



此前篇章:
一、相关知识点
为什么要进行平稳性检验?——进行平稳性检验是时间序列分析中的一个重要步骤,主要原因如下:
- 经典统计模型的前提条件:许多经典的时间序列模型(如ARIMA、ARMA等)都假设数据是平稳的。如果数据不平稳,直接应用这些模型可能会导致模型参数估计不准确、预测结果不可靠。
- 避免伪回归:在非平稳时间序列中,即使两个序列之间没有实际关系,也可能表现出显著的相关性,这种现象称为伪回归。例如,如果两个非平稳时间序列都具有相同的趋势,它们可能会表现出很高的相关性,但实际上这种相关性是虚假的。
矩:
- 一阶矩:期望值(E[X]),描述分布的中心,可用于预测和决策。
- 二阶矩:随机变量平方的期望(E[X2]),用于计算方差。
- 二阶中心矩:方差,var(X),衡量离散程度,可用于风险评估和质量控制。
自协方差函数与自相关函数:
- 自协方差函数:衡量时间序列在不同时间点的取值之间的协方差。对于时间序列 {Xt},自协方差函数的定义如下。
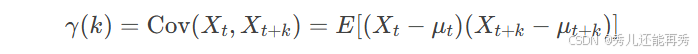
特别的,当k=0时, ,即时间序列的方差。
- 自相关系数(ACF):自协方差函数的标准化形式,用于衡量时间序列在不同时间点的取值之间的线性相关性。定义如下。

自协方差函数、自相关函数的应用:
- 描述时间序列的内部结构:帮助分析时间序列在不同时间点的取值之间的依赖关系。例如,如果 ρ(k) 在某个滞后 k 处显著不为零,说明时间序列在滞后 k 处存在相关性。
- 判断平稳性:对于平稳时间序列,自协方差和自相关只与滞后 k 有关,而与时间 t 无关。
- 模型识别、预测参考。
严平稳:严平稳要求时间序列的所有统计性质在时间平移下保持不变。严平稳的条件非常严格,实际中很难验证严平稳性,因为需要知道整个联合分布。
宽平稳(也叫弱平稳):只要求时间序列的均值和自协方差在时间平移下保持不变。我们在分析时,通常只要求宽平稳,而不是严平稳。
宽平稳的条件,有3个:
- 均值恒定,是一个常数
- 方差恒定
- 自协方差只与时间间隔有关(与滞后k有关,而与t无关)
二、图检验(主观判断)
(一)时序图检验
时序图检验是平稳性检验的一种直观方法,通过绘制时间序列的图形来初步判断其是否平稳。只能靠主观初步判断平稳性。
横轴:时间
纵轴:观测值
判断:
- 均值是否随时间变化(是否存在趋势)
- 方差是否发生随时间变化(是否存在波动性变化)
- 是否存在明显季节性
平稳时的特征:
- 均值恒定:围绕一条水平线波动
- 方差恒定:波动幅度大致相同
- 无明显的趋势或季节性
非平稳时的特征:
- 存在趋势:呈现明显的上升或下降趋势
- 存在季节性:呈现周期性波动
- 方差变化:序列的波动幅度随时间变化
趋势非平稳,图例如下:存在向下递减的趋势,故序列非平稳。
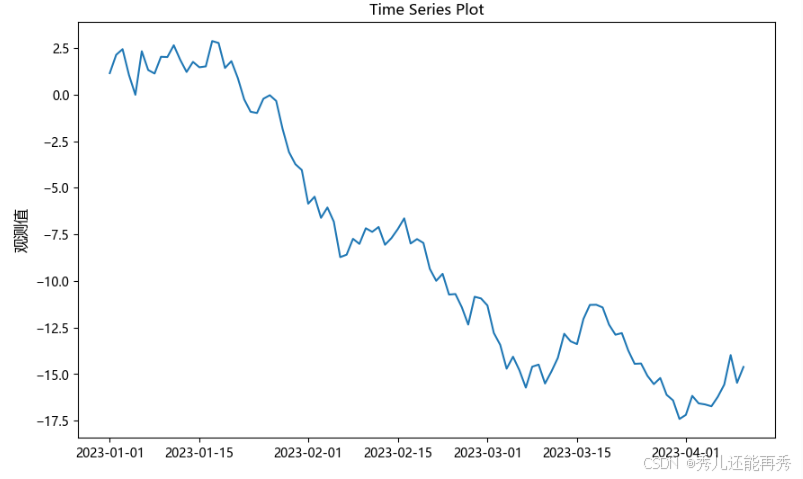
方差非平稳,图例如下:虽然均值大致相同(围绕一条线附近波动),但是波动幅度不一样,随时间推移,波动幅度越大。
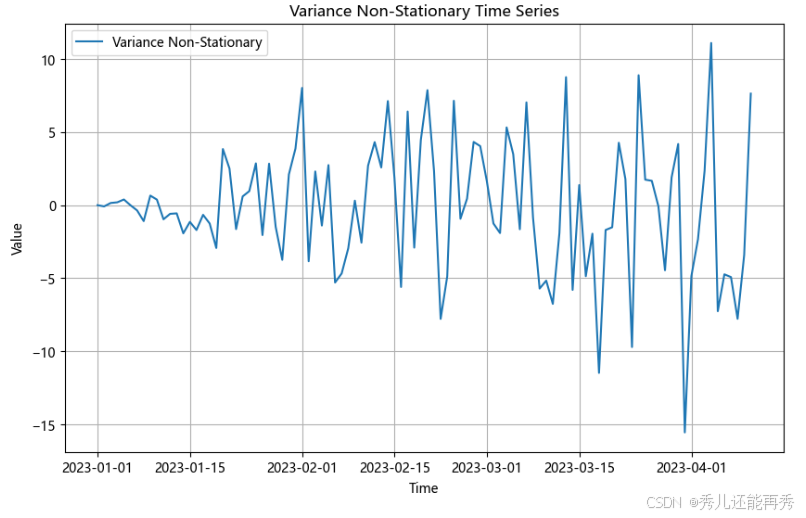
季节性非平稳,图例如下: 均值大致相同,但是在数据在固定间隔(如每月或每两周)呈现周期性波动,数值在特定时间点重复上升或下降。
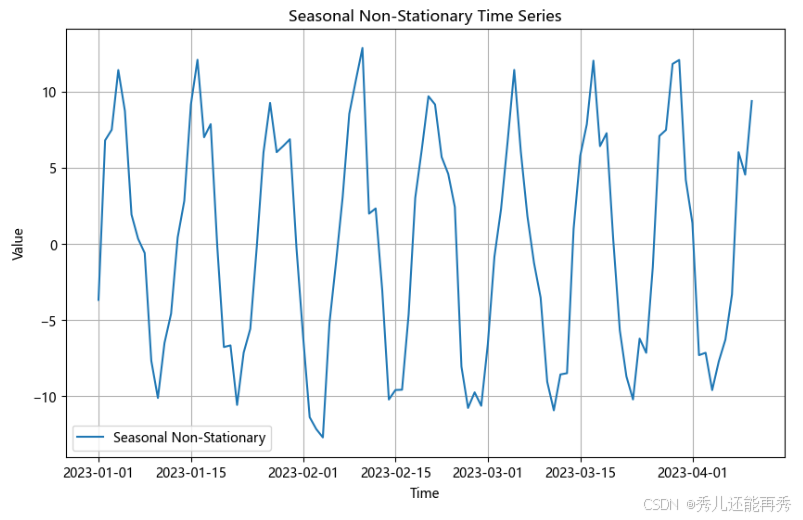
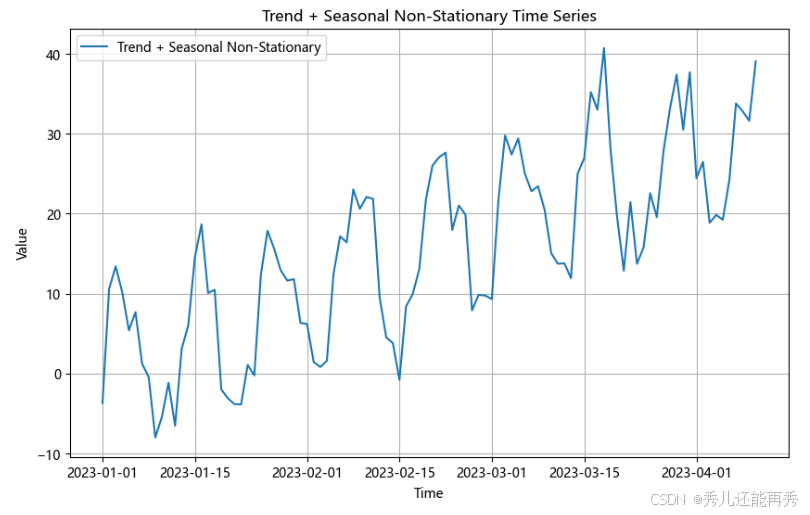
趋势+季节性非平稳,图例如下 :
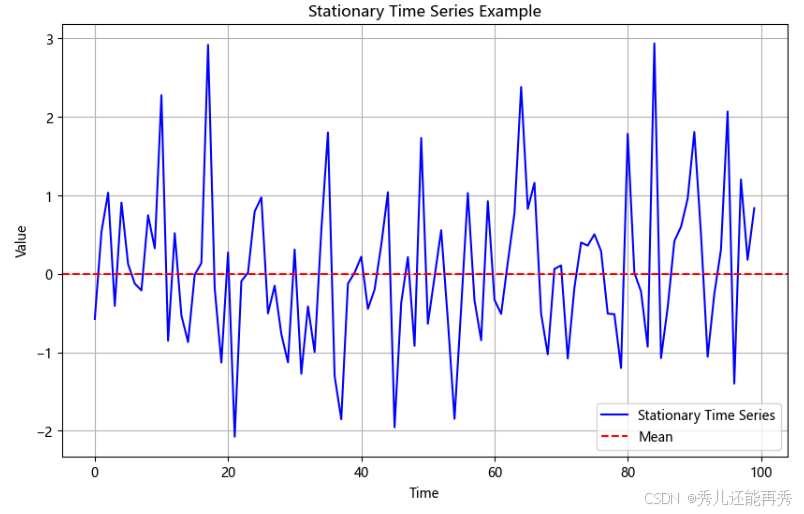
平稳,图例如下:序列大致围绕一条线附近波动,波动幅度大致相同,且不存在明显的上升或下降趋势,也不存在明显的季节性(固定间隔无明显周期性波动,比较杂乱),因此可以初步判断序列是平稳的(但不一定平稳,因为图检验方法是主观判断的)
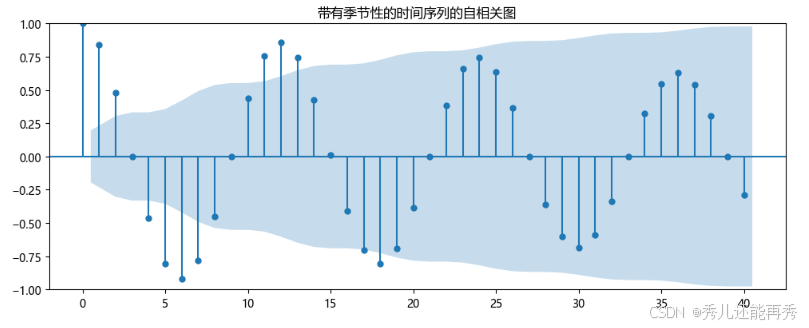
(二)自相关图检验
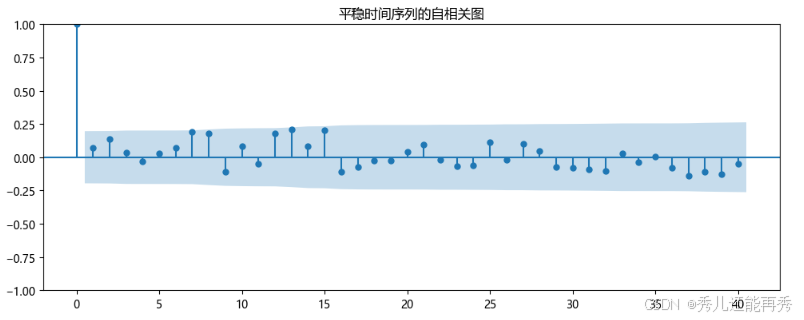
平稳序列:
- 如果时间序列是平稳的,自相关系数通常会迅速衰减,尤其是在较大的滞后期时,相关性趋于零。
- 自相关图显示出大部分自相关系数都位于零附近,且不呈现明显的周期性或趋势。
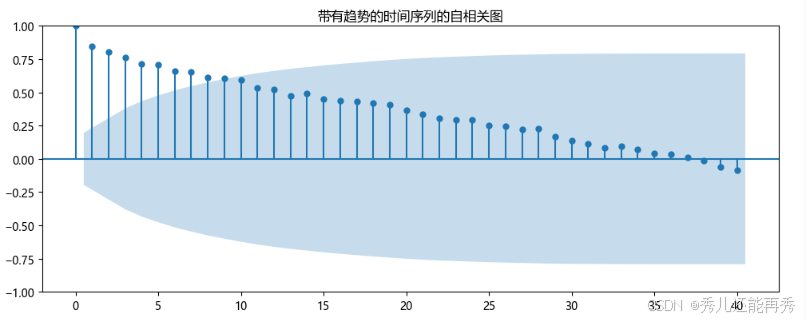
趋势非平稳:
- 如果时间序列是非平稳的,尤其是具有趋势的非平稳序列,自相关系数通常会在较大的滞后期上仍然较高。这表明数据点之间有较强的依赖关系,序列存在较长时间的相关性。
- 在具有趋势的序列中,自相关系数往往在滞后期较长时才逐渐衰减,而不是快速趋近于零。
季节性非平稳:
- 如果时间序列具有季节性,通常会看到自相关图在某些滞后期有显著的峰值。例如,如果数据具有年季节性,自相关系数可能会在12个月的滞后期上出现一个显著的周期性波动。
三、单位跟检验
(一)ADF检验、PP检验
ADF检验是时间序列分析中用于检验平稳性的常用方法,通过构建回归模型来检测单位根,判断序列是否平稳。如果存在单位根,序列是非平稳的;反之,序列是平稳的。
原假设与备择假设:
-
原假设(H₀): 序列存在单位根(非平稳)。
-
备择假设(H₁): 序列不存在单位根(平稳)。
ADF检验根据模型的形式分为三种(简单看看就行):
- 无常数项和趋势项:
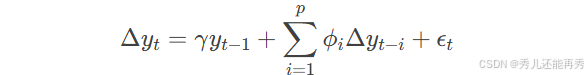
- 有常数项,无趋势项:
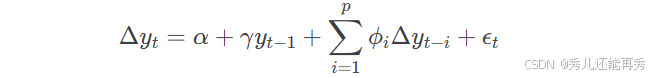
- 有常数项和趋势项:
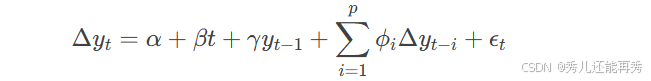
其中:
-
yt:时间序列在时间点 t 的值。
-
Δyt:一阶差分,
。
-
α:常数项(截距)。
-
βt:时间趋势项(可选)。
-
γ:滞后项的系数,用于检验单位根。
-
ϕi:差分滞后项的系数,用于控制序列相关性。
-
ϵt:误差项。
-
p:滞后阶数。
关键步骤:确定滞后阶数(p)。常用信息准则法(如AIC或BIC),选择使信息准则最小的 p;也可以用自相关函数(ACF)和偏自相关函数(PACF),通过观察ACF和PACF图确定滞后阶数。
关键代码(python):
from statsmodels.tsa.stattools import adfuller
result = adfuller(timeseries, autolag='AIC') # 使用AIC自动选择滞后阶数
# 输出p值
p_value = result[1]
# 根据p值,是否拒绝原假设(95%置信度)
if result[1] < 0.05:
print("拒绝原假设:时间序列是平稳的")
else:
print("不可拒绝原假设:时间序列是非平稳的")
局限性:
- 对小样本数据敏感
- 预先假设误差项为正态分布
- 对滞后长度选择敏感(ADF检验需要选择合适的滞后长度)
- 对季节性或周期性数据不敏感:可能无法准确判断具有季节性或周期性的时间序列的平稳性
解决方法:结合其他检验方法,比如KPSS检验、pp检验
PP检验与ADF检验类似,但允许误差项存在自相关和异方差。PP检验通过构建一个包含滞后项和差分的模型,来检验时间序列是否存在单位根。
原假设与备择假设:与ADF检验的假设相同。
关键代码:
from statsmodels.tsa.stattools import adfuller
result = result = pp_test(x) # 使用AIC自动选择滞后阶数
# 输出p值
p_value = result[1]
# 根据p值,是否拒绝原假设(95%置信度)
if result[1] < 0.05:
print("拒绝原假设:时间序列是平稳的")
else:
print("不可拒绝原假设:时间序列是非平稳的")PP检验与ADF检验的适用场景:
-
ADF检验:适用于误差项独立同分布的情况。
-
PP检验:适用于误差项存在自相关或异方差的情况。
(二)KPSS检验
与ADF检验不同,KPSS检验的原假设是时间序列是平稳的,而备择假设是时间序列存在单位根(非平稳),当然检验方法也肯定不同。
原假设与备择假设:
-
原假设(H0):时间序列是平稳的。
-
备择假设(H1):时间序列存在单位根,即非平稳
检验步骤:
-
计算时间序列的累积偏差序列。
-
基于累积偏差计算KPSS统计量。
-
将统计量与临界值进行比较,判断是否拒绝原假设
KPSS检验的类型:
-
水平KPSS检验:检验时间序列是否围绕一个固定水平波动。适用于检测均值平稳性。
-
趋势KPSS检验:检验时间序列是否围绕一个线性趋势波动。适用于检测趋势平稳性。
关键代码:
from statsmodels.tsa.stattools import kpss
# 水平KPSS检验。regression用于选择模型。
result = kpss(series, regression='c') # 'c'表示在KPSS检验中,回归模型包含常数项而无趋势项
print(f"P-Value: {result[1]:.4f}")
# 趋势KPSS检验
result1 = kpss(series, regression='c') # 'c'表示在KPSS检验中,回归模型包含常数项和趋势项
print(f"P-Value: {result1[1]:.4f}")
# 也是根据p值判断是否拒绝原假设要点
在进行平稳性检验时,可以先用图检验方法简单地直观判断,再决定是否要用统计方法检验(ADF检验等),进行更准确的判断,还有就是最好将ADF与KPSS检验结合在一起用,提高判断的准确度。
# 文章如有错误,欢迎大家指正。我们下期再见

















 4811
4811

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









