







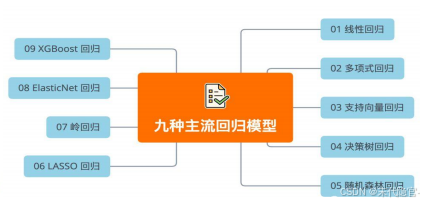
回归
回归的概念
回归分析是指一种预测性的建模技术,主要是研究自变量和因变量的关系。通常使用线/曲线来拟合数据点,然后研究如何使曲线到数据点的距离差异最小。
回归的基本流程
面对一个回归问题,我们可简要描述其求解流程:
① 选定训练模型,即我们为程序选定一个求解框架,如线性回归模型(Linear Regression)等。
② 导入训练集,即给模型提供大量可供学习参考的正确数据。
③ 选择合适的学习算法,通过训练集中大量输入输出结果让程序不断优化输入数据与输出数据间的关联性,从而提升模型的预测准确度。
④ 在训练结束后即可让模型预测结果,我们为程序提供一组新的输入数据,模型根据训练集的学习成果来预测这组输入对应的输出值。
线性回归

基础概念
线性回归就是通过通过训练学习得到一个线性模型来最大限度地根据输入x拟合输出y。线性回归学习的关键在于确定参数w和b,使得拟合输出y和真实输出y'尽可能接近。


最小二乘法(LSM)
基于均方误差最小化求解线性回归参数的常用方法之一。
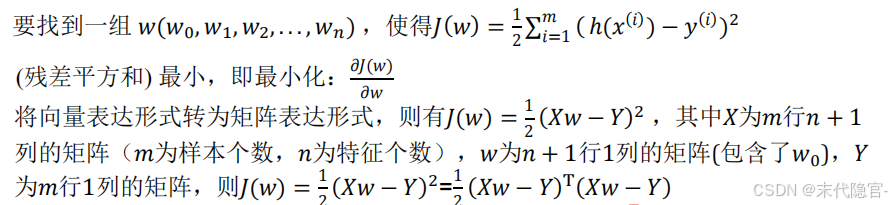


梯度下降法
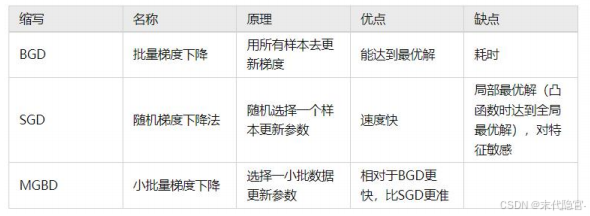
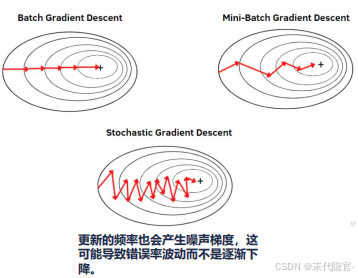
需要注意的是:梯度下降法找到的只是在当前的点的切平面上下降最快的方向。
二者比较,梯度下降法需要选择学习率α,需要多次迭代,当特征数n大时也能较好适用,适用各种类型的模型;最小二乘法需要一次计算![]() 。如果特征数量n较大则运算代价大,同时他只适用于线性模型。
。如果特征数量n较大则运算代价大,同时他只适用于线性模型。
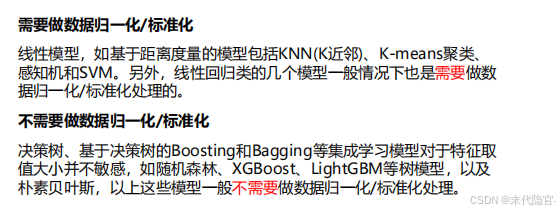
数据归一化/标准化
提升模型精度:不同维度之间的特征在数值上有一定比较性,可以大大提高分类器的准确性。
加速模型收敛:最优解的寻优过程明显会变得平缓,更容易正确的收敛到最优解。
正则化

L1正则化的原则是样本特性是由少数重要特征决定的,因此将不重要的特征系数归零,只考虑重要特征的系数,所以L1正则化会产生稀疏矩阵。这也是L1正则解决过拟合的原因。
L2正则化的原则,降低系数的值,提高模型的泛化性。如果模型在训练集上拟合的很好,且模型参数的值都很小,这样模型就能在各种数据集上具备很好的泛化性。
回归的评价指标
 逻辑回归
逻辑回归

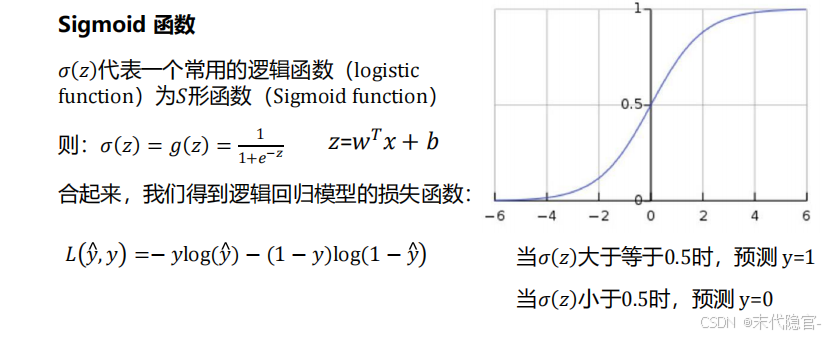
Sigmoid函数

















 4476
4476

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









