.3:基本使用:
首先引入配置:
id 'kotlin-kapt'
implementation'androidx.room:room-runtime:2.1.0'
kapt"androidx.room:room-compiler:2.1.0"接下来完善Room的组成部分,首先完成实体类Entity。
//声明为实体类
@Entity
data class Account(
//声明主键且主键值自动生成
@PrimaryKey(autoGenerate = true) var accountId:Int=1,
var loginAccount: String,
var loginPassword:String
)这样系统默认生成的表名,字段名就和类名,类属性名一致,如果想要修改默认生成的表名和字段属性名,可以使用tableName和ColumnInfo。
//声明为实体类
@Entity(tableName="AccountTest")
data class Account(
//声明主键且主键值自动生成
@PrimaryKey(autoGenerate = true) var accountId:Int=1,
@CoiumnInfo(name="test") var loginAccount: String,
var loginPassword:String
)接下来完成数据库访问对象Dao,并且封装访问数据库的操作:
@Dao
interface AccountDao {
//插入
@Insert
fun insertAccount(account: Account){}
//删除
@Delete
fun deleteAccount(account: Account){}
//更新
@Update
fun updateAccount(account: Account){}
//查询
@Query("select loginAccount from Account where loginAccount=:loginAccount")
fun queryAccount(loginAccount:String):String?
}在接口上使用了一个@Dao注解,这样Room才能将它识别为一个Dao。接口的内部就是根据业务需求对各种数据库操作进行的封装。数据库操作通常有增删改查这4种,因此Room也提供了@Insert、@Delete、@Update 和@Query这4种相应的注解。Insert、Delete、Update这几种数据库操作都是直接使用注解标识即可,不用编写SQL语句。而如果想要从数据库中查询数据,或者使用非实体类参数来增删改数据,那么就必须编写SQL语句了。在@Query注解中编写具体的SQL语句来说明想要查询的内容,另外,如果是使用非实体类参数来增删改数据,那么也要编写SQL语句才行,而且这个时候不能使用@Insert、@Delete 或@Update注解,而是都要使用@Query注解才行。最后来到了编写DataBase的部分:
//数据库版本和包含哪些实体类
@Database(version = 1, entities = [Account::class])
abstract class AccountDataBase :RoomDatabase(){
//获取Dao的方法
abstract fun getAccountDao():AccountDao
//单例模式,获取DataBase实例
companion object{
private var instance:AccountDataBase?=null
fun getDataBase(context: Context):AccountDataBase{
instance?.let {
return it
}
return Room.databaseBuilder(context.applicationContext,
AccountDataBase::class.java,"AccountDataBase")
.build().apply { instance=this }
}
}
}Database的写法是比较固定的,定义数据库的版本,包含哪些实体类,提供Dao层的访问实例和Database的实例。在类的头部使用@Database注解声明数据库版本和实体类,多个实体类用逗号分隔即可。然后Database类必须继承于RoomDatabase类,并且要声明为抽象类,提供相应的抽象方法获取Dao的实例。最后是一个单例模式获取Database的实例,设置一个instance变量来存储实例,如果为null,则使用Room的databaseBuilder方法来构建一个Database实例。1参是上下文,建议使用applicationContext,避免造成内存泄漏;2参是Database的class类型;3参是数据库名称。
需要注意的是:因为数据库的操作属于耗时操作,Room是不允许在主线程中进行数据库操作的,因此可以把数据库的操作放在子线程中或者使用allowMainThreadQueries方法(该方法建议在测试环境下使用)。
Room.databaseBuilder(context.applicationContext,
AccountDataBase::class.java,"AccountDataBase")
.allowMainThreadQueries()
.build().apply { instance=this }
}
3.数据库升级:
数据库不是一成不变的,会随着需求和版本的更改而升级的,升级的最简单粗暴的方式为:fallbackToDestructiveMigration方法。
Room.databaseBuilder(context.applicationContext,
AccountDataBase::class.java,"AccountDataBase")
.fallbackToDestructiveMigration()
.build().apply { instance=this }
}在构建Database实例的时候,加上一个fallbackToDestructiveMigration方法,这样只要数据库进行了升级,Room就会将当前的数据库销毁,然后重新创建,随之而来的就是之前数据库中的所有数据内容都消失了,假如在开发测试阶段,这个方法还是可以使用的,如果在发布之后造成了数据的丢失,那么将会是严重的事故。所以Room数据库的升级的正确写法是:Migration升级策略。
val MIGRATION_1_2=object :Migration(1,2){
override fun migrate(database: SupportSQLiteDatabase) {
database.execSQL(//升级的逻辑)
}
}
首先定义一个migration,这里采用的是匿名类的实现,然后重写migrate方法,也就是说当数据库从版本1升级到版本2时,会自动执行migrate方法里的逻辑。例如:
- 给表增加一个字段,那么先修改实体类增加一个字段,然后把@Database注解的version更改为升级之后的版本,最后完成migration变量的赋值和migrate方法的重写。
- 添加一个表,同样先增加一个实体类和Dao实例,然后把@Database注解的version更改为升级之后的版本,最后完成migration变量的赋值和migrate方法的重写。
migrate方法的database的execSQL方法里面是使用SQL语句来对数据库进行升级的,比如:给表增加一个字段就在execSQL方法中使用对应的SQL语句即可。
Room.databaseBuilder(context.applicationContext,
AccountDataBase::class.java,"AccountDataBase")
.addMigrations(MIGRATION_1_2)
//当从版本2升级到版本3时
//.addMigrations(MIGRATION_1_2,MIGRATION_2_3)
.build().apply { instance=this }
}最后调用addMigrations方法,该方法的参数是一个数组,如果以后数据库从版本2升级到版本3就可以再加入一个升级策略即可。
协程和Flow:
关于协程的具体用法参考Kotlin小知识点总结这一篇文章。
1.Flow:
在协程中,Flow 是一种可以顺序发出多个值的类型,而不是只返回单个值的挂起函数。例如,你可以使用 Flow 从数据库接收实时更新。数据流建立在协程之上,可以提供多个值。Flow 在概念上是可以异步计算的数据流。发出的值必须是同一类型。而数据流需要包含提供方(将数据添加到数据流中),中介(可以修改发送到数据流的值,或修正数据流本身),使用方(结果数据,使用数据流中的值)。
1.1:添加流:
fun simple(): Flow<Int> = flow { // 流构建器
for (i in 1..3) {
delay(100) // 逻辑
emit(i) // 发送值
}
}Flow类型的构建器使用flow函数,可以在其中使用 emit函数手动将新值发送到数据流中。除了flow函数,还有flowOf构建器和.asFlow扩展函数来构建Flow类型。
- 数据流是有顺序的,当协程内的提供方调用挂起函数时,提供方会挂起,直到挂起函数返回。
- 使用
flow构建器,生产者不能从不同的 CoroutineContext 发出值。因此,不要通过创建新的协程或使用 withContext 代码块在不同的 CoroutineContext 中调用 emit。 在这些情况下,您可以使用其他流构建器,例如 callbackFlow。
1.2:修改流:
fun simple(): Flow<Int> = flow { // 流构建器
for (i in 1..3) {
delay(100) // 逻辑
emit(i) // 发送值
}
}.filter{
it%2 == 0
}//添加过滤修改流可以使用各种各样的操作符来完成,比如:
- filter操作符:提供了对结果添加限制条件的功能。
- map操作符:提供了将结果集映射为其他类型的方式,如:将结果加上5,或者放进一个函数里
- flowOn操作符:切换线程操作,也就是用于更改流发射的上下文。
- take操作符:限长过渡操作符,在流触及相应限制的时候会将它的执行取消。协程中的取消操作总是通过抛出异常来执行。
- 其他就不一一列举了。
1.3:收集流:
// 收集这个流
simple().collect { value -> println(value) } 使用collect操作符进行收集流。补充:
- 流的每次单独收集都是按顺序执行的,除非进行特殊操作的操作符使用多个流。该收集过程直接在协程中运行,该协程调用末端操作符。
- 流的收集总是在调用协程的上下文中发生。所以默认的,
flow { ... }构建器中的代码运行在相应流的收集器提供的上下文中。也就是说:由于simple().collect是在主线程调用的,那么simple的流主体也是在主线程调用的。 这是快速运行或异步代码的理想默认形式,它不关心执行的上下文并且不会阻塞调用者。
2.冷流和热流:
2.1:冷流:
Flow 是一种类似于序列的冷流 ,flow构建器中的代码直到流被收集的时候才运行。也就是说:Flow 和序列一样,需要有末端操作符,也就是有收集器 collect{} 或 asList,asSet等操作的时候,才运行。
冷流需要有数据生产者、0或多个中间操作、数据消费者才能一起构建成为一个完整的流。当有消费者 collect 或其它终端操作时,流开始从下往上触发,然后从上往下流动。
2.2:热流:
StateFlow(状态流) 和 SharedFlow(共享流)
2.2.1:StateFlow:
- StateFlow是一个状态容器式可观察数据流,可以向其收集器发出当前状态更新和新状态更新。还可通过其 value 属性读取当前状态值。
- 热流 StateFlow,基于 SharedFlow 实现,所以它也有独立存在和共享的特点。但在 StateFlow 中发射数据,只有最新的值被缓存下来,所以当新老订阅者订阅时,只会收到它最后一次更新的值,如果发射的新值和当前值相等,订阅者也不会收到通知。
- StateFlow 和 LiveData具有相似之处。两者都是可观察的数据容器类,并且在应用架构中使用时,两者都遵循相似模式。
2.2.2:SharedFlow:
SharedFlow ,顾名思义,它被称作为热流,主要在于它能让所有收集器共享它所发出的值,其中共享的方式是广播,且它的实例可以独立于收集器的存在而存在。
分页库Paging3:
1.Android中分页功能常见的设计方法:
在业务开发中由于数据信息过多,为了加速页面数据展示,提升用户体验和更高效地利用网络带宽和系统资源,分页加载成了每个App必有的功能之一。在Paging出现之前实现分页功能基本上有两种方式,一种是为RecycleView添加header和footer并自行处理滑动加载等事件,另一种是借助第三方开源框架处理业务逻辑。当然,后者也是基于第一种方式实现的。无论使用哪种方式,开发者都需要处理一些特定的场景。Google为了统一分页加载的实现方案,以使开发者更多地专注于业务功能的实现,推出了分页加载库Paging, Paging3作为Paging组件的最新版本,比Paging更加便捷,因此,开发者了解并掌握Paging3的使用方法是很有必要的。
2.Paging库架构:
Paging 库的组件在应用的三个层运行:
- 代码库层
ViewModel层- 界面层
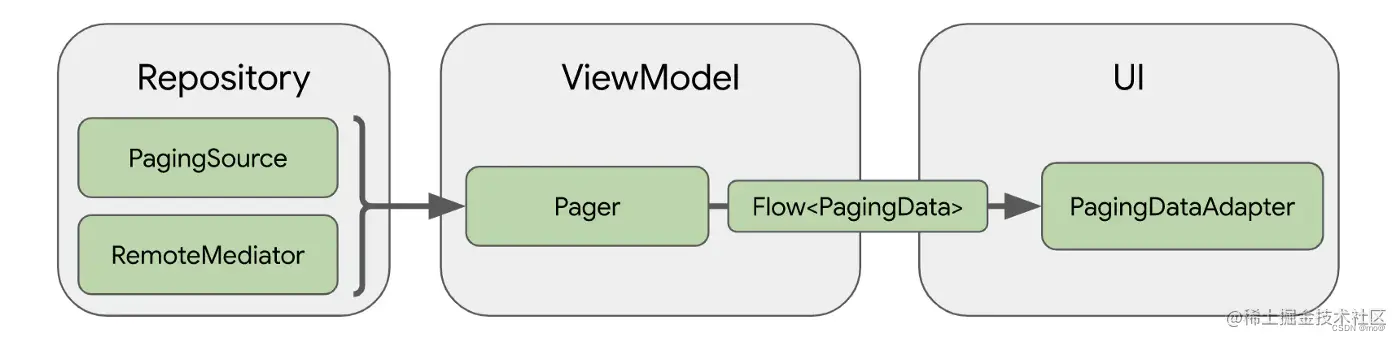
其中,各个部分的含义如下:
- PagingSource :PagingSource 是
Jetpack Paging 3中的核心组件之一,用于定义数据的来源和加载方式。开发者需要实现 PagingSource 抽象类,并在其中指定如何从数据源中加载特定页的数据。PagingSource通常用于与网络 API 或本地数据库进行交互,获取分页数据。 - Pager : Pager是用于创建分页数据流的类。通过 Pager,开发者可以将 PagingSource 与其他配置参数(如分页大小、预取距离等)结合起来,创建用于加载和展示分页数据的 PagingData数据流。Pager 提供了多个静态方法,用于创建不同类型的PagingData 数据流。
- PagingData :PagingData是
Jetpack Paging 3中用于表示分页数据的类。它是一个泛型类,可以容纳各种类型的分页数据。PagingData是一个不可变的数据类,可以在 RecyclerView 中进行展示,并具有与分页相关的特性,如加载状态、分页状态等。 - PagingDataAdapder : PagingDataAdapder是RecyclerView
.Adapder 的子类,专门用于展示 PagingData数据流中的分页数据。 PagingDataAdapder 提供了内置的数据差异计算和局部刷新机制,使得在 RecyclerView 中展示分页数据变得更加高效和简单。它还提供了加载状态和错误处理等功能。 - RemoteMediator :它是用于处理远程数据加载和数据库插入的接口。当 PagingSource加载远程数据时,RemoteMediator 可以在加载完成后将数据插入本地数据库,并提供信息以支持分页和数据持久化。RemoteMediator是实现离线缓存和数据持久化的关键组件之一。
- LoadStateAdapter :它是一个用于展示加载状态的 RecyclerView
.Adapder 的子类。它可以与 PagingDataAdapder 结合使用,用于展示分页数据的加载状态,如加载中、加载错误等。LoadStateAdapter可以显示自定义的加载状态布局,并根据加载状态的变化自动更新 UI。
3.基本使用:
paging的一般流程为:
- 添加 paging3依赖库。
- 创建PagingSource。
- 配置 PagingDataAdapder。
- 将数据展示在RecyclerView 中。
3.1:配置:
//java
implementation 'androidx.paging:paging-runtime:3.2.1'
//kotlin
implementation 'androidx.paging:paging-runtime-ktx:3.2.1'3.2:PagingSource:
首先,创建一个自定义的PagingSource类,该类继承自 PagingSource 抽象类。命名和定义类根据你的数据源类型和加载逻辑需求。
class MyPagingSource : PagingSource<Int, ListItem>() {
// ...
}PagingSource抽象类的两个参数的含义为:
1参 Int:表示页的标识符。在 Paging 3 中,每个页都需要一个唯一的标识符来识别它。通常情况下,这个标识符可以是整数类型,表示页的编号或索引。在加载数据时,我们可以根据这个标识符来确定要加载的是哪一页的数据。
2参 ListItem:表示加载的数据项的类型。在分页加载过程中,每个加载的数据项都属于这个类型。
接着实现load方法和getRefreshKey方法。其中:Load方法负责加载特定页的数据,返回一个 LoadResult对象。
override suspend fun load(params: LoadParams<Int>): LoadResult<Int, ListItem> {
//实现
}其中:
-
LoadParams:了当前请求的加载信息,例如请求的页数、请求的加载大小等
-
LoadResult 是一个包装类,用于封装加载结果。它可以是LoadResult.page(表示加载的数据)、LoadResult.Error(表示错误)。
-
在load方法中需要完成:加载数据,处理数据加载错误和设置上一页,下一页的值。
3.3:Pager:
创建Pager是使用 Jetpack Paging 3 的关键步骤之一。Pager类负责将 PagingSource 与界面进行绑定,并提供可供界面使用的流式数据。要创建 Pager,我们需要在Pager的构造函数中设置PagingSourceFactory,Config和initialKey的值。其中PagingSourceFactory的值为我们自定义PagingSource类的实例;config的值为PagingConfig实例;initialKey的值为指定初始页的键值,可选。最后调用Pager实例的flow函数返回一个flow。
其中PagingConfig构造函数的参数含义为:
pageSize:指定每页加载多少项数据prefetchDistance:预取下一页数据的距离,不能为0,否则不会拉取下一页数据;initialLoadSize:初始加载多少项数据
3.4: PagingDataAdapder:
您还需要设置一个适配器来将数据接收到RecyclerView列表中。为此,Paging 库提供了PagingDataAdapder类。要创建PagingDataAdapder,你需要继承 PagingDataAdapder 类,并实现 onCreateViewHolder 和 onBindViewHolder 方法来创建和绑定数据项的视图。
3.5:显示:
在 Activity 的 onCreate方法 或 Fragment 的 onViewGreated方法中执行以下步骤:
- 创建 PagingDataAdapder类的实例。
- 将PagingDataAdapder 实例传递给您要显示分页数据的 RecyclerView列表。
- 开启协程调用Pager实例返回的PagingData流的collectLatest函数观察 PagingData 流,并将生成的每个值传递给 PagingDataAdapder的submitData方法。
WorkManager:
WorkerManager很适合处理一些要求定时执行的任务,另外,它还支持周期性任务,链式任务处理等等功能。WorkManager和Service并不相同,也没有直接的联系。Service是Android系统的四大组件之一,它在没有被销毁的情况下是一直保持在后台运行的。而WorkManager只是一个处理定时任务的工具,它可以保证即使在应用退出甚至手机重启的情况下、之前注册的任务仍然将会得到执行,因此 WorkManager 很适合用于执行一些定期和服务器进行交互的任务,比如周期性地同步数据,等等。另外,使用WorkManagr注册的周期性任务不能保证一定会准时执行,这并不是bug,而是系统为了减少电量消耗,可能会将触发时间临近的几个任务放在一起执行,这样可以大幅度地减少CPU被唤醒的次数,从而有效延长电池的使用时间。
1.基本用法:
WorkManager的基本用法主要分为以下3步:
- 定义一个后台任务,并实现具体的任务逻辑;
- 配置该后台任务的运行条件和约束信息,并构建后台任务请求;
- 将该后台任务请求传入WorkManager的enqueue()方法中,系统会在合适的时间运行。
1.1:实现:
- 后台任务:新建一个类,继承于Worker类,并且实现它的doWork方法,在这个方法中编写具体的后台任务要执行的逻辑。其中doWork方法不会运行在主线程中,且返回一个result对象,用于表示任务的执行结果。
- 配置该后台任务的运行条件和约束信息,并构建后台任务请求:首先调用OneTimeWorkRequest的Builder方法,插入后台任务对应的class对象,返回一个实例,利用它,配置后台任务的运行条件和约束信息,配置完之后,调用它的build方法完成构建。其中OneTimeWorkRequest.Builder是WorkRequest.Builder的子类,用于构建单次运行的后台任务请求,而WorkRequest.Builder的另一个子类PeriodicWorkRequest.Builder,用于构建周期性运行的后台任务请求。
- 最后就是把后台任务请求传入WorkManager的enqueue()方法中,系统会在合适的时间运行。


















 1961
1961

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











