






unordered_set、unordered_map、unordered_multiset和unordered_multimap都是C++11才出来的,它们的底层都是哈希桶,所以学习本篇内容前,建议大家先看一下这篇文章 -> 【C++】哈希
unordered_set、unordered_map和unordered_multiset和unordered_multimap的差异就是前者不可以存储相同数据,后者可以存储相同数据,这里的数据指的是Key。
一、unordered_set

学完哈希,我们现在看这些模板参数就非常清晰了,Key就是我们存储数据的类型;Hash就是仿函数,这个仿函数用来将Key转换为无符号整型,因为只有保证Key是无符号整型,才能确保Key有映射位置;Pred也是一个仿函数,这个仿函数用来支持Key比较相等(==)运算,Key的类型必须需要支持比较,这样才能正确查找到正确的位置。unordered_set底层存储数据的内存是从空间配置器申请的,如果需要可以自己实现内存池,传给第四个参数。⼀般情况下,我们在使用时都不需要传后三个模板参数。
unordered_set底层是用哈希桶实现,增删查平均效率是O(1) ,迭代器遍历不再有序,为了跟set
区分,所以取名unordered_set。前面部分我们已经学习了set容器的使用,set和unordered_set的功能高度相似,只是底层结构不同,有⼀些性能和使用的差异。
二、unordered_set和set的使用差异
了解使用差异前,我们要知道unordered_set底层是哈希桶,set的底层是红黑树。
unordered_set的支持增删查(insert、erase、find)且跟set的使用方式一模一样。
//常用的接口
pair<iterator,bool> insert ( const value_type& val );
size_type erase ( const key_type& k );
iterator find ( const key_type& k );unordered_set和set的第一个差异是对Key的要求不同,set要求Key支持小于比较,而unordered_set要求Key支持转成整形且支持等于比较。
unordered_set和set的第⼆个差异是迭代器的差异,set的iterator是双向迭代器(支持++,--),unordered_set的iterator是单向迭代器(只支持++),其次set底层是红黑树,红黑树是⼆叉搜索树,走中序遍历是有序的,所以set迭代器遍历是有序+去重;而unordered_set底层是哈希桶,迭代器遍历是无序+去重。
unordered_set和set的第三个差异是性能的差异,整体而言大多数场景下,unordered_set的增删
查改更快⼀些,因为红黑树增删查改效率是O(logN) ,而哈希表增删查平均效率是O(1) ,具体
可以参看下面代码的演示的对比差异:
#include<unordered_set>
#include<unordered_map>
#include<set>
#include<iostream>
using namespace std;
void test1()
{
const size_t N = 1000000; //100w个数据
unordered_set<int> us;
set<int> s;
vector<int> v;
v.reserve(N);
srand((unsigned)time(0));
for (size_t i = 0; i < N; ++i)
{
//插入100w个数据
//v.push_back(rand()); // N比较大时,重复值比较多
v.push_back(rand() + i); // 重复值相对少
//v.push_back(i); // 没有重复,有序
}
size_t begin1 = clock();
for (auto e : v)
s.insert(e);
size_t end1 = clock();
cout << "set insert:" << end1 - begin1 << endl;
size_t begin2 = clock();
us.reserve(N);
for (auto e : v)
us.insert(e);
size_t end2 = clock();
cout << "unordered_set insert:" << end2 - begin2 << endl;
cout << "--------------------------------------" << endl;
int m1 = 0;
size_t begin3 = clock();
for (auto e : v)
{
auto ret = s.find(e);
if (ret != s.end())
++m1;
}
size_t end3 = clock();
cout << "set find:" << end3 - begin3 << "->" << m1 << endl;
int m2 = 0;
size_t begin4 = clock();
for (auto e : v)
{
auto ret = us.find(e);
if (ret != us.end())
++m2;
}
size_t end4 = clock();
cout << "unorered_set find:" << end4 - begin4 << "->" << m2 << endl;
cout << "--------------------------------------" << endl;
cout << "插入数据个数:" << s.size() << endl;
cout << "插入数据个数:" << us.size() << endl;
cout << "--------------------------------------" << endl;
size_t begin5 = clock();
for (auto e : v)
s.erase(e);
size_t end5 = clock();
cout << "set erase:" << end5 - begin5 << endl;
size_t begin6 = clock();
for(auto e : v)
us.erase(e);
size_t end6 = clock();
cout << "unordered_set erase:" << end6 - begin6 << endl << endl;
}
int main()
{
test1();
return 0;
}
运行结果:
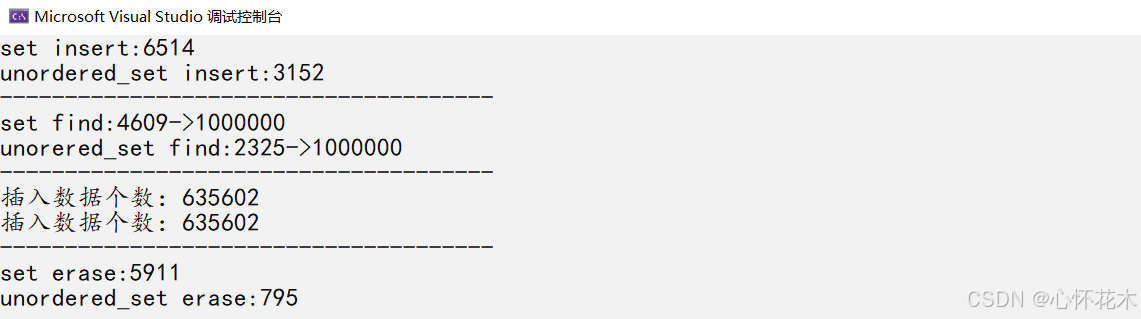
由于哈希桶这种特殊的结构使得unordered_set的insert、find、erase全方面碾压set,set虽然效率也不差但是在unordered_set面前还是抬不起头的。所以我们平时如果能用unordered_set就不用set(前提是你要知道它们两个的区别)。
三、unordered_map

unordered_map的各个参数模板和unordered_set差不多一样,只不过多了一个T,因为unordered_map中的数据类型是pair,所以Key是pair的第一个模板参数,T是pair的第二个模板参数,也就是key/value搜索场景下的value。unordered_map的其它模板参数的作用和unordered_set一模一样,这里就不赘述了。
四、unordered_map和map的使用差异
了解使用差异前,我们要知道unordered_map底层是哈希桶,map的底层是红黑树。
unordered_map的支持增删查改(insert、erase、find)且跟map的使用方式⼀模⼀样。
//常用的接口
pair<iterator,bool> insert ( const value_type& val );
size_type erase ( const key_type& k );
iterator find ( const key_type& k );
mapped_type& operator[] ( const key_type& k );unordered_map和map的第⼀个差异是对Key的要求不同,map要求Key支持小于比较,而
unordered_map要求Key支持转成整形且支持等于比较。
unordered_map和map的第二个差异是迭代器的差异,map的iterator是双向迭代器(支持++,--),
unordered_map是单向迭代器(只支持++),其次map底层是红黑树,红黑树树是⼆叉搜索树,走中序遍历是有序的,所以map迭代器遍历是Key有序+去重。而unordered_map底层是哈希表,迭代器遍历是Key无序+去重。
unordered_map和map的第三个差异是性能的差异,整体而言大多数场景下,unordered_map的
增删查改更快⼀些,因为红黑树增删查改效率是O(logN) ,而哈希表增删查平均效率是O(1) ,
具体可以参看下面代码的演示的对比差异:
void test2()
{
const size_t N = 1000000; //100w个数据
unordered_map<int, int> um;
map<int, int> m;
vector<int> v;
v.reserve(N);
srand((unsigned)time(0));
for (size_t i = 0; i < N; ++i)
{
//插入100w个数据
//v.push_back(rand()); // N比较大时,重复值比较多
v.push_back(rand() + i); // 重复值相对少
//v.push_back(i); // 没有重复,有序
}
size_t begin1 = clock();
for (auto e : v)
m.insert({ e,e });
size_t end1 = clock();
cout << "map insert:" << end1 - begin1 << endl;
size_t begin2 = clock();
um.reserve(N);
for (auto e : v)
um.insert({ e,e });
size_t end2 = clock();
cout << "unordered_map insert:" << end2 - begin2 << endl;
cout << "--------------------------------------" << endl;
int m1 = 0;
size_t begin3 = clock();
for (auto e : v)
{
auto ret = m.find(e);
if (ret != m.end())
++m1;
}
size_t end3 = clock();
cout << "map find:" << end3 - begin3 << "->" << m1 << endl;
int m2 = 0;
size_t begin4 = clock();
for (auto e : v)
{
auto ret = um.find(e);
if (ret != um.end())
++m2;
}
size_t end4 = clock();
cout << "unorered_map find:" << end4 - begin4 << "->" << m2 << endl;
cout << "--------------------------------------" << endl;
cout << "插入数据个数:" << m.size() << endl;
cout << "插入数据个数:" << um.size() << endl;
cout << "--------------------------------------" << endl;
size_t begin5 = clock();
for (auto e : v)
m.erase(e);
size_t end5 = clock();
cout << "map erase:" << end5 - begin5 << endl;
size_t begin6 = clock();
for (auto e : v)
um.erase(e);
size_t end6 = clock();
cout << "unordered_map erase:" << end6 - begin6 << endl << endl;
}
int main()
{
test2();
return 0;
}
运行结果:

由于哈希桶这种特殊的结构使得unordered_map的insert、find、erase全方面碾压map,map虽然效率也不差但是在unordered_map面前还是抬不起头的。所以我们平时如果能用unordered_map就不用map(前提是你要知道它们两个的区别)。
五、unordered_multixxx
unordered_multimap/unordered_multiset跟multimap/multiset功能完全类似,支持Key冗余。
unordered_multimap/unordered_multiset跟multimap/multiset的差异也是三个方面的差异,
Key的要求的差异,iterator遍历顺序的差异,性能的差异。
六、unordered_xxx的哈希相关接口
unordered_xxx与xxx不同的地方在于它有一些相关的哈希方面的接口。Buckets和Hash policy系列的接口分别是跟哈希桶和负载因子相关的接口,日常使用的角度我们不需要太关注。
七、结语
本文主要讲了unordered_set和unordered_map的基本用法,以及它们与set和map的差异点,希望对大家有帮助,祝生活愉快!


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









